CLIP as RNN: Segment Countless Visual Concepts without Training Endeavor
2312.07661
0
0
🏋️
Abstract
Existing open-vocabulary image segmentation methods require a fine-tuning step on mask labels and/or image-text datasets. Mask labels are labor-intensive, which limits the number of categories in segmentation datasets. Consequently, the vocabulary capacity of pre-trained VLMs is severely reduced after fine-tuning. However, without fine-tuning, VLMs trained under weak image-text supervision tend to make suboptimal mask predictions. To alleviate these issues, we introduce a novel recurrent framework that progressively filters out irrelevant texts and enhances mask quality without training efforts. The recurrent unit is a two-stage segmenter built upon a frozen VLM. Thus, our model retains the VLM's broad vocabulary space and equips it with segmentation ability. Experiments show that our method outperforms not only the training-free counterparts, but also those fine-tuned with millions of data samples, and sets the new state-of-the-art records for both zero-shot semantic and referring segmentation. Concretely, we improve the current record by 28.8, 16.0, and 6.9 mIoU on Pascal VOC, COCO Object, and Pascal Context.
Create account to get full access
Overview
- This document provides guidelines for authors responding to reviews of their LaTeX-formatted papers.
- It covers recommended length for responses, as well as proper formatting and structure.
- The guidelines aim to help authors effectively communicate their responses to reviewers.
Plain English Explanation
This paper outlines instructions for authors on how to properly format and structure their responses to reviews of research papers written using the LaTeX typesetting system. The key points cover:
- The appropriate length for response documents, striking a balance between being concise and providing sufficient detail.
- Proper formatting guidelines, such as using clear section headings and organizing the response in a logical flow.
The goal of these guidelines is to help authors communicate their feedback to reviewers in an effective and easy-to-follow manner. By adhering to these recommendations, authors can ensure their responses are clear, well-structured, and address the reviewers' comments appropriately.
Technical Explanation
The document begins by discussing the recommended length for author responses, advising a balance between being concise and providing sufficient detail to address the reviewers' comments.
The main body of the guidelines focuses on formatting the response document. This includes using clear section headings, such as an introduction, responses to specific comments, and a conclusion. The authors also recommend structuring the response in a logical flow that is easy for reviewers to follow.
Additional formatting guidance covers elements like font size, margins, and the use of bulleted lists or tables to present information clearly. The guidelines aim to help authors create a well-organized, visually appealing response that effectively communicates their feedback.
Critical Analysis
The guidelines provided in this document seem reasonable and well-tailored to the goal of helping authors craft effective responses to paper reviews. By focusing on length, structure, and formatting, the recommendations address key aspects of response communication.
One potential limitation is the lack of guidance on the tone or style of responses. While the guidelines emphasize clarity and organization, they do not explicitly discuss maintaining a professional, constructive tone when addressing reviewer comments. This could be an area for further refinement to ensure authors respond in a manner that is both informative and courteous.
Additionally, the guidelines do not provide specific advice on how to address different types of reviewer feedback, such as requests for clarification, suggestions for additional analysis, or critiques of the paper's methodology. More nuanced guidance in this area could further improve the usefulness of these instructions.
Conclusion
These LaTeX guidelines for author responses offer a comprehensive set of recommendations to help researchers effectively communicate their feedback to paper reviewers. By providing clear guidance on length, structure, and formatting, the document aims to ensure authors create well-organized, easy-to-follow responses that address the reviewers' comments in a clear and constructive manner.
While the guidelines could be expanded to include more advice on tone and addressing different types of feedback, the core principles outlined in this document provide a solid foundation for authors to follow when preparing their responses. Adhering to these guidelines can help strengthen the author-reviewer dialogue and ultimately improve the quality of published research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

kNN-CLIP: Retrieval Enables Training-Free Segmentation on Continually Expanding Large Vocabularies
Zhongrui Gui, Shuyang Sun, Runjia Li, Jianhao Yuan, Zhaochong An, Karsten Roth, Ameya Prabhu, Philip Torr
0
0
Rapid advancements in continual segmentation have yet to bridge the gap of scaling to large continually expanding vocabularies under compute-constrained scenarios. We discover that traditional continual training leads to catastrophic forgetting under compute constraints, unable to outperform zero-shot segmentation methods. We introduce a novel strategy for semantic and panoptic segmentation with zero forgetting, capable of adapting to continually growing vocabularies without the need for retraining or large memory costs. Our training-free approach, kNN-CLIP, leverages a database of instance embeddings to enable open-vocabulary segmentation approaches to continually expand their vocabulary on any given domain with a single-pass through data, while only storing embeddings minimizing both compute and memory costs. This method achieves state-of-the-art mIoU performance across large-vocabulary semantic and panoptic segmentation datasets. We hope kNN-CLIP represents a step forward in enabling more efficient and adaptable continual segmentation, paving the way for advances in real-world large-vocabulary continual segmentation methods.
