Learning to Adapt Foundation Model DINOv2 for Capsule Endoscopy Diagnosis

0
Sign in to get full access
Overview
- This paper discusses an approach to adapt a foundation model called DINOv2 for the task of capsule endoscopy diagnosis.
- Capsule endoscopy is a medical procedure where a patient swallows a small camera capsule to capture images of the gastrointestinal tract.
- The researchers aimed to leverage the capabilities of the pre-trained DINOv2 model to improve the performance of capsule endoscopy diagnosis.
Plain English Explanation
In the field of medical imaging, researchers are constantly exploring ways to utilize powerful machine learning models to assist with diagnosis and analysis tasks. One such task is capsule endoscopy, where a patient swallows a small camera capsule that captures images of their gastrointestinal tract as it travels through the body.
The researchers in this paper focused on adapting a pre-trained machine learning model called DINOv2 to work well for capsule endoscopy diagnosis. DINOv2 is a Foundation Model, a type of model that has been trained on a vast amount of general data and can be efficiently fine-tuned for specific tasks.
The researchers wanted to see if they could leverage the capabilities of DINOv2 to improve the accuracy and performance of capsule endoscopy diagnosis, which can be a challenging task due to the large number of images and the complexity of the gastrointestinal tract. By adapting the DINOv2 model to this specific medical task, they aimed to create a more powerful and efficient tool for doctors and medical professionals.
Technical Explanation
The researchers in this paper adapted the DINOv2 foundation model for the task of capsule endoscopy diagnosis. DINOv2 is a self-supervised learning model that has been pre-trained on a large amount of general image data, allowing it to learn powerful visual representations that can be fine-tuned for specific tasks.
To adapt DINOv2 for capsule endoscopy, the researchers first pre-trained the model on a novel benchmark dataset of capsule endoscopy images. This helped the model learn the relevant visual features and characteristics of the gastrointestinal tract and the various pathologies that can be observed in capsule endoscopy.
The researchers then fine-tuned the pre-trained DINOv2 model on a high-quality dataset of capsule endoscopy images, further optimizing the model's performance for this specific task. They also experimented with different fine-tuning strategies and architectural modifications to the DINOv2 model to improve its effectiveness.
Through their experiments, the researchers demonstrated that the adapted DINOv2 model outperformed other state-of-the-art approaches for capsule endoscopy diagnosis. This suggests that leveraging the capabilities of foundation models like DINOv2 can be a powerful strategy for improving medical imaging tasks, especially when working with specialized datasets or complex medical domains.
Critical Analysis
The researchers in this paper have presented a novel approach to adapting a powerful foundation model, DINOv2, for the specific task of capsule endoscopy diagnosis. This is a promising direction, as foundation models have shown great potential for efficiently transferring learning to various domains and tasks.
One potential limitation of the study is the size and diversity of the dataset used for fine-tuning the DINOv2 model. While the researchers used a high-quality dataset, it's unclear how well the adapted model would perform on a more diverse set of capsule endoscopy images, such as those captured in different clinical settings or with varying image quality.
Additionally, the researchers did not provide a detailed analysis of the specific types of pathologies or abnormalities the adapted DINOv2 model was able to detect with high accuracy. Understanding the model's strengths and weaknesses in identifying different medical conditions would be valuable for assessing its practical utility in clinical settings.
Overall, this paper presents an interesting and potentially impactful approach to leveraging foundation models for medical imaging tasks. However, further research and validation on larger and more diverse datasets would be necessary to fully evaluate the capabilities and limitations of this technique.
Conclusion
The researchers in this paper have demonstrated a successful approach to adapting the DINOv2 foundation model for the task of capsule endoscopy diagnosis. By pre-training DINOv2 on a specialized dataset of capsule endoscopy images and then fine-tuning the model, they were able to create a powerful tool for assisting medical professionals in analyzing and interpreting these complex images.
