ClinLinker: Medical Entity Linking of Clinical Concept Mentions in Spanish
2404.06367
0
0

Abstract
Advances in natural language processing techniques, such as named entity recognition and normalization to widely used standardized terminologies like UMLS or SNOMED-CT, along with the digitalization of electronic health records, have significantly advanced clinical text analysis. This study presents ClinLinker, a novel approach employing a two-phase pipeline for medical entity linking that leverages the potential of in-domain adapted language models for biomedical text mining: initial candidate retrieval using a SapBERT-based bi-encoder and subsequent re-ranking with a cross-encoder, trained by following a contrastive-learning strategy to be tailored to medical concepts in Spanish. This methodology, focused initially on content in Spanish, substantially outperforming multilingual language models designed for the same purpose. This is true even for complex scenarios involving heterogeneous medical terminologies and being trained on a subset of the original data. Our results, evaluated using top-k accuracy at 25 and other top-k metrics, demonstrate our approach's performance on two distinct clinical entity linking Gold Standard corpora, DisTEMIST (diseases) and MedProcNER (clinical procedures), outperforming previous benchmarks by 40 points in DisTEMIST and 43 points in MedProcNER, both normalized to SNOMED-CT codes. These findings highlight our approach's ability to address language-specific nuances and set a new benchmark in entity linking, offering a potent tool for enhancing the utility of digital medical records. The resulting system is of practical value, both for large scale automatic generation of structured data derived from clinical records, as well as for exhaustive extraction and harmonization of predefined clinical variables of interest.
Create account to get full access
Overview
- Explores medical entity linking in Spanish using an encoder-only large language model and contrastive learning techniques
- Focuses on linking clinical concept mentions in Spanish text to SNOMED-CT, a comprehensive medical terminology system
- Introduces ClinLinker, a novel approach for this task that outperforms existing methods
Plain English Explanation
The paper ClinLinker: Medical Entity Linking of Clinical Concept Mentions in Spanish explores a technique called "medical entity linking" for Spanish clinical text. This involves taking words or phrases that refer to medical concepts (like "diabetes" or "heart attack") and connecting them to a standardized medical terminology system called SNOMED-CT.
The researchers developed a new system called ClinLinker that uses a large language model - a type of AI that can understand and generate human-like text. ClinLinker is trained using a technique called "contrastive learning," which helps it learn to better recognize and link medical terms in Spanish text.
Compared to existing methods, ClinLinker was shown to perform better at this medical entity linking task. This could be useful for applications like automating the analysis of medical records or improving search and retrieval of relevant medical information.
Technical Explanation
The paper introduces ClinLinker, a novel approach for medical entity linking in Spanish clinical text. The system uses an encoder-only large language model, which is a type of AI that can understand and generate human-like text without requiring a separate decoder component.
ClinLinker is trained using contrastive learning, a technique that encourages the model to learn representations that maximize the similarity between positive (correctly linked) examples and minimize the similarity between negative (incorrectly linked) examples. This helps the model better distinguish between valid medical concept mentions and other text.
The researchers evaluate ClinLinker on a Spanish clinical corpus and compare it to previous state-of-the-art methods for medical entity linking. They find that ClinLinker outperforms these baselines, demonstrating the effectiveness of the contrastive learning approach for this cross-lingual argument mining task.
Critical Analysis
The paper provides a thorough evaluation of ClinLinker's performance and compares it to previous methods. However, the authors do not extensively discuss potential limitations or caveats of their approach.
One area that could be explored further is the ability of ClinLinker to handle ambiguous or contextual medical terminology. The CLUE benchmark for clinical language understanding suggests that accurately linking such terms can be challenging.
Additionally, the paper focuses solely on the Spanish language. It would be valuable to see how the ClinLinker approach could be extended to other languages or applied to a more diverse set of clinical text sources.
Conclusion
Overall, the ClinLinker system represents a promising advance in medical entity linking for Spanish clinical text. By leveraging contrastive learning with a large language model, the researchers have developed a technique that outperforms previous state-of-the-art methods.
