ClimRetrieve: A Benchmarking Dataset for Information Retrieval from Corporate Climate Disclosures

0
Sign in to get full access
Overview
- This paper presents ClimRetrieve, a new benchmark dataset for evaluating information retrieval systems on corporate climate disclosures.
- The dataset contains over 31,000 documents from the financial filings of 400 publicly-traded companies, along with a set of 50 manually-curated information retrieval queries.
- The authors also provide baseline retrieval performance using several common IR models, establishing a benchmark for future research in this domain.
Plain English Explanation
The paper introduces a new dataset called ClimRetrieve that can be used to test and compare the performance of information retrieval (IR) systems when searching through corporate climate disclosures. Corporate climate disclosures are reports published by companies that describe their efforts to address climate change.
The ClimRetrieve dataset includes over 31,000 documents from the financial filings of 400 public companies, along with 50 sample search queries that someone might use to find information about a company's climate-related activities. The authors have already run several common IR models on the dataset and reported their baseline performance, providing a starting point for other researchers to build upon.
This dataset can be valuable for improving the retrieval of climate-related information from corporate disclosures, which is an important task for investors, policymakers, and the general public who want to understand how companies are addressing climate change. Having a standardized benchmark can help drive progress in this area of retrieval-augmented generation.
Technical Explanation
The ClimRetrieve dataset was constructed by the authors by scraping and processing over 31,000 financial documents from the SEC filings of 400 publicly-traded companies. These documents contain the companies' voluntary climate-related disclosures, which can be used to assess their environmental impact and sustainability efforts.
To create retrieval queries for the dataset, the authors manually curated a set of 50 information needs that someone might have when searching for climate-related information about a company. These queries cover a range of topics, from greenhouse gas emissions and renewable energy usage to climate risk mitigation strategies and sustainability reporting.
The authors then establish baseline retrieval performance on the ClimRetrieve dataset using several common IR models, including BM25, TF-IDF, and a language model-based approach. They evaluate the models' ability to rank the relevant documents highly for each query, using standard IR metrics like Normalized Discounted Cumulative Gain (NDCG) and Mean Reciprocal Rank (MRR).
This benchmark can serve as a starting point for exploring the nexus between retrievability and query generation strategies in the context of corporate climate disclosures. Researchers can use the ClimRetrieve dataset to develop and test new IR techniques, with the goal of improving the discoverability and accessibility of climate-related information in corporate filings.
Critical Analysis
The ClimRetrieve dataset represents a valuable contribution to the field of information retrieval, as it provides a standardized benchmark for evaluating systems on a real-world task with significant societal impact. The authors have taken care to construct a high-quality dataset and establish reasonable baseline performance, which should facilitate further research and development in this area.
One potential limitation of the dataset is the relatively small number of manually-curated queries (50). While this set covers a range of information needs, it may not be comprehensive, and the performance of IR models could be sensitive to the specific queries chosen. Expanding the query set or exploring collaborative retrieval-augmented generation approaches could help address this.
Additionally, the dataset only includes climate-related disclosures from publicly-traded companies, which may not be representative of the full landscape of corporate sustainability reporting. Extending the dataset to include private companies, non-profit organizations, or international entities could broaden its applicability and provide a more holistic view of climate-related information retrieval challenges.
Overall, the ClimRetrieve dataset represents a valuable contribution to the field and has the potential to drive progress in the important task of improving access to climate-related information in corporate disclosures.
Conclusion
The ClimRetrieve dataset provides a new benchmark for evaluating information retrieval systems on the task of surfacing climate-related information from corporate financial filings. By making this dataset publicly available, the authors have created an opportunity for researchers to develop and test novel IR techniques that can enhance the discoverability and accessibility of critical climate data.
The baseline performance reported in the paper establishes a starting point for future work, and the dataset's focus on a real-world problem with significant societal implications makes it a valuable resource for the field. As the need for transparent and actionable climate information continues to grow, tools and systems powered by the ClimRetrieve dataset can play a crucial role in empowering investors, policymakers, and the public to better understand and address the climate challenge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ClimRetrieve: A Benchmarking Dataset for Information Retrieval from Corporate Climate Disclosures
Tobias Schimanski, Jingwei Ni, Roberto Spacey, Nicola Ranger, Markus Leippold
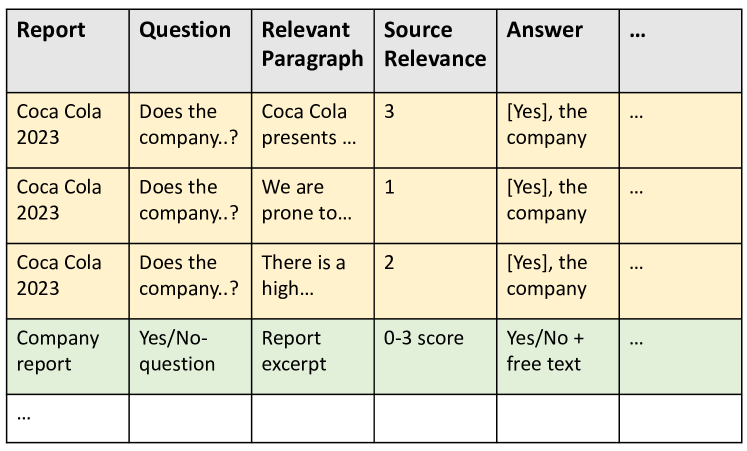
To handle the vast amounts of qualitative data produced in corporate climate communication, stakeholders increasingly rely on Retrieval Augmented Generation (RAG) systems. However, a significant gap remains in evaluating domain-specific information retrieval - the basis for answer generation. To address this challenge, this work simulates the typical tasks of a sustainability analyst by examining 30 sustainability reports with 16 detailed climate-related questions. As a result, we obtain a dataset with over 8.5K unique question-source-answer pairs labeled by different levels of relevance. Furthermore, we develop a use case with the dataset to investigate the integration of expert knowledge into information retrieval with embeddings. Although we show that incorporating expert knowledge works, we also outline the critical limitations of embeddings in knowledge-intensive downstream domains like climate change communication.
Read more7/18/2024