This work highlights the potential of foundation models to significantly improve the performance of medical imaging tasks, especially when dealing with specialized and data-limited domains. As the field of medical AI continues to evolve, leveraging the capabilities of these versatile models could lead to more accurate, efficient, and accessible diagnostic tools for a wide range of medical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning to Adapt Foundation Model DINOv2 for Capsule Endoscopy Diagnosis
Bowen Zhang, Ying Chen, Long Bai, Yan Zhao, Yuxiang Sun, Yixuan Yuan, Jianhua Zhang, Hongliang Ren
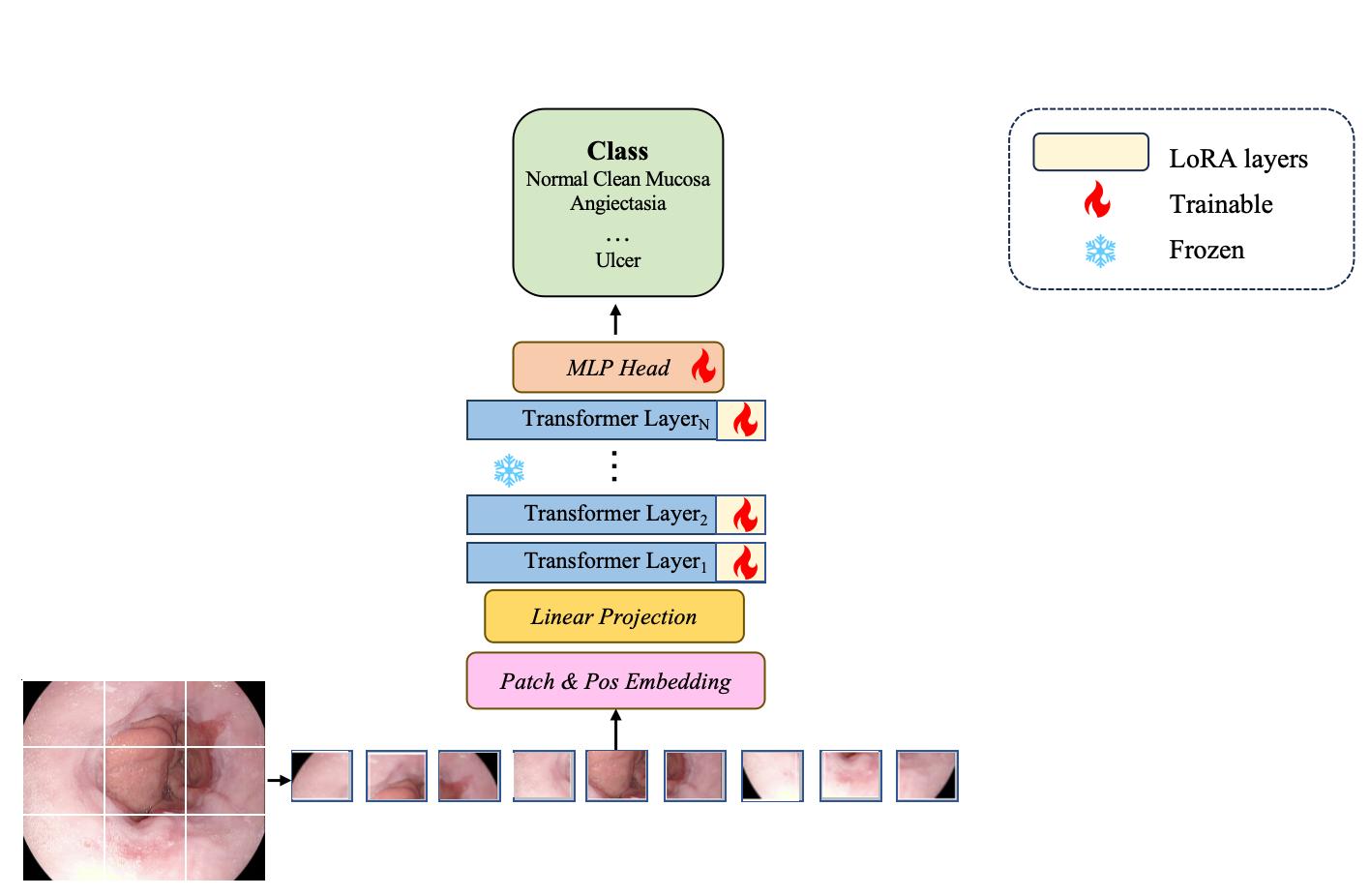
Foundation models have become prominent in computer vision, achieving notable success in various tasks. However, their effectiveness largely depends on pre-training with extensive datasets. Applying foundation models directly to small datasets of capsule endoscopy images from scratch is challenging. Pre-training on broad, general vision datasets is crucial for successfully fine-tuning our model for specific tasks. In this work, we introduce a simplified approach called Adapt foundation models with a low-rank adaptation (LoRA) technique for easier customization. Our method, inspired by the DINOv2 foundation model, applies low-rank adaptation learning to tailor foundation models for capsule endoscopy diagnosis effectively. Unlike traditional fine-tuning methods, our strategy includes LoRA layers designed to absorb specific surgical domain knowledge. During the training process, we keep the main model (the backbone encoder) fixed and focus on optimizing the LoRA layers and the disease classification component. We tested our method on two publicly available datasets for capsule endoscopy disease classification. The results were impressive, with our model achieving 97.75% accuracy on the Kvasir-Capsule dataset and 98.81% on the Kvasirv2 dataset. Our solution demonstrates that foundation models can be adeptly adapted for capsule endoscopy diagnosis, highlighting that mere reliance on straightforward fine-tuning or pre-trained models from general computer vision tasks is inadequate for such specific applications.
