Cross-lingual Argument Mining in the Medical Domain

0
🌿
Sign in to get full access
Overview
- Artificial Intelligence (AI) is playing an increasingly important role in the medical domain, as clinicians rely on massive amounts of unstructured textual data to make decisions.
- Argument Mining (AM) can help structure this textual data by identifying the argumentative components and classifying the relationships between them.
- However, most AM research has focused on the English language, leaving other languages like Spanish understudied.
- This paper investigates strategies to perform AM on medical texts in Spanish, where no annotated data is available.
Plain English Explanation
The medical field is using more and more AI technology as doctors have to deal with huge amounts of unstructured text data when making decisions. Argument Mining (AM) is a way to organize this textual data by identifying the key arguments and how they are connected.
But most of the work on AM has only looked at the English language. This paper examines different approaches to doing AM on medical texts in Spanish, since there isn't any labeled Spanish data available to train on.
The researchers found that automatically translating English data and using it to label Spanish data (called "data-transfer") works well to generate Spanish annotations without needing expensive manual labeling. Surprisingly, this data-transfer approach outperformed using multilingual language models (called "model-transfer"), which went against previous findings for other text tasks.
The automatically generated Spanish data can also be used to improve the original English AM system, providing a way to easily boost performance on the English side as well. Overall, this paper demonstrates an effective way to adapt Argument Mining to a new language like Spanish without starting from scratch.
Technical Explanation
The paper explores different strategies for performing Argument Mining (AM) on medical texts in Spanish, a language that lacks annotated data for this task. The key approaches investigated are:
-
Data-Transfer: Automatically translating English AM data to Spanish and projecting the annotations. This creates Spanish data without manual labeling.
-
Model-Transfer: Leveraging the cross-lingual transfer capabilities of multilingual pre-trained language models to perform AM in Spanish.
Contrary to previous findings for other sequence labeling tasks, the experiments showed that the data-transfer approach outperformed the model-transfer methods. The automatically generated Spanish data was also used to improve results on the original English AM task, providing a form of data augmentation.
The paper makes several technical contributions:
- It demonstrates the effectiveness of data-transfer for generating annotated data in a low-resource language like Spanish.
- It shows that data-transfer can outperform model-transfer approaches, challenging previous conclusions about the superiority of cross-lingual transfer learning.
- It provides a fully automated data augmentation strategy by using the generated Spanish data to improve English AM performance.
The technical details include the datasets used, the specific AM architectures, and the quantitative results comparing the different methods. The paper provides a strong empirical foundation for adapting AM to new languages through data-centric approaches.
Critical Analysis
The paper presents a thorough and well-designed study on adapting Argument Mining to the Spanish language. The key strengths are the rigorous experimental setup, the surprising finding about data-transfer outperforming model-transfer, and the demonstration of using the generated Spanish data to improve the original English system.
However, the paper also acknowledges some limitations:
- The study is focused only on the medical domain, so the findings may not generalize to other genres of Spanish text.
- The automatically translated and projected annotations may contain errors, which could impact the performance of the resulting Spanish AM system.
- The paper does not explore other data augmentation techniques beyond using the generated Spanish data, such as using large language models for data de-formalization.
Additionally, some areas for further research include:
- Investigating the robustness of the data-transfer approach by evaluating on a wider range of target languages and domains.
- Exploring ways to further improve the quality of the automatically generated annotations, such as by leveraging multilingual benchmarking of large language models or comprehensive studies of language models for clinical/biomedical text.
- Comparing the proposed data augmentation strategy to other techniques for enhancing neural models with external knowledge.
Overall, this paper makes a valuable contribution to the field of Argument Mining by demonstrating an effective approach for adapting the task to a new language, with potential implications for other low-resource natural language processing applications.
Conclusion
This paper investigates strategies for performing Argument Mining (AM) on medical texts in Spanish, a language that lacks annotated data for this task. The key findings are:
- Automatically translating English AM data to Spanish and projecting the annotations (data-transfer) is an effective way to generate Spanish AM data without manual labeling.
- Surprisingly, the data-transfer approach outperformed methods based on the cross-lingual transfer capabilities of multilingual language models (model-transfer).
- The automatically generated Spanish data can also be used to improve results on the original English AM task, providing a fully automated data augmentation strategy.