4/16/2024

The Neglected Tails in Vision-Language Models
Shubham Parashar, Zhiqiu Lin, Tian Liu, Xiangjue Dong, Yanan Li, Deva Ramanan, James Caverlee, Shu Kong
0
0
Vision-language models (VLMs) excel in zero-shot recognition but their performance varies greatly across different visual concepts. For example, although CLIP achieves impressive accuracy on ImageNet (60-80%), its performance drops below 10% for more than ten concepts like night snake, presumably due to their limited presence in the pretraining data. However, measuring the frequency of concepts in VLMs' large-scale datasets is challenging. We address this by using large language models (LLMs) to count the number of pretraining texts that contain synonyms of these concepts. Our analysis confirms that popular datasets, such as LAION, exhibit a long-tailed concept distribution, yielding biased performance in VLMs. We also find that downstream applications of VLMs, including visual chatbots (e.g., GPT-4V) and text-to-image models (e.g., Stable Diffusion), often fail to recognize or generate images of rare concepts identified by our method. To mitigate the imbalanced performance of zero-shot VLMs, we propose REtrieval-Augmented Learning (REAL). First, instead of prompting VLMs using the original class names, REAL uses their most frequent synonyms found in pretraining texts. This simple change already outperforms costly human-engineered and LLM-enriched prompts over nine benchmark datasets. Second, REAL trains a linear classifier on a small yet balanced set of pretraining data retrieved using concept synonyms. REAL surpasses the previous zero-shot SOTA, using 400x less storage and 10,000x less training time!
5/24/2024
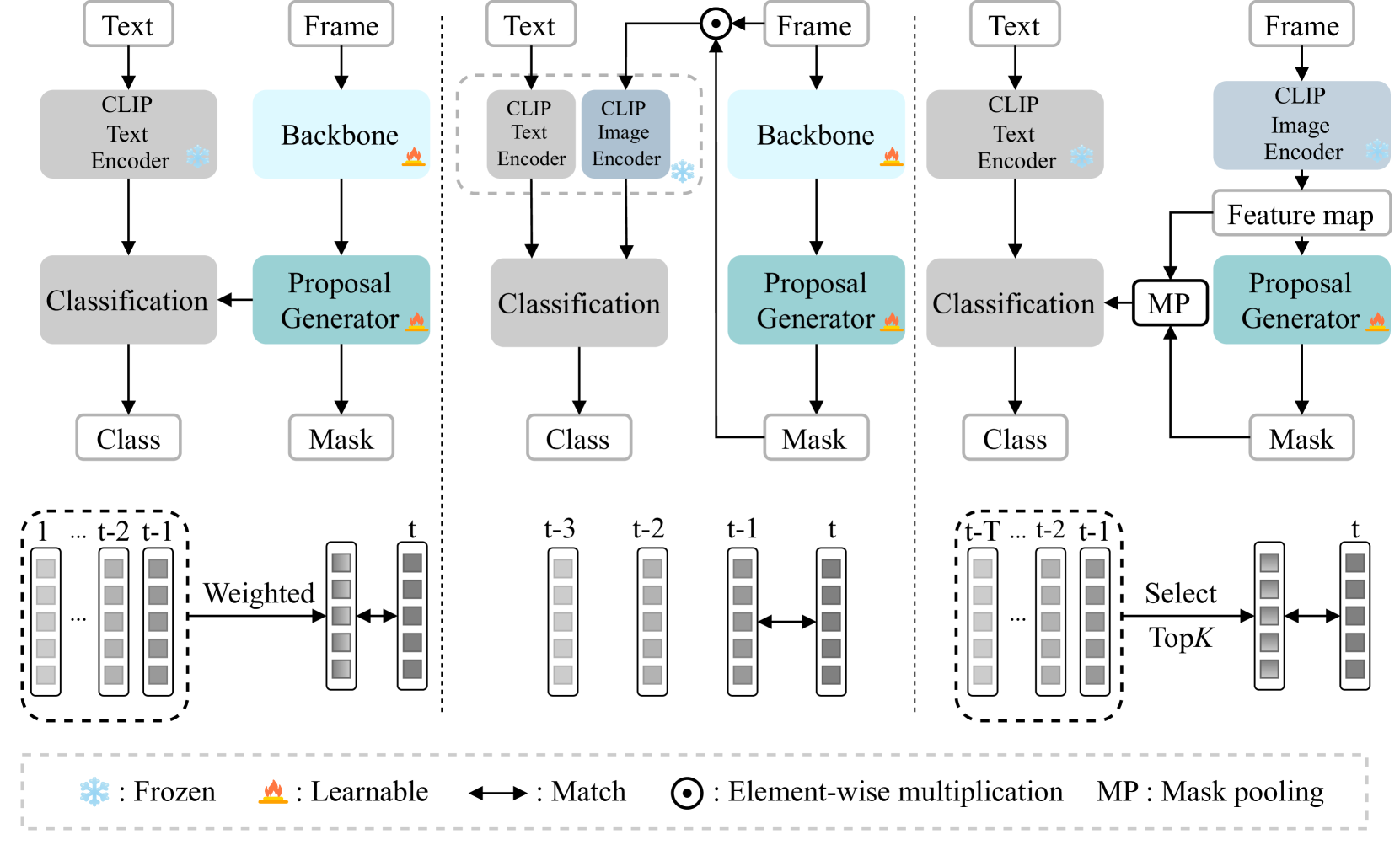
