Click2Mask: Local Editing with Dynamic Mask Generation

0

Sign in to get full access
Overview
- The paper proposes a technique called "Click2Mask" for local image editing with dynamic mask generation.
- It leverages a Blended Latent Diffusion model to enable users to edit specific regions of an image by simply clicking on them.
- The model generates a mask on-the-fly that isolates the desired region, allowing the user to apply edits without affecting the rest of the image.
Plain English Explanation
The Click2Mask technique allows users to edit specific parts of an image by just clicking on them. The model automatically generates a mask that isolates the selected region, so the user can make changes without affecting the rest of the image.
This is done using a Blended Latent Diffusion model, which is a type of AI system that can generate and manipulate images. When the user clicks on a part of the image, the model identifies that region and creates a mask around it. The user can then apply edits, like changing the color or adding/removing elements, to just that masked area, leaving the rest of the image untouched.
This is a useful tool for things like photo editing, where you might want to adjust one part of an image without affecting the whole thing. It gives users more control and flexibility compared to traditional editing tools that require precisely selecting regions beforehand.
Technical Explanation
The key innovation in Click2Mask is the use of a Blended Latent Diffusion model to enable dynamic mask generation based on user input.
When a user clicks on a region of the image, the model takes the click location as input and outputs a segmentation mask that precisely delineates that region. This mask is then used to guide the image editing process, allowing the user to modify only the selected area without affecting the rest of the image.
The Blended Latent Diffusion model is trained on a large dataset of images and their segmentation masks. During inference, the model blends the original image with the latent representation of the image conditioned on the user's click, allowing it to dynamically generate a customized mask on-the-fly.
This approach contrasts with traditional local editing techniques that require users to manually select or brush the regions they want to edit. Click2Mask simplifies the editing process and gives users more control by automating the mask generation step.
Critical Analysis
The Click2Mask paper presents a promising approach for local image editing, but there are a few potential limitations and areas for further research:
-
Generalization: The paper only demonstrates the technique on a limited set of image editing tasks. It would be valuable to evaluate its performance on a wider range of editing scenarios, including more complex scenes and diverse image types.
-
User Experience: While the click-based interface is intuitive, the paper does not provide a thorough user evaluation. Assessing the usability and effectiveness of the tool in real-world editing workflows would be an important next step.
-
Robustness: The paper does not address the model's behavior when faced with ambiguous or noisy user input, such as multiple clicks or imprecise selections. Improving the system's robustness to these types of user inputs could enhance its practical utility.
-
Computational Efficiency: The use of a diffusion-based model may raise concerns about the computational resources required for real-time editing. Further optimizations or the exploration of alternative architectures could improve the technique's efficiency and make it more suitable for deployment in interactive applications.
Despite these potential limitations, the Click2Mask approach represents an exciting step forward in user-friendly local image editing, and the continued development of this line of research could lead to valuable advancements in the field.
Conclusion
The Click2Mask paper presents a novel technique that leverages Blended Latent Diffusion to enable dynamic mask generation for local image editing. By allowing users to simply click on a region of an image, the model can isolate that area and enable targeted edits without affecting the rest of the image.
This approach simplifies the editing process and gives users more control compared to traditional tools that require manual region selection. While there are some potential limitations to address, the Click2Mask technique represents an exciting advancement in the field of interactive image editing and could have a significant impact on a wide range of applications, from photo manipulation to digital art creation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Click2Mask: Local Editing with Dynamic Mask Generation
Omer Regev, Omri Avrahami, Dani Lischinski
Recent advancements in generative models have revolutionized image generation and editing, making these tasks accessible to non-experts. This paper focuses on local image editing, particularly the task of adding new content to a loosely specified area. Existing methods often require a precise mask or a detailed description of the location, which can be cumbersome and prone to errors. We propose Click2Mask, a novel approach that simplifies the local editing process by requiring only a single point of reference (in addition to the content description). A mask is dynamically grown around this point during a Blended Latent Diffusion (BLD) process, guided by a masked CLIP-based semantic loss. Click2Mask surpasses the limitations of segmentation-based and fine-tuning dependent methods, offering a more user-friendly and contextually accurate solution. Our experiments demonstrate that Click2Mask not only minimizes user effort but also delivers competitive or superior local image manipulation results compared to SoTA methods, according to both human judgement and automatic metrics. Key contributions include the simplification of user input, the ability to freely add objects unconstrained by existing segments, and the integration potential of our dynamic mask approach within other editing methods.
