Classification of Endoscopy and Video Capsule Images using CNN-Transformer Model

0

Sign in to get full access
Overview
- The paper proposes a CNN-Transformer model for classifying endoscopy and video capsule images.
- The model combines convolutional neural networks (CNNs) and transformer architectures to leverage both spatial and sequential information in the images.
- The model is evaluated on several medical image datasets, demonstrating improved performance compared to existing methods.
Plain English Explanation
The researchers developed a new machine learning model to analyze images from endoscopy and video capsule procedures. Endoscopy and video capsule are medical techniques that allow doctors to examine the digestive system using tiny cameras.
The model uses two key components:
-
Convolutional neural networks (CNNs): These are a type of deep learning algorithm that can effectively process and analyze image data.
-
Transformers: This is another type of deep learning architecture that is particularly good at understanding sequential information, like the order of elements in an image.
By combining these two approaches, the researchers created a model that can take endoscopy and video capsule images, understand both the spatial and sequential patterns in the data, and use that information to classify the images into different medical categories (such as healthy versus diseased tissue).
The researchers tested their model on several medical image datasets and found that it outperformed other state-of-the-art methods. This suggests that the CNN-Transformer approach could be a valuable tool for assisting doctors in analyzing endoscopy and video capsule images and helping with medical diagnosis.
Technical Explanation
The paper introduces a CNN-Transformer model for classifying endoscopy and video capsule images. The model consists of two main components:
-
A CNN-based feature extractor: This takes the input images and extracts spatial features using a convolutional neural network.
-
A Transformer-based classification head: This takes the CNN features and models the sequential relationships between them using a transformer architecture. This allows the model to capture both spatial and sequential information in the images.
The researchers evaluated their model on several medical image datasets, including endoscopy images of the gastrointestinal tract and video capsule images. They compared the performance of the CNN-Transformer model to other state-of-the-art image classification approaches, such as pure CNN models and CNN-RNN (recurrent neural network) hybrids.
The results showed that the CNN-Transformer model achieved superior classification accuracy on the tested datasets. The researchers attribute this to the model's ability to effectively leverage both spatial and sequential information in the images, which is particularly relevant for medical imaging tasks.
Critical Analysis
The paper provides a promising approach for classifying endoscopy and video capsule images using a CNN-Transformer model. The researchers demonstrate strong performance on several medical imaging datasets, suggesting the potential of this technique for assisting doctors in analyzing and diagnosing medical conditions.
However, the paper does not address certain limitations and potential issues:
-
The researchers only evaluate the model on a limited number of datasets. More extensive testing on a wider range of endoscopy and video capsule image data would be needed to fully assess the model's generalizability.
-
The paper does not provide much insight into the specific types of features or patterns the model is learning to distinguish different medical conditions. A more in-depth analysis of the model's internal workings could help understand its decision-making process and identify potential biases or limitations.
-
The paper does not discuss the computational complexity and inference speed of the CNN-Transformer model, which could be important considerations for real-world medical applications where fast and efficient analysis is crucial.
-
The ethical implications of deploying such AI-powered image classification systems in a medical context are not addressed. Careful consideration of issues like data privacy, algorithmic bias, and the role of human clinicians in the decision-making process would be important.
Overall, the research demonstrates a promising technical approach, but further investigation and validation would be needed to fully assess its practical applicability and ensure responsible development and deployment of the technology.
Conclusion
The paper presents a CNN-Transformer model for classifying endoscopy and video capsule images, leveraging both spatial and sequential information to achieve improved performance compared to existing methods. The model's strong results on several medical imaging datasets suggest its potential as a tool to assist doctors in analyzing and diagnosing medical conditions from endoscopy and video capsule data.
However, the research also highlights the need for more extensive testing, deeper analysis of the model's internal workings, and careful consideration of the practical and ethical implications of deploying such AI-powered systems in a medical context. Ongoing research and collaboration between machine learning experts and medical professionals will be crucial for responsibly developing and deploying these technologies to benefit patient care.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Classification of Endoscopy and Video Capsule Images using CNN-Transformer Model
Aliza Subedi, Smriti Regmi, Nisha Regmi, Bhumi Bhusal, Ulas Bagci, Debesh Jha
Gastrointestinal cancer is a leading cause of cancer-related incidence and death, making it crucial to develop novel computer-aided diagnosis systems for early detection and enhanced treatment. Traditional approaches rely on the expertise of gastroenterologists to identify diseases; however, this process is subjective, and interpretation can vary even among expert clinicians. Considering recent advancements in classifying gastrointestinal anomalies and landmarks in endoscopic and video capsule endoscopy images, this study proposes a hybrid model that combines the advantages of Transformers and Convolutional Neural Networks (CNNs) to enhance classification performance. Our model utilizes DenseNet201 as a CNN branch to extract local features and integrates a Swin Transformer branch for global feature understanding, combining both to perform the classification task. For the GastroVision dataset, our proposed model demonstrates excellent performance with Precision, Recall, F1 score, Accuracy, and Matthews Correlation Coefficient (MCC) of 0.8320, 0.8386, 0.8324, 0.8386, and 0.8191, respectively, showcasing its robustness against class imbalance and surpassing other CNNs as well as the Swin Transformer model. Similarly, for the Kvasir-Capsule, a large video capsule endoscopy dataset, our model outperforms all others, achieving overall Precision, Recall, F1 score, Accuracy, and MCC of 0.7007, 0.7239, 0.6900, 0.7239, and 0.3871. Moreover, we generated saliency maps to explain our model's focus areas, demonstrating its reliable decision-making process. The results underscore the potential of our hybrid CNN-Transformer model in aiding the early and accurate detection of gastrointestinal (GI) anomalies.