CLIP-VIS: Adapting CLIP for Open-Vocabulary Video Instance Segmentation
Wenqi Zhu, Jiale Cao, Jin Xie, Shuangming Yang, Yanwei Pang
0
0
Open-vocabulary video instance segmentation strives to segment and track instances belonging to an open set of categories in a video. The vision-language model Contrastive Language-Image Pre-training (CLIP) has shown robust zero-shot classification ability in image-level open-vocabulary task. In this paper, we propose a simple encoder-decoder network, called CLIP-VIS, to adapt CLIP for open-vocabulary video instance segmentation. Our CLIP-VIS adopts frozen CLIP image encoder and introduces three modules, including class-agnostic mask generation, temporal topK-enhanced matching, and weighted open-vocabulary classification. Given a set of initial queries, class-agnostic mask generation employs a transformer decoder to predict query masks and corresponding object scores and mask IoU scores. Then, temporal topK-enhanced matching performs query matching across frames by using K mostly matched frames. Finally, weighted open-vocabulary classification first generates query visual features with mask pooling, and second performs weighted classification using object scores and mask IoU scores.Our CLIP-VIS does not require the annotations of instance categories and identities. The experiments are performed on various video instance segmentation datasets, which demonstrate the effectiveness of our proposed method, especially on novel categories. When using ConvNeXt-B as backbone, our CLIP-VIS achieves the AP and APn scores of 32.2% and 40.2% on validation set of LV-VIS dataset, which outperforms OV2Seg by 11.1% and 23.9% respectively. We will release the source code and models at https://github.com/zwq456/CLIP-VIS.git.