Read more9/14/2024
0
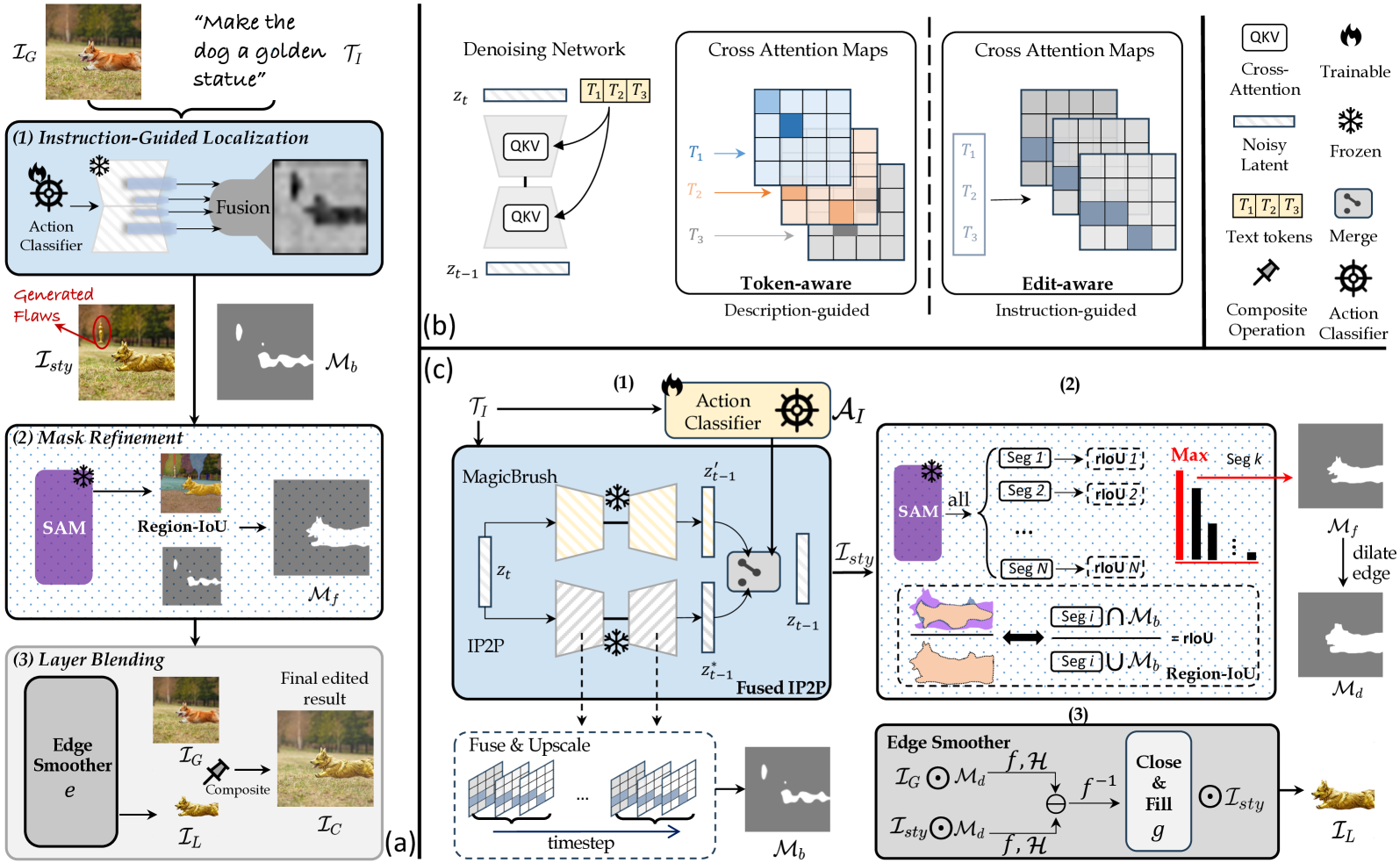
ZONE: Zero-Shot Instruction-Guided Local Editing
Shanglin Li, Bohan Zeng, Yutang Feng, Sicheng Gao, Xuhui Liu, Jiaming Liu, Li Lin, Xu Tang, Yao Hu, Jianzhuang Liu, Baochang Zhang
Recent advances in vision-language models like Stable Diffusion have shown remarkable power in creative image synthesis and editing.However, most existing text-to-image editing methods encounter two obstacles: First, the text prompt needs to be carefully crafted to achieve good results, which is not intuitive or user-friendly. Second, they are insensitive to local edits and can irreversibly affect non-edited regions, leaving obvious editing traces. To tackle these problems, we propose a Zero-shot instructiON-guided local image Editing approach, termed ZONE. We first convert the editing intent from the user-provided instruction (e.g., make his tie blue) into specific image editing regions through InstructPix2Pix. We then propose a Region-IoU scheme for precise image layer extraction from an off-the-shelf segment model. We further develop an edge smoother based on FFT for seamless blending between the layer and the image.Our method allows for arbitrary manipulation of a specific region with a single instruction while preserving the rest. Extensive experiments demonstrate that our ZONE achieves remarkable local editing results and user-friendliness, outperforming state-of-the-art methods. Code is available at https://github.com/lsl001006/ZONE.
Read more4/15/2024
🚀
0
PiClick: Picking the desired mask from multiple candidates in click-based interactive segmentation
Cilin Yan, Haochen Wang, Jie Liu, Xiaolong Jiang, Yao Hu, Xu Tang, Guoliang Kang, Efstratios Gavves
Click-based interactive segmentation aims to generate target masks via human clicking, which facilitates efficient pixel-level annotation and image editing. In such a task, target ambiguity remains a problem hindering the accuracy and efficiency of segmentation. That is, in scenes with rich context, one click may correspond to multiple potential targets, while most previous interactive segmentors only generate a single mask and fail to deal with target ambiguity. In this paper, we propose a novel interactive segmentation network named PiClick, to yield all potentially reasonable masks and suggest the most plausible one for the user. Specifically, PiClick utilizes a