CLAY: A Controllable Large-scale Generative Model for Creating High-quality 3D Assets

0

Sign in to get full access
Overview
- CLAY is a large-scale generative model that can create high-quality 3D assets with controllable features.
- The model uses a Diffusion Transformer architecture to generate 3D meshes, textures, and physically-based materials.
- CLAY allows users to control various aspects of the generated 3D assets, such as shape, color, and material properties.
- The researchers demonstrate CLAY's capabilities in creating a diverse range of 3D objects, from furniture to vehicles, and evaluate its performance on various benchmarks.
Plain English Explanation
CLAY is a powerful AI system that can generate detailed 3D objects, such as furniture, vehicles, and other items. Unlike many existing 3D modeling tools, which can be complex and time-consuming to use, CLAY makes it easy to create high-quality 3D assets with just a few simple inputs.
The key innovation in CLAY is its use of a "Diffusion Transformer" - a type of machine learning model that can learn to generate 3D data from examples. By training on a large dataset of 3D models, CLAY has developed a deep understanding of how to create realistic and visually appealing 3D objects.
What makes CLAY really special is that it allows users to control various aspects of the generated 3D assets. For example, you can tell CLAY to create a chair with a specific shape, color, and material texture. Or you can ask it to generate a car with particular design features. This level of control is a significant advancement over previous 3D generation systems, which often produced more generic or randomized outputs.
The researchers behind CLAY have demonstrated its capabilities across a wide range of 3D object categories, showing that it can create diverse and high-quality assets. They've also evaluated CLAY's performance on various benchmarks, comparing it to other state-of-the-art 3D generation models.
Overall, CLAY represents an exciting step forward in the field of 3D asset creation. By making the process more intuitive and controllable, it has the potential to empower a wide range of users, from artists and designers to hobbyists and professionals, to bring their 3D ideas to life more easily.
Technical Explanation
The researchers present CLAY, a large-scale generative model for creating high-quality 3D assets with multi-modal control. The model uses a Diffusion Transformer architecture to generate 3D meshes, textures, and physically-based materials.
One of the key innovations of CLAY is its ability to allow users to control various aspects of the generated 3D assets, such as shape, color, and material properties. This is achieved through the use of a multi-modal input, which combines textual descriptions, sketches, and other modalities to guide the generation process.
The researchers demonstrate CLAY's capabilities across a wide range of 3D object categories, from furniture to vehicles, and evaluate its performance on various benchmarks. They show that CLAY outperforms existing state-of-the-art 3D generation models, such as COIN3D, DIRECT3D, and Interactive3D, in terms of both visual quality and controllability.
The researchers also discuss the potential limitations of CLAY, such as the need for further improvements in the physical realism of the generated assets, and the challenges of scaling the model to even larger and more diverse datasets. They suggest that future work could explore ways to further enhance the model's capabilities, such as by incorporating interactive feedback loops or by exploring alternative architectural designs.
Critical Analysis
The researchers present a compelling approach to 3D asset generation with CLAY, demonstrating its ability to create high-quality and controllable 3D objects. The use of a Diffusion Transformer architecture, combined with the multi-modal control system, is a novel and promising direction for the field of 3D content creation.
One potential area for further exploration is the extent to which CLAY can truly capture the nuances of physical realism. While the researchers show impressive results, there may be opportunities to further improve the model's understanding of material properties, lighting, and other physical phenomena to create even more realistic and immersive 3D assets.
Additionally, the researchers acknowledge the need to scale CLAY to even larger and more diverse datasets. As the model is trained on more data, it may be able to generate an even wider range of 3D objects with greater fidelity and control. However, this scaling process could also introduce new challenges, such as increased model complexity and computational requirements.
Overall, CLAY represents a significant advancement in the field of 3D asset generation, and the researchers have demonstrated its potential through a rigorous evaluation. As the field of generative AI continues to evolve, it will be interesting to see how CLAY and similar approaches can be further refined and deployed to empower a wide range of users in creating high-quality 3D content.
Conclusion
CLAY is a groundbreaking large-scale generative model that can create high-quality 3D assets with unprecedented levels of control and customization. By leveraging a Diffusion Transformer architecture and a multi-modal input system, the model allows users to guide the generation process and produce 3D objects tailored to their specific needs and preferences.
The researchers have demonstrated CLAY's versatility across a wide range of 3D object categories, showcasing its ability to generate detailed and visually appealing assets. The model's performance on various benchmarks suggests that it represents a significant advancement in the field of 3D content creation, potentially empowering a diverse range of users, from artists and designers to hobbyists and professionals.