These findings challenge previous conclusions about the superiority of model-transfer for sequence labeling tasks and demonstrate the power of data-centric approaches for adapting natural language processing technologies to new languages and domains. The paper provides a strong foundation for further research on Argument Mining and other low-resource language applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
0
Cross-lingual Argument Mining in the Medical Domain
Anar Yeginbergen, Rodrigo Agerri
Nowadays the medical domain is receiving more and more attention in applications involving Artificial Intelligence as clinicians decision-making is increasingly dependent on dealing with enormous amounts of unstructured textual data. In this context, Argument Mining (AM) helps to meaningfully structure textual data by identifying the argumentative components in the text and classifying the relations between them. However, as it is the case for man tasks in Natural Language Processing in general and in medical text processing in particular, the large majority of the work on computational argumentation has been focusing only on the English language. In this paper, we investigate several strategies to perform AM in medical texts for a language such as Spanish, for which no annotated data is available. Our work shows that automatically translating and projecting annotations (data-transfer) from English to a given target language is an effective way to generate annotated data without costly manual intervention. Furthermore, and contrary to conclusions from previous work for other sequence labelling tasks, our experiments demonstrate that data-transfer outperforms methods based on the crosslingual transfer capabilities of multilingual pre-trained language models (model-transfer). Finally, we show how the automatically generated data in Spanish can also be used to improve results in the original English monolingual setting, providing thus a fully automatic data augmentation strategy.
Read more7/25/2024

0
End-to-End Argument Mining as Augmented Natural Language Generation
Nilmadhab Das, Vishal Choudhary, V. Vijaya Saradhi, Ashish Anand
Argument Mining (AM) involves identifying and extracting Argumentative Components (ACs) and their corresponding Argumentative Relations (ARs). Most of the prior works have broken down these tasks into multiple sub-tasks. Existing end-to-end setups primarily use the dependency parsing approach. This work introduces a generative paradigm-based end-to-end framework argTANL. argTANL frames the argumentative structures into label-augmented text, called Augmented Natural Language (ANL). This framework jointly extracts both ACs and ARs from a given argumentative text. Additionally, this study explores the impact of Argumentative and Discourse markers on enhancing the model's performance within the proposed framework. Two distinct frameworks, Marker-Enhanced argTANL (ME-argTANL) and argTANL with specialized Marker-Based Fine-Tuning, are proposed to achieve this. Extensive experiments are conducted on three standard AM benchmarks to demonstrate the superior performance of the ME-argTANL.