This work could have valuable applications in tasks like automating the analysis of medical records, improving medical search and retrieval, and enhancing our overall understanding of clinical language. Further research to address potential limitations and expand the approach to other languages and domains would be a valuable next step.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Efficient Biomedical Entity Linking: Clinical Text Standardization with Low-Resource Techniques
Akshit Achara, Sanand Sasidharan, Gagan N
0
0
Clinical text is rich in information, with mentions of treatment, medication and anatomy among many other clinical terms. Multiple terms can refer to the same core concepts which can be referred as a clinical entity. Ontologies like the Unified Medical Language System (UMLS) are developed and maintained to store millions of clinical entities including the definitions, relations and other corresponding information. These ontologies are used for standardization of clinical text by normalizing varying surface forms of a clinical term through Biomedical entity linking. With the introduction of transformer-based language models, there has been significant progress in Biomedical entity linking. In this work, we focus on learning through synonym pairs associated with the entities. As compared to the existing approaches, our approach significantly reduces the training data and resource consumption. Moreover, we propose a suite of context-based and context-less reranking techniques for performing the entity disambiguation. Overall, we achieve similar performance to the state-of-the-art zero-shot and distant supervised entity linking techniques on the Medmentions dataset, the largest annotated dataset on UMLS, without any domain-based training. Finally, we show that retrieval performance alone might not be sufficient as an evaluation metric and introduce an article level quantitative and qualitative analysis to reveal further insights on the performance of entity linking methods.
5/28/2024

Biomedical Entity Linking for Dutch: Fine-tuning a Self-alignment BERT Model on an Automatically Generated Wikipedia Corpus
Fons Hartendorp, Tom Seinen, Erik van Mulligen, Suzan Verberne
0
0
Biomedical entity linking, a main component in automatic information extraction from health-related texts, plays a pivotal role in connecting textual entities (such as diseases, drugs and body parts mentioned by patients) to their corresponding concepts in a structured biomedical knowledge base. The task remains challenging despite recent developments in natural language processing. This paper presents the first evaluated biomedical entity linking model for the Dutch language. We use MedRoBERTa.nl as base model and perform second-phase pretraining through self-alignment on a Dutch biomedical ontology extracted from the UMLS and Dutch SNOMED. We derive a corpus from Wikipedia of ontology-linked Dutch biomedical entities in context and fine-tune our model on this dataset. We evaluate our model on the Dutch portion of the Mantra GSC-corpus and achieve 54.7% classification accuracy and 69.8% 1-distance accuracy. We then perform a case study on a collection of unlabeled, patient-support forum data and show that our model is hampered by the limited quality of the preceding entity recognition step. Manual evaluation of small sample indicates that of the correctly extracted entities, around 65% is linked to the correct concept in the ontology. Our results indicate that biomedical entity linking in a language other than English remains challenging, but our Dutch model can be used to for high-level analysis of patient-generated text.
5/21/2024

SNOBERT: A Benchmark for clinical notes entity linking in the SNOMED CT clinical terminology
Mikhail Kulyabin, Gleb Sokolov, Aleksandr Galaida, Andreas Maier, Tomas Arias-Vergara
0
0
The extraction and analysis of insights from medical data, primarily stored in free-text formats by healthcare workers, presents significant challenges due to its unstructured nature. Medical coding, a crucial process in healthcare, remains minimally automated due to the complexity of medical ontologies and restricted access to medical texts for training Natural Language Processing models. In this paper, we proposed a method, SNOBERT, of linking text spans in clinical notes to specific concepts in the SNOMED CT using BERT-based models. The method consists of two stages: candidate selection and candidate matching. The models were trained on one of the largest publicly available dataset of labeled clinical notes. SNOBERT outperforms other classical methods based on deep learning, as confirmed by the results of a challenge in which it was applied.