While CLAY has shown impressive results, the researchers acknowledge the need for further improvements, particularly in enhancing the physical realism of the generated assets and scaling the model to even larger and more diverse datasets. As the field of generative AI continues to evolve, CLAY and similar approaches hold great promise in revolutionizing the way we create and interact with 3D content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CLAY: A Controllable Large-scale Generative Model for Creating High-quality 3D Assets
Longwen Zhang, Ziyu Wang, Qixuan Zhang, Qiwei Qiu, Anqi Pang, Haoran Jiang, Wei Yang, Lan Xu, Jingyi Yu
In the realm of digital creativity, our potential to craft intricate 3D worlds from imagination is often hampered by the limitations of existing digital tools, which demand extensive expertise and efforts. To narrow this disparity, we introduce CLAY, a 3D geometry and material generator designed to effortlessly transform human imagination into intricate 3D digital structures. CLAY supports classic text or image inputs as well as 3D-aware controls from diverse primitives (multi-view images, voxels, bounding boxes, point clouds, implicit representations, etc). At its core is a large-scale generative model composed of a multi-resolution Variational Autoencoder (VAE) and a minimalistic latent Diffusion Transformer (DiT), to extract rich 3D priors directly from a diverse range of 3D geometries. Specifically, it adopts neural fields to represent continuous and complete surfaces and uses a geometry generative module with pure transformer blocks in latent space. We present a progressive training scheme to train CLAY on an ultra large 3D model dataset obtained through a carefully designed processing pipeline, resulting in a 3D native geometry generator with 1.5 billion parameters. For appearance generation, CLAY sets out to produce physically-based rendering (PBR) textures by employing a multi-view material diffusion model that can generate 2K resolution textures with diffuse, roughness, and metallic modalities. We demonstrate using CLAY for a range of controllable 3D asset creations, from sketchy conceptual designs to production ready assets with intricate details. Even first time users can easily use CLAY to bring their vivid 3D imaginations to life, unleashing unlimited creativity.
Read more6/21/2024

0
Coin3D: Controllable and Interactive 3D Assets Generation with Proxy-Guided Conditioning
Wenqi Dong, Bangbang Yang, Lin Ma, Xiao Liu, Liyuan Cui, Hujun Bao, Yuewen Ma, Zhaopeng Cui
As humans, we aspire to create media content that is both freely willed and readily controlled. Thanks to the prominent development of generative techniques, we now can easily utilize 2D diffusion methods to synthesize images controlled by raw sketch or designated human poses, and even progressively edit/regenerate local regions with masked inpainting. However, similar workflows in 3D modeling tasks are still unavailable due to the lack of controllability and efficiency in 3D generation. In this paper, we present a novel controllable and interactive 3D assets modeling framework, named Coin3D. Coin3D allows users to control the 3D generation using a coarse geometry proxy assembled from basic shapes, and introduces an interactive generation workflow to support seamless local part editing while delivering responsive 3D object previewing within a few seconds. To this end, we develop several techniques, including the 3D adapter that applies volumetric coarse shape control to the diffusion model, proxy-bounded editing strategy for precise part editing, progressive volume cache to support responsive preview, and volume-SDS to ensure consistent mesh reconstruction. Extensive experiments of interactive generation and editing on diverse shape proxies demonstrate that our method achieves superior controllability and flexibility in the 3D assets generation task.