Read more8/21/2024
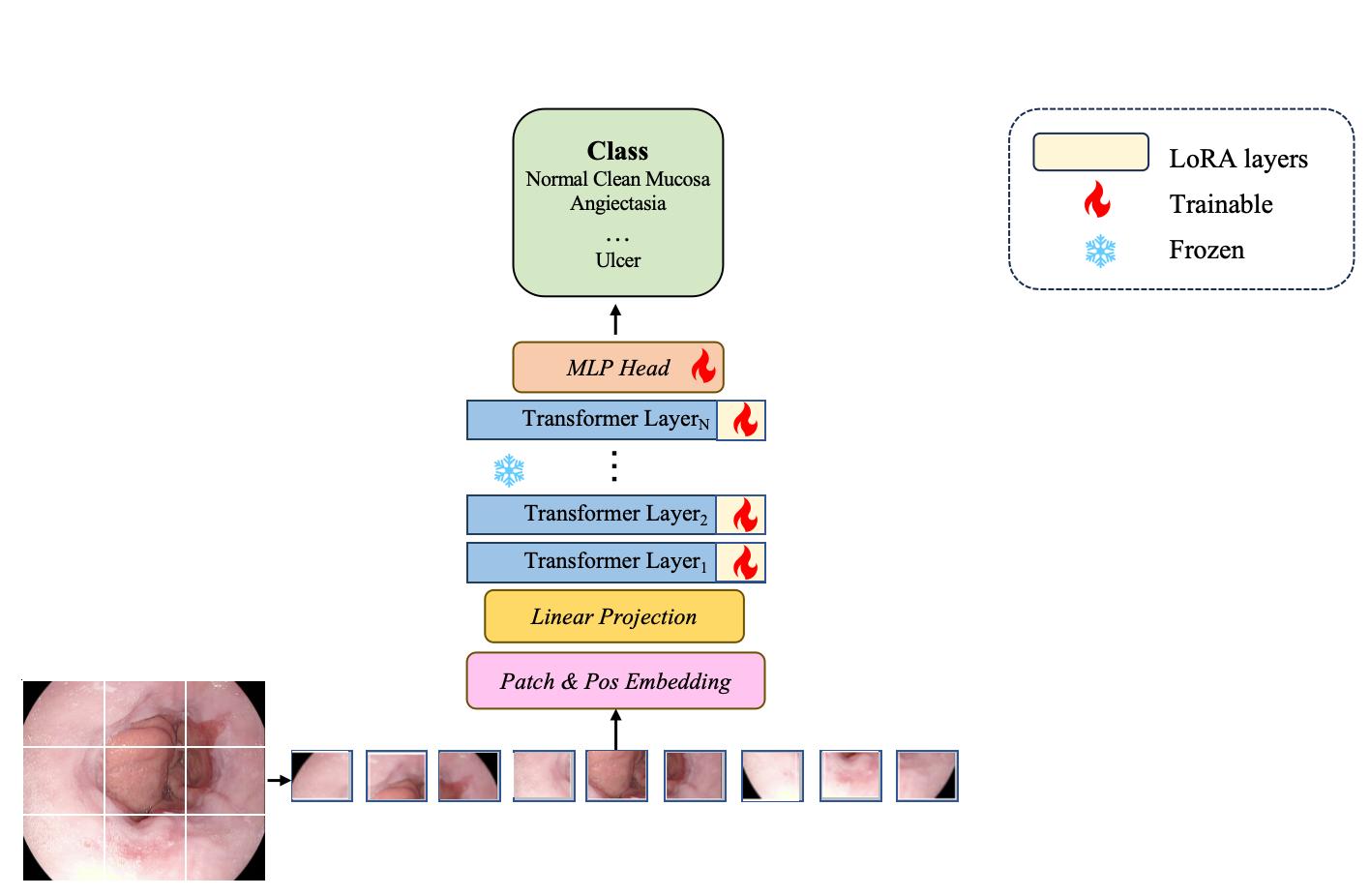
0
Learning to Adapt Foundation Model DINOv2 for Capsule Endoscopy Diagnosis
Bowen Zhang, Ying Chen, Long Bai, Yan Zhao, Yuxiang Sun, Yixuan Yuan, Jianhua Zhang, Hongliang Ren
Foundation models have become prominent in computer vision, achieving notable success in various tasks. However, their effectiveness largely depends on pre-training with extensive datasets. Applying foundation models directly to small datasets of capsule endoscopy images from scratch is challenging. Pre-training on broad, general vision datasets is crucial for successfully fine-tuning our model for specific tasks. In this work, we introduce a simplified approach called Adapt foundation models with a low-rank adaptation (LoRA) technique for easier customization. Our method, inspired by the DINOv2 foundation model, applies low-rank adaptation learning to tailor foundation models for capsule endoscopy diagnosis effectively. Unlike traditional fine-tuning methods, our strategy includes LoRA layers designed to absorb specific surgical domain knowledge. During the training process, we keep the main model (the backbone encoder) fixed and focus on optimizing the LoRA layers and the disease classification component. We tested our method on two publicly available datasets for capsule endoscopy disease classification. The results were impressive, with our model achieving 97.75% accuracy on the Kvasir-Capsule dataset and 98.81% on the Kvasirv2 dataset. Our solution demonstrates that foundation models can be adeptly adapted for capsule endoscopy diagnosis, highlighting that mere reliance on straightforward fine-tuning or pre-trained models from general computer vision tasks is inadequate for such specific applications.
Read more7/2/2024

0
3D Reconstruction of the Human Colon from Capsule Endoscope Video
P{aa}l Anders Floor, Ivar Farup, Marius Pedersen
As the number of people affected by diseases in the gastrointestinal system is ever-increasing, a higher demand on preventive screening is inevitable. This will significantly increase the workload on gastroenterologists. To help reduce the workload, tools from computer vision may be helpful. In this paper, we investigate the possibility of constructing 3D models of whole sections of the human colon using image sequences from wireless capsule endoscope video, providing enhanced viewing for gastroenterologists. As capsule endoscope images contain distortion and artifacts non-ideal for many 3D reconstruction algorithms, the problem is challenging. However, recent developments of virtual graphics-based models of the human gastrointestinal system, where distortion and artifacts can be enabled or disabled, makes it possible to ``dissect'' the problem. The graphical model