5/28/2024
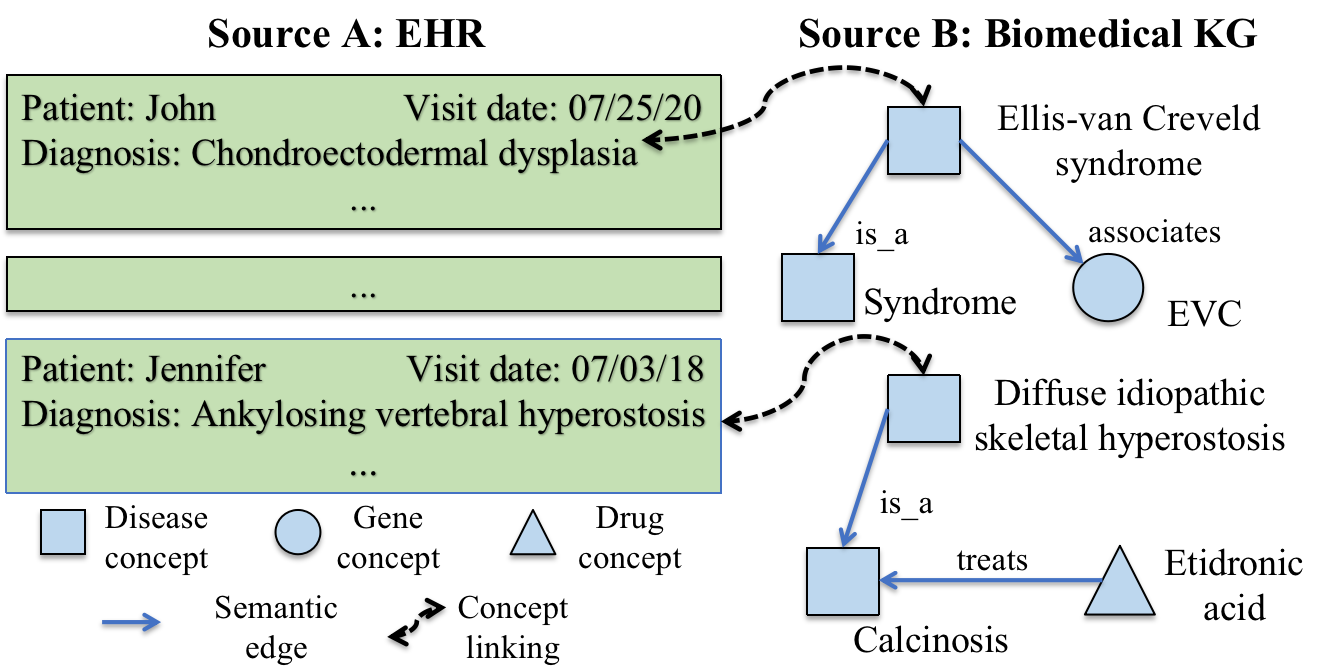
PromptLink: Leveraging Large Language Models for Cross-Source Biomedical Concept Linking
Yuzhang Xie, Jiaying Lu, Joyce Ho, Fadi Nahab, Xiao Hu, Carl Yang
0
0
Linking (aligning) biomedical concepts across diverse data sources enables various integrative analyses, but it is challenging due to the discrepancies in concept naming conventions. Various strategies have been developed to overcome this challenge, such as those based on string-matching rules, manually crafted thesauri, and machine learning models. However, these methods are constrained by limited prior biomedical knowledge and can hardly generalize beyond the limited amounts of rules, thesauri, or training samples. Recently, large language models (LLMs) have exhibited impressive results in diverse biomedical NLP tasks due to their unprecedentedly rich prior knowledge and strong zero-shot prediction abilities. However, LLMs suffer from issues including high costs, limited context length, and unreliable predictions. In this research, we propose PromptLink, a novel biomedical concept linking framework that leverages LLMs. It first employs a biomedical-specialized pre-trained language model to generate candidate concepts that can fit in the LLM context windows. Then it utilizes an LLM to link concepts through two-stage prompts, where the first-stage prompt aims to elicit the biomedical prior knowledge from the LLM for the concept linking task and the second-stage prompt enforces the LLM to reflect on its own predictions to further enhance their reliability. Empirical results on the concept linking task between two EHR datasets and an external biomedical KG demonstrate the effectiveness of PromptLink. Furthermore, PromptLink is a generic framework without reliance on additional prior knowledge, context, or training data, making it well-suited for concept linking across various types of data sources. The source code is available at https://github.com/constantjxyz/PromptLink.
5/14/2024