Read more9/10/2024
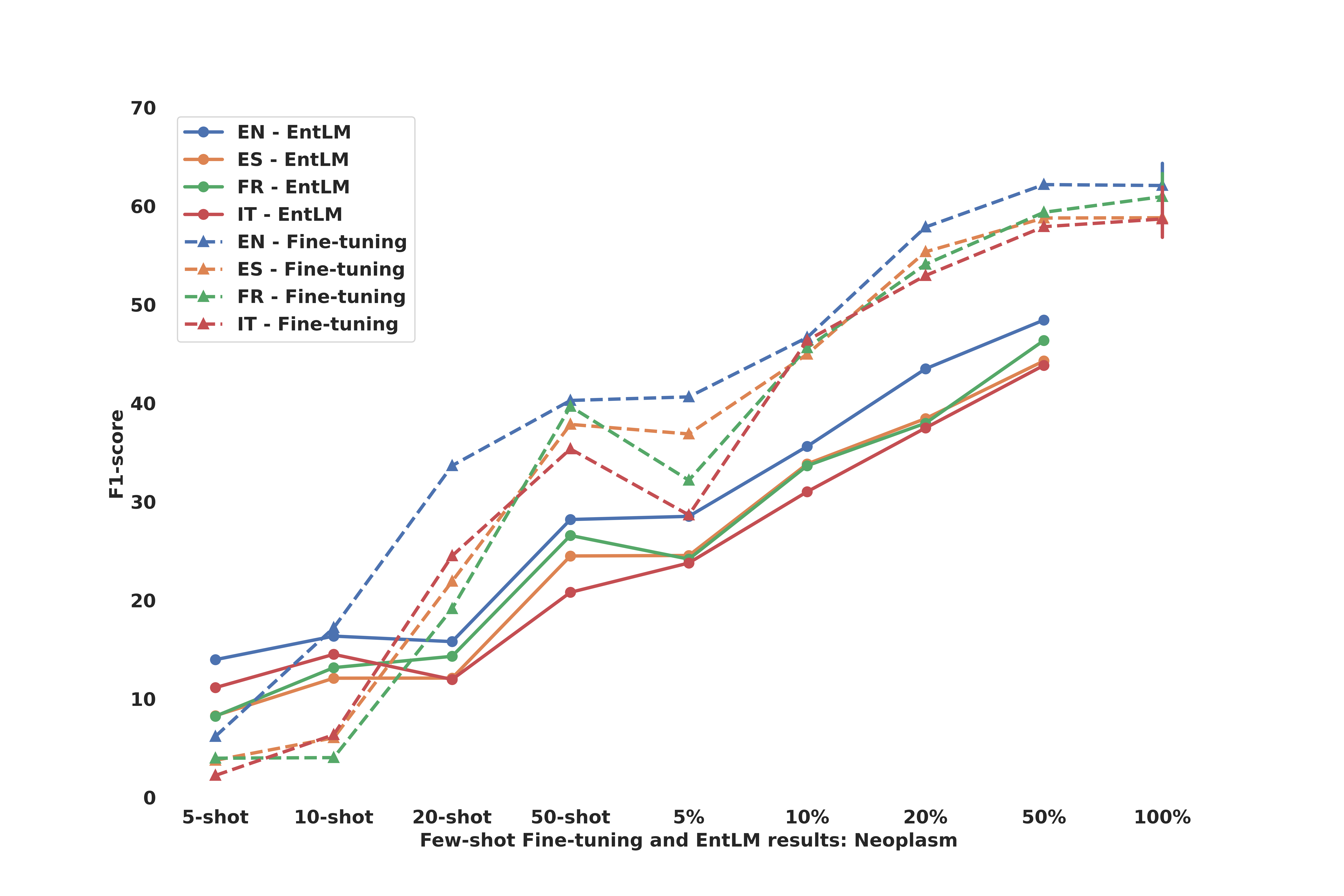
0
Argument Mining in Data Scarce Settings: Cross-lingual Transfer and Few-shot Techniques
Anar Yeginbergen, Maite Oronoz, Rodrigo Agerri
Recent research on sequence labelling has been exploring different strategies to mitigate the lack of manually annotated data for the large majority of the world languages. Among others, the most successful approaches have been based on (i) the cross-lingual transfer capabilities of multilingual pre-trained language models (model-transfer), (ii) data translation and label projection (data-transfer) and (iii), prompt-based learning by reusing the mask objective to exploit the few-shot capabilities of pre-trained language models (few-shot). Previous work seems to conclude that model-transfer outperforms data-transfer methods and that few-shot techniques based on prompting are superior to updating the model's weights via fine-tuning. In this paper, we empirically demonstrate that, for Argument Mining, a sequence labelling task which requires the detection of long and complex discourse structures, previous insights on cross-lingual transfer or few-shot learning do not apply. Contrary to previous work, we show that for Argument Mining data transfer obtains better results than model-transfer and that fine-tuning outperforms few-shot methods. Regarding the former, the domain of the dataset used for data-transfer seems to be a deciding factor, while, for few-shot, the type of task (length and complexity of the sequence spans) and sampling method prove to be crucial.
Read more7/8/2024
💬
0
Exploring the Potential of Large Language Models in Computational Argumentation
Guizhen Chen, Liying Cheng, Luu Anh Tuan, Lidong Bing
Computational argumentation has become an essential tool in various domains, including law, public policy, and artificial intelligence. It is an emerging research field in natural language processing that attracts increasing attention. Research on computational argumentation mainly involves two types of tasks: argument mining and argument generation. As large language models (LLMs) have demonstrated impressive capabilities in understanding context and generating natural language, it is worthwhile to evaluate the performance of LLMs on diverse computational argumentation tasks. This work aims to embark on an assessment of LLMs, such as ChatGPT, Flan models, and LLaMA2 models, in both zero-shot and few-shot settings. We organize existing tasks into six main categories and standardize the format of fourteen openly available datasets. In addition, we present a new benchmark dataset on counter speech generation that aims to holistically evaluate the end-to-end performance of LLMs on argument mining and argument generation. Extensive experiments show that LLMs exhibit commendable performance across most of the datasets, demonstrating their capabilities in the field of argumentation. Our analysis offers valuable suggestions for evaluating computational argumentation and its integration with LLMs in future research endeavors.
Read more7/2/2024