Read more7/2/2024
0
EndoDAC: Efficient Adapting Foundation Model for Self-Supervised Depth Estimation from Any Endoscopic Camera
Beilei Cui, Mobarakol Islam, Long Bai, An Wang, Hongliang Ren
Depth estimation plays a crucial role in various tasks within endoscopic surgery, including navigation, surface reconstruction, and augmented reality visualization. Despite the significant achievements of foundation models in vision tasks, including depth estimation, their direct application to the medical domain often results in suboptimal performance. This highlights the need for efficient adaptation methods to adapt these models to endoscopic depth estimation. We propose Endoscopic Depth Any Camera (EndoDAC) which is an efficient self-supervised depth estimation framework that adapts foundation models to endoscopic scenes. Specifically, we develop the Dynamic Vector-Based Low-Rank Adaptation (DV-LoRA) and employ Convolutional Neck blocks to tailor the foundational model to the surgical domain, utilizing remarkably few trainable parameters. Given that camera information is not always accessible, we also introduce a self-supervised adaptation strategy that estimates camera intrinsics using the pose encoder. Our framework is capable of being trained solely on monocular surgical videos from any camera, ensuring minimal training costs. Experiments demonstrate that our approach obtains superior performance even with fewer training epochs and unaware of the ground truth camera intrinsics. Code is available at https://github.com/BeileiCui/EndoDAC.
Read more5/15/2024

0
Classification of Endoscopy and Video Capsule Images using CNN-Transformer Model
Aliza Subedi, Smriti Regmi, Nisha Regmi, Bhumi Bhusal, Ulas Bagci, Debesh Jha
Gastrointestinal cancer is a leading cause of cancer-related incidence and death, making it crucial to develop novel computer-aided diagnosis systems for early detection and enhanced treatment. Traditional approaches rely on the expertise of gastroenterologists to identify diseases; however, this process is subjective, and interpretation can vary even among expert clinicians. Considering recent advancements in classifying gastrointestinal anomalies and landmarks in endoscopic and video capsule endoscopy images, this study proposes a hybrid model that combines the advantages of Transformers and Convolutional Neural Networks (CNNs) to enhance classification performance. Our model utilizes DenseNet201 as a CNN branch to extract local features and integrates a Swin Transformer branch for global feature understanding, combining both to perform the classification task. For the GastroVision dataset, our proposed model demonstrates excellent performance with Precision, Recall, F1 score, Accuracy, and Matthews Correlation Coefficient (MCC) of 0.8320, 0.8386, 0.8324, 0.8386, and 0.8191, respectively, showcasing its robustness against class imbalance and surpassing other CNNs as well as the Swin Transformer model. Similarly, for the Kvasir-Capsule, a large video capsule endoscopy dataset, our model outperforms all others, achieving overall Precision, Recall, F1 score, Accuracy, and MCC of 0.7007, 0.7239, 0.6900, 0.7239, and 0.3871. Moreover, we generated saliency maps to explain our model's focus areas, demonstrating its reliable decision-making process. The results underscore the potential of our hybrid CNN-Transformer model in aiding the early and accurate detection of gastrointestinal (GI) anomalies.
Read more8/21/2024
0
Text-guided Foundation Model Adaptation for Long-Tailed Medical Image Classification
Sirui Li, Li Lin, Yijin Huang, Pujin Cheng, Xiaoying Tang
In medical contexts, the imbalanced data distribution in long-tailed datasets, due to scarce labels for rare diseases, greatly impairs the diagnostic accuracy of deep learning models. Recent multimodal text-image supervised foundation models offer new solutions to data scarcity through effective representation learning. However, their limited medical-specific pretraining hinders their performance in medical image classification relative to natural images. To address this issue, we propose a novel Text-guided Foundation model Adaptation for Long-Tailed medical image classification (TFA-LT). We adopt a two-stage training strategy, integrating representations from the foundation model using just two linear adapters and a single ensembler for balanced outcomes. Experimental results on two long-tailed medical image datasets validate the simplicity, lightweight and efficiency of our approach: requiring only 6.1% GPU memory usage of the current best-performing algorithm, our method achieves an accuracy improvement of up to 27.1%, highlighting the substantial potential of foundation model adaptation in this area.
Read more8/28/2024