Blended Latent Diffusion under Attention Control for Real-World Video Editing

0

Sign in to get full access
Overview
- This paper introduces a novel video editing approach called Blended Latent Diffusion under Attention Control (BLDAC).
- BLDAC enables real-world video editing by blending diffusion model generations with the original video frames.
- The method uses a diffusion model trained on images and a DDIM inversion technique to control the video editing process.
Plain English Explanation
Blended Latent Diffusion under Attention Control (BLDAC) is a new way to edit videos that combines the power of diffusion models with the original video frames. Diffusion models are a type of AI that can generate realistic images, but they can also be used to edit existing images and videos.
The key idea behind BLDAC is to take the original video, invert it into a latent representation using a technique called DDIM inversion, and then blend that latent representation with new content generated by a diffusion model. This allows you to edit the video in a natural and seamless way, without having to start from scratch.
For example, you could use BLDAC to add a new object to a video, like a car or a person, or to change the lighting or background of a scene. The method gives you fine-grained control over the editing process, allowing you to specify which parts of the video you want to edit and how.
Overall, BLDAC is a powerful tool for video editing that combines the flexibility of diffusion models with the realism of the original video footage. It could be particularly useful for applications like visual effects, scene editing, and content creation.
Technical Explanation
Blended Latent Diffusion under Attention Control (BLDAC) is a novel video editing approach that leverages the capabilities of diffusion models to enable real-world video editing. The key components of the BLDAC method are:
-
Diffusion Model: The authors train a diffusion model on images, which can then be used to generate new content or edit existing images.
-
DDIM Inversion: To edit videos, the authors use a DDIM inversion technique to map the video frames into the latent space of the diffusion model. This allows them to manipulate the video in the latent space.
-
Attention Control: The authors introduce an attention control mechanism that allows them to specify which parts of the video they want to edit. This gives them fine-grained control over the editing process.
-
Blending: Finally, the authors blend the generated content from the diffusion model with the original video frames, creating a seamless and realistic edited video.
The authors demonstrate the effectiveness of BLDAC on a variety of video editing tasks, such as adding new objects, changing the lighting, and modifying the background. They show that BLDAC outperforms traditional video editing approaches in terms of both visual quality and ease of use.
Critical Analysis
The BLDAC method presents an interesting and promising approach to video editing, but there are a few potential limitations and areas for further research:
-
Computational Complexity: The DDIM inversion and diffusion model generation steps may be computationally intensive, which could limit the scalability of the method for real-time video editing applications.
-
Generalization: The authors train the diffusion model on images, which may limit its ability to generalize to the specific characteristics of video data. Further research could explore ways to improve the model's video-specific capabilities.
-
Temporal Consistency: While the authors mention that BLDAC preserves temporal consistency, there may be room for improvement, especially for complex video editing tasks that involve multiple frames.
-
User Interaction: The current implementation of BLDAC relies on attention control mechanisms to specify the editing regions. Exploring more intuitive user interfaces and interaction methods could further enhance the usability of the system.
Despite these potential limitations, the BLDAC method represents a significant advancement in the field of video editing and could have a wide range of applications, from visual effects to content creation and beyond.
Conclusion
Blended Latent Diffusion under Attention Control (BLDAC) is a novel video editing approach that combines the power of diffusion models with the realism of original video footage. By using a DDIM inversion technique to map video frames into the latent space of a diffusion model and an attention control mechanism to specify editing regions, BLDAC enables seamless and flexible video editing capabilities.
The method has the potential to revolutionize various video-related applications, from visual effects and scene editing to content creation and personalization. While there are some areas for further research and improvement, the core ideas behind BLDAC represent an exciting step forward in the field of video editing and could inspire future innovations in this domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Blended Latent Diffusion under Attention Control for Real-World Video Editing
Deyin Liu, Lin Yuanbo Wu, Xianghua Xie
Due to lack of fully publicly available text-to-video models, current video editing methods tend to build on pre-trained text-to-image generation models, however, they still face grand challenges in dealing with the local editing of video with temporal information. First, although existing methods attempt to focus on local area editing by a pre-defined mask, the preservation of the outside-area background is non-ideal due to the spatially entire generation of each frame. In addition, specially providing a mask by user is an additional costly undertaking, so an autonomous masking strategy integrated into the editing process is desirable. Last but not least, image-level pretrained model hasn't learned temporal information across frames of a video which is vital for expressing the motion and dynamics. In this paper, we propose to adapt a image-level blended latent diffusion model to perform local video editing tasks. Specifically, we leverage DDIM inversion to acquire the latents as background latents instead of the randomly noised ones to better preserve the background information of the input video. We further introduce an autonomous mask manufacture mechanism derived from cross-attention maps in diffusion steps. Finally, we enhance the temporal consistency across video frames by transforming the self-attention blocks of U-Net into temporal-spatial blocks. Through extensive experiments, our proposed approach demonstrates effectiveness in different real-world video editing tasks.
Read more9/6/2024
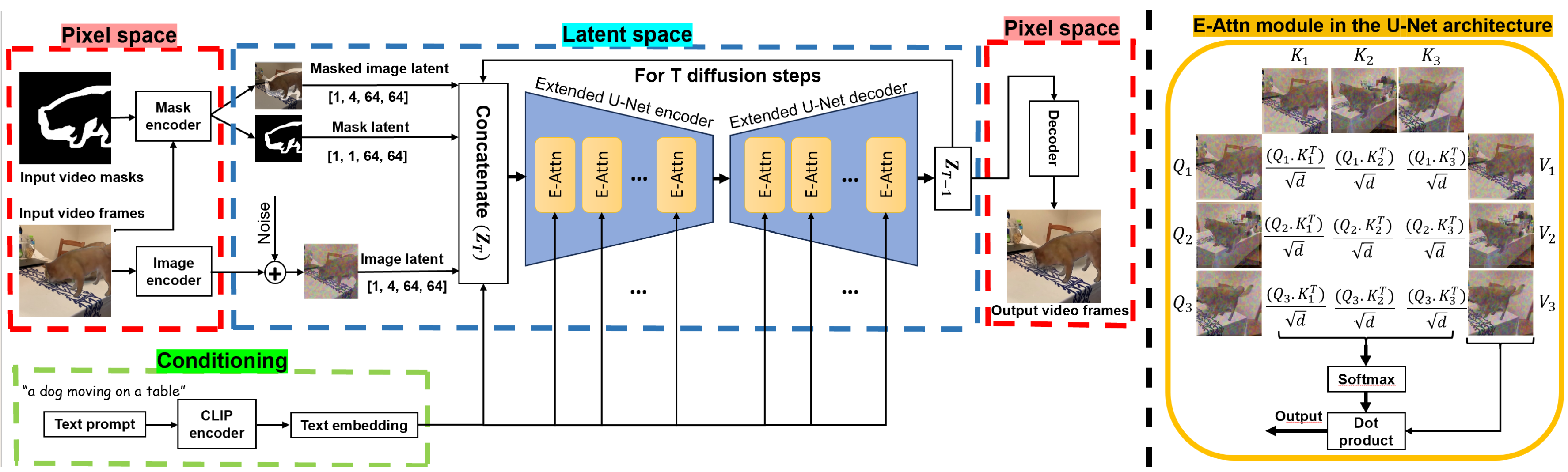
0
Temporally Consistent Object Editing in Videos using Extended Attention
AmirHossein Zamani, Amir G. Aghdam, Tiberiu Popa, Eugene Belilovsky
Image generation and editing have seen a great deal of advancements with the rise of large-scale diffusion models that allow user control of different modalities such as text, mask, depth maps, etc. However, controlled editing of videos still lags behind. Prior work in this area has focused on using 2D diffusion models to globally change the style of an existing video. On the other hand, in many practical applications, editing localized parts of the video is critical. In this work, we propose a method to edit videos using a pre-trained inpainting image diffusion model. We systematically redesign the forward path of the model by replacing the self-attention modules with an extended version of attention modules that creates frame-level dependencies. In this way, we ensure that the edited information will be consistent across all the video frames no matter what the shape and position of the masked area is. We qualitatively compare our results with state-of-the-art in terms of accuracy on several video editing tasks like object retargeting, object replacement, and object removal tasks. Simulations demonstrate the superior performance of the proposed strategy.
Read more6/4/2024