also provides a ground truth, enabling computation of geometric distortion introduced by the 3D reconstruction method. In this paper, most distortions and artifacts are left out to determine if it is feasible to reconstruct whole sections of the human gastrointestinal system by existing methods. We demonstrate that 3D reconstruction is possible using simultaneous localization and mapping. Further, to reconstruct the gastrointestinal wall surface from resulting point clouds, varying greatly in density, Poisson surface reconstruction is a good option. The results are promising, encouraging further research on this problem.
Read more7/23/2024

0
Deep learning classifier of locally advanced rectal cancer treatment response from endoscopy images
Jorge Tapias Gomez, Aneesh Rangnekar, Hannah Williams, Hannah Thompson, Julio Garcia-Aguilar, Joshua Jesse Smith, Harini Veeraraghavan
Endoscopic images are used at various stages of rectal cancer treatment starting from cancer screening, diagnosis, during treatment to assess response and toxicity from treatments such as colitis, and at follow up to detect new tumor or local regrowth (LR). However, subjective assessment is highly variable and can underestimate the degree of response in some patients, subjecting them to unnecessary surgery, or overestimate response that places patients at risk of disease spread. Advances in deep learning has shown the ability to produce consistent and objective response assessment for endoscopic images. However, methods for detecting cancers, regrowth, and monitoring response during the entire course of patient treatment and follow-up are lacking. This is because, automated diagnosis and rectal cancer response assessment requires methods that are robust to inherent imaging illumination variations and confounding conditions (blood, scope, blurring) present in endoscopy images as well as changes to the normal lumen and tumor during treatment. Hence, a hierarchical shifted window (Swin) transformer was trained to distinguish rectal cancer from normal lumen using endoscopy images. Swin as well as two convolutional (ResNet-50, WideResNet-50), and vision transformer (ViT) models were trained and evaluated on follow-up longitudinal images to detect LR on private dataset as well as on out-of-distribution (OOD) public colonoscopy datasets to detect pre/non-cancerous polyps. Color shifts were applied using optimal transport to simulate distribution shifts. Swin and ResNet models were similarly accurate in the in-distribution dataset. Swin was more accurate than other methods (follow-up: 0.84, OOD: 0.83) even when subject to color shifts (follow-up: 0.83, OOD: 0.87), indicating capability to provide robust performance for longitudinal cancer assessment.
Read more8/27/2024