0
ClimDetect: A Benchmark Dataset for Climate Change Detection and Attribution
Sungduk Yu, Brian L. White, Anahita Bhiwandiwalla, Musashi Hinck, Matthew Lyle Olson, Tung Nguyen, Vasudev Lal
Detecting and attributing temperature increases due to climate change is crucial for understanding global warming and guiding adaptation strategies. The complexity of distinguishing human-induced climate signals from natural variability has challenged traditional detection and attribution (D&A) approaches, which seek to identify specific fingerprints in climate response variables. Deep learning offers potential for discerning these complex patterns in expansive spatial datasets. However, lack of standard protocols has hindered consistent comparisons across studies. We introduce ClimDetect, a standardized dataset of over 816k daily climate snapshots, designed to enhance model accuracy in identifying climate change signals. ClimDetect integrates various input and target variables used in past research, ensuring comparability and consistency. We also explore the application of vision transformers (ViT) to climate data, a novel and modernizing approach in this context. Our open-access data and code serve as a benchmark for advancing climate science through improved model evaluations. ClimDetect is publicly accessible via Huggingface dataet respository at: https://huggingface.co/datasets/ClimDetect/ClimDetect.
Read more8/29/2024

0
PermitQA: A Benchmark for Retrieval Augmented Generation in Wind Siting and Permitting domain
Rounak Meyur, Hung Phan, Sridevi Wagle, Jan Strube, Mahantesh Halappanavar, Sameera Horawalavithana, Anurag Acharya, Sai Munikoti
In the rapidly evolving landscape of Natural Language Processing (NLP) and text generation, the emergence of Retrieval Augmented Generation (RAG) presents a promising avenue for improving the quality and reliability of generated text by leveraging information retrieved from user specified database. Benchmarking is essential to evaluate and compare the performance of the different RAG configurations in terms of retriever and generator, providing insights into their effectiveness, scalability, and suitability for the specific domain and applications. In this paper, we present a comprehensive framework to generate a domain relevant RAG benchmark. Our framework is based on automatic question-answer generation with Human (domain experts)-AI Large Language Model (LLM) teaming. As a case study, we demonstrate the framework by introducing PermitQA, a first-of-its-kind benchmark on the wind siting and permitting domain which comprises of multiple scientific documents/reports related to environmental impact of wind energy projects. Our framework systematically evaluates RAG performance using diverse metrics and multiple question types with varying complexity level. We also demonstrate the performance of different models on our benchmark.
Read more8/22/2024
📶
0
New!Exploring Information Retrieval Landscapes: An Investigation of a Novel Evaluation Techniques and Comparative Document Splitting Methods
Esmaeil Narimissa (Australian Taxation Office), David Raithel (Australian Taxation Office)
The performance of Retrieval-Augmented Generation (RAG) systems in information retrieval is significantly influenced by the characteristics of the documents being processed. In this study, the structured nature of textbooks, the conciseness of articles, and the narrative complexity of novels are shown to require distinct retrieval strategies. A comparative evaluation of multiple document-splitting methods reveals that the Recursive Character Splitter outperforms the Token-based Splitter in preserving contextual integrity. A novel evaluation technique is introduced, utilizing an open-source model to generate a comprehensive dataset of question-and-answer pairs, simulating realistic retrieval scenarios to enhance testing efficiency and metric reliability. The evaluation employs weighted scoring metrics, including SequenceMatcher, BLEU, METEOR, and BERT Score, to assess the system's accuracy and relevance. This approach establishes a refined standard for evaluating the precision of RAG systems, with future research focusing on optimizing chunk and overlap sizes to improve retrieval accuracy and efficiency.
Read more9/16/2024