Read more5/15/2024
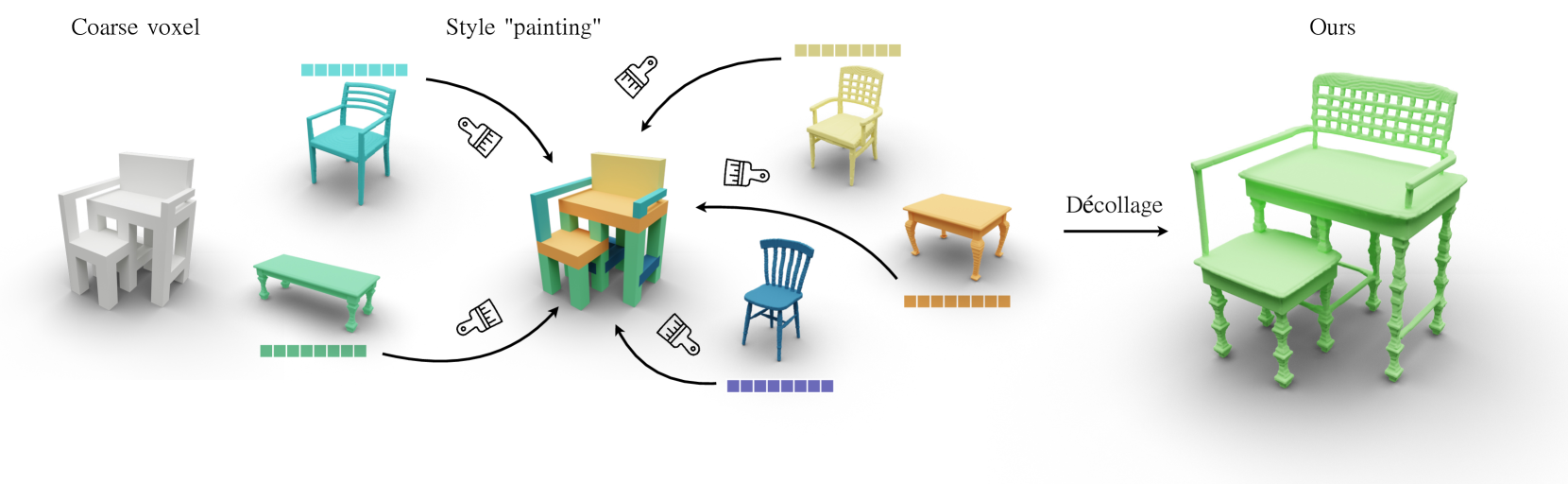
0
DECOLLAGE: 3D Detailization by Controllable, Localized, and Learned Geometry Enhancement
Qimin Chen, Zhiqin Chen, Vladimir G. Kim, Noam Aigerman, Hao Zhang, Siddhartha Chaudhuri
We present a 3D modeling method which enables end-users to refine or detailize 3D shapes using machine learning, expanding the capabilities of AI-assisted 3D content creation. Given a coarse voxel shape (e.g., one produced with a simple box extrusion tool or via generative modeling), a user can directly paint desired target styles representing compelling geometric details, from input exemplar shapes, over different regions of the coarse shape. These regions are then up-sampled into high-resolution geometries which adhere with the painted styles. To achieve such controllable and localized 3D detailization, we build on top of a Pyramid GAN by making it masking-aware. We devise novel structural losses and priors to ensure that our method preserves both desired coarse structures and fine-grained features even if the painted styles are borrowed from diverse sources, e.g., different semantic parts and even different shape categories. Through extensive experiments, we show that our ability to localize details enables novel interactive creative workflows and applications. Our experiments further demonstrate that in comparison to prior techniques built on global detailization, our method generates structure-preserving, high-resolution stylized geometries with more coherent shape details and style transitions.
Read more9/11/2024
🛸
0
Direct3D: Scalable Image-to-3D Generation via 3D Latent Diffusion Transformer
Shuang Wu, Youtian Lin, Feihu Zhang, Yifei Zeng, Jingxi Xu, Philip Torr, Xun Cao, Yao Yao
Generating high-quality 3D assets from text and images has long been challenging, primarily due to the absence of scalable 3D representations capable of capturing intricate geometry distributions. In this work, we introduce Direct3D, a native 3D generative model scalable to in-the-wild input images, without requiring a multiview diffusion model or SDS optimization. Our approach comprises two primary components: a Direct 3D Variational Auto-Encoder (D3D-VAE) and a Direct 3D Diffusion Transformer (D3D-DiT). D3D-VAE efficiently encodes high-resolution 3D shapes into a compact and continuous latent triplane space. Notably, our method directly supervises the decoded geometry using a semi-continuous surface sampling strategy, diverging from previous methods relying on rendered images as supervision signals. D3D-DiT models the distribution of encoded 3D latents and is specifically designed to fuse positional information from the three feature maps of the triplane latent, enabling a native 3D generative model scalable to large-scale 3D datasets. Additionally, we introduce an innovative image-to-3D generation pipeline incorporating semantic and pixel-level image conditions, allowing the model to produce 3D shapes consistent with the provided conditional image input. Extensive experiments demonstrate the superiority of our large-scale pre-trained Direct3D over previous image-to-3D approaches, achieving significantly better generation quality and generalization ability, thus establishing a new state-of-the-art for 3D content creation. Project page: https://nju-3dv.github.io/projects/Direct3D/.
Read more6/4/2024