6/11/2024
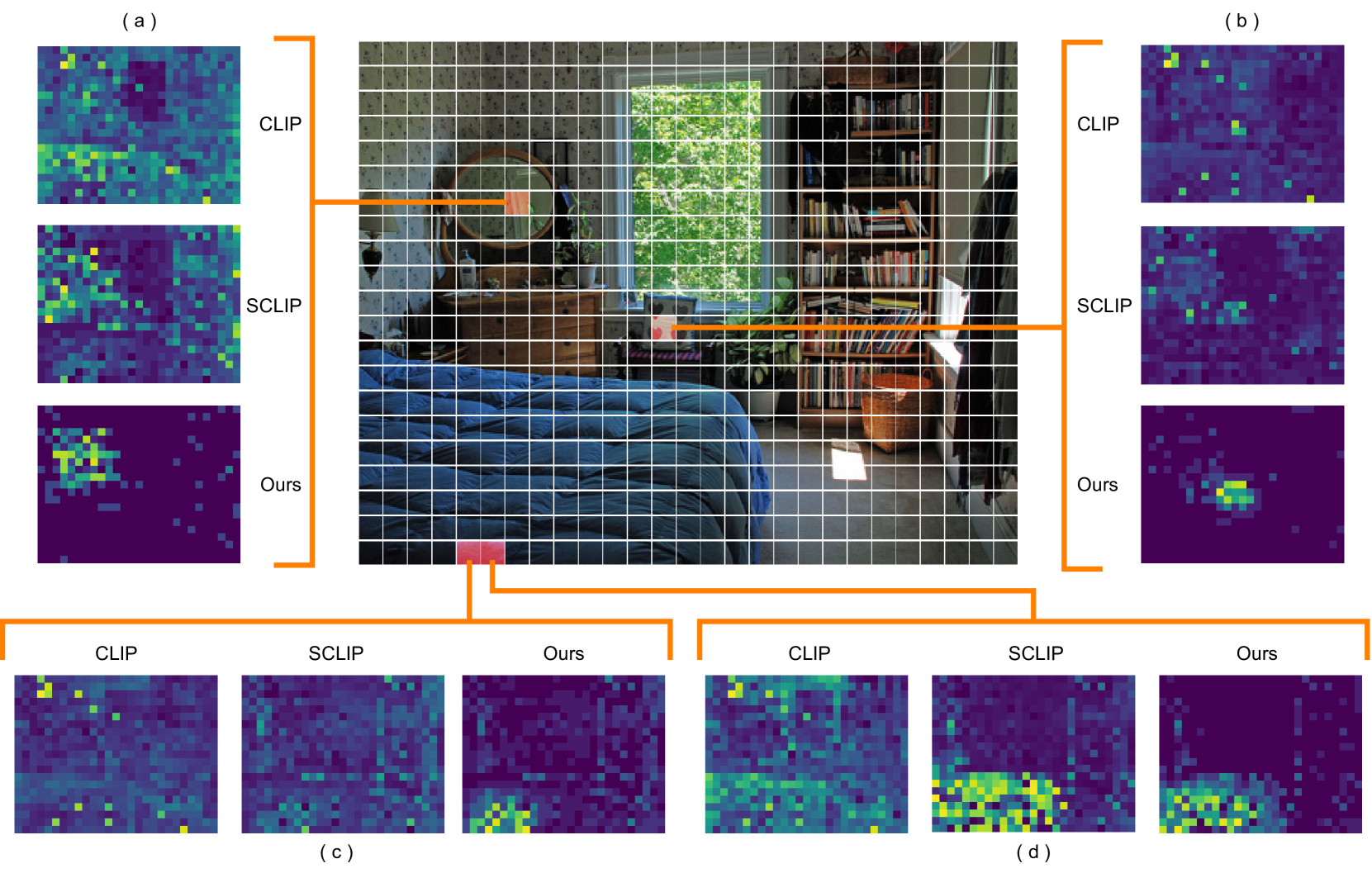
Pay Attention to Your Neighbours: Training-Free Open-Vocabulary Semantic Segmentation
Sina Hajimiri, Ismail Ben Ayed, Jose Dolz
0
0
Despite the significant progress in deep learning for dense visual recognition problems, such as semantic segmentation, traditional methods are constrained by fixed class sets. Meanwhile, vision-language foundation models, such as CLIP, have showcased remarkable effectiveness in numerous zero-shot image-level tasks, owing to their robust generalizability. Recently, a body of work has investigated utilizing these models in open-vocabulary semantic segmentation (OVSS). However, existing approaches often rely on impractical supervised pre-training or access to additional pre-trained networks. In this work, we propose a strong baseline for training-free OVSS, termed Neighbour-Aware CLIP (NACLIP), representing a straightforward adaptation of CLIP tailored for this scenario. Our method enforces localization of patches in the self-attention of CLIP's vision transformer which, despite being crucial for dense prediction tasks, has been overlooked in the OVSS literature. By incorporating design choices favouring segmentation, our approach significantly improves performance without requiring additional data, auxiliary pre-trained networks, or extensive hyperparameter tuning, making it highly practical for real-world applications. Experiments are performed on 8 popular semantic segmentation benchmarks, yielding state-of-the-art performance on most scenarios. Our code is publicly available at https://github.com/sinahmr/NACLIP .
4/15/2024