Transformer-based architecture to generate all potential target masks by mutually interactive mask queries. Moreover, a Target Reasoning module(TRM) is designed in PiClick to automatically suggest the user-desired mask from all candidates, relieving target ambiguity and extra-human efforts. Extensive experiments on 9 interactive segmentation datasets demonstrate PiClick performs favorably against previous state-of-the-arts considering the segmentation results. Moreover, we show that PiClick effectively reduces human efforts in annotating and picking the desired masks. To ease the usage and inspire future research, we release the source code of PiClick together with a plug-and-play annotation tool at https://github.com/cilinyan/PiClick.
Read more6/18/2024

0
Blended Latent Diffusion under Attention Control for Real-World Video Editing
Deyin Liu, Lin Yuanbo Wu, Xianghua Xie
Due to lack of fully publicly available text-to-video models, current video editing methods tend to build on pre-trained text-to-image generation models, however, they still face grand challenges in dealing with the local editing of video with temporal information. First, although existing methods attempt to focus on local area editing by a pre-defined mask, the preservation of the outside-area background is non-ideal due to the spatially entire generation of each frame. In addition, specially providing a mask by user is an additional costly undertaking, so an autonomous masking strategy integrated into the editing process is desirable. Last but not least, image-level pretrained model hasn't learned temporal information across frames of a video which is vital for expressing the motion and dynamics. In this paper, we propose to adapt a image-level blended latent diffusion model to perform local video editing tasks. Specifically, we leverage DDIM inversion to acquire the latents as background latents instead of the randomly noised ones to better preserve the background information of the input video. We further introduce an autonomous mask manufacture mechanism derived from cross-attention maps in diffusion steps. Finally, we enhance the temporal consistency across video frames by transforming the self-attention blocks of U-Net into temporal-spatial blocks. Through extensive experiments, our proposed approach demonstrates effectiveness in different real-world video editing tasks.
Read more9/6/2024