0
I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models
Wenqi Ouyang, Yi Dong, Lei Yang, Jianlou Si, Xingang Pan
The remarkable generative capabilities of diffusion models have motivated extensive research in both image and video editing. Compared to video editing which faces additional challenges in the time dimension, image editing has witnessed the development of more diverse, high-quality approaches and more capable software like Photoshop. In light of this gap, we introduce a novel and generic solution that extends the applicability of image editing tools to videos by propagating edits from a single frame to the entire video using a pre-trained image-to-video model. Our method, dubbed I2VEdit, adaptively preserves the visual and motion integrity of the source video depending on the extent of the edits, effectively handling global edits, local edits, and moderate shape changes, which existing methods cannot fully achieve. At the core of our method are two main processes: Coarse Motion Extraction to align basic motion patterns with the original video, and Appearance Refinement for precise adjustments using fine-grained attention matching. We also incorporate a skip-interval strategy to mitigate quality degradation from auto-regressive generation across multiple video clips. Experimental results demonstrate our framework's superior performance in fine-grained video editing, proving its capability to produce high-quality, temporally consistent outputs.
Read more5/28/2024
🤖
0
LLM-grounded Video Diffusion Models
Long Lian, Baifeng Shi, Adam Yala, Trevor Darrell, Boyi Li
Text-conditioned diffusion models have emerged as a promising tool for neural video generation. However, current models still struggle with intricate spatiotemporal prompts and often generate restricted or incorrect motion. To address these limitations, we introduce LLM-grounded Video Diffusion (LVD). Instead of directly generating videos from the text inputs, LVD first leverages a large language model (LLM) to generate dynamic scene layouts based on the text inputs and subsequently uses the generated layouts to guide a diffusion model for video generation. We show that LLMs are able to understand complex spatiotemporal dynamics from text alone and generate layouts that align closely with both the prompts and the object motion patterns typically observed in the real world. We then propose to guide video diffusion models with these layouts by adjusting the attention maps. Our approach is training-free and can be integrated into any video diffusion model that admits classifier guidance. Our results demonstrate that LVD significantly outperforms its base video diffusion model and several strong baseline methods in faithfully generating videos with the desired attributes and motion patterns.
Read more5/7/2024