Pay Attention to Your Neighbours: Training-Free Open-Vocabulary Semantic Segmentation
2404.08181
0
0
Abstract
Despite the significant progress in deep learning for dense visual recognition problems, such as semantic segmentation, traditional methods are constrained by fixed class sets. Meanwhile, vision-language foundation models, such as CLIP, have showcased remarkable effectiveness in numerous zero-shot image-level tasks, owing to their robust generalizability. Recently, a body of work has investigated utilizing these models in open-vocabulary semantic segmentation (OVSS). However, existing approaches often rely on impractical supervised pre-training or access to additional pre-trained networks. In this work, we propose a strong baseline for training-free OVSS, termed Neighbour-Aware CLIP (NACLIP), representing a straightforward adaptation of CLIP tailored for this scenario. Our method enforces localization of patches in the self-attention of CLIP's vision transformer which, despite being crucial for dense prediction tasks, has been overlooked in the OVSS literature. By incorporating design choices favouring segmentation, our approach significantly improves performance without requiring additional data, auxiliary pre-trained networks, or extensive hyperparameter tuning, making it highly practical for real-world applications. Experiments are performed on 8 popular semantic segmentation benchmarks, yielding state-of-the-art performance on most scenarios. Our code is publicly available at https://github.com/sinahmr/NACLIP .
Create account to get full access
Overview
- This paper proposes a novel approach called "Pay Attention to Your Neighbours" (PATN) for open-vocabulary semantic segmentation, which can identify objects without requiring any training on specific object categories.
- PATN leverages the structural similarities between objects to enable zero-shot transfer of segmentation knowledge, allowing it to recognize and segment novel object instances at inference time.
- The method is training-free, meaning it does not require any object-specific training data or fine-tuning, making it highly flexible and scalable.
Plain English Explanation
The paper introduces a new way to perform semantic segmentation - the task of identifying and outlining different objects in an image. Typically, semantic segmentation models need to be trained on many examples of specific object categories to learn how to recognize them. However, this paper's approach, called "Pay Attention to Your Neighbours" (PATN), can identify objects without any prior training.
The key insight behind PATN is that objects often have structural similarities, even if they belong to different categories. For example, a chair and a table may both have four legs and a flat surface. PATN leverages these similarities to transfer knowledge about how to segment one object to recognizing similar, but previously unseen, objects. This allows PATN to identify and outline novel object instances at inference time, without requiring any object-specific training data or fine-tuning.
This "training-free" approach, similar to other recent work, makes PATN highly flexible and scalable, as it can be applied to a wide range of object categories without the need for extensive dataset curation and model retraining.
Technical Explanation
The paper introduces a novel method called "Pay Attention to Your Neighbours" (PATN) for open-vocabulary semantic segmentation. Unlike traditional semantic segmentation models, PATN can recognize and segment objects without any prior training on specific object categories.
PATN achieves this by learning to leverage the structural similarities between objects, even across different categories. The core of the PATN architecture is a Transformer-based attention module that captures contextual relationships between image regions. This allows the model to transfer segmentation knowledge from known objects to similar but novel instances, enabling zero-shot recognition and segmentation.
PATN is also training-free, meaning it does not require any object-specific training data or fine-tuning. This makes the approach highly flexible and scalable, as it can be applied to a wide range of object categories without the need for expensive dataset curation and model retraining.
Critical Analysis
The authors provide a thorough evaluation of PATN's performance on several benchmark datasets, demonstrating its effectiveness in open-vocabulary semantic segmentation tasks. However, the paper does not address some potential limitations of the approach.
One concern is the reliance on structural similarities between objects. While this enables zero-shot transfer, it may limit PATN's ability to accurately segment objects with more unique or complex shapes. The paper does not explore how PATN would perform on a wider range of object types, including those with less obvious structural similarities.
Additionally, the training-free nature of PATN could make it less robust to certain types of image variations, such as changes in lighting, occlusion, or background clutter. The paper does not provide a detailed analysis of PATN's performance under these challenging conditions, which would be important for real-world deployment.
Overall, the PATN approach represents an interesting and promising step towards more flexible and scalable semantic segmentation. However, further research is needed to fully understand the strengths, weaknesses, and broader applicability of this training-free, open-vocabulary technique.
Conclusion
This paper introduces a novel approach called "Pay Attention to Your Neighbours" (PATN) for open-vocabulary semantic segmentation. PATN can recognize and segment objects without any prior training on specific object categories, leveraging the structural similarities between objects to enable zero-shot transfer of segmentation knowledge.
The training-free nature of PATN makes it highly flexible and scalable, as it can be applied to a wide range of object categories without the need for extensive dataset curation and model retraining. This represents an important step towards more accessible and adaptable semantic segmentation models, with potential applications in areas such as robotics, autonomous driving, and image analysis.
While the paper provides a strong technical evaluation of PATN's performance, further research is needed to fully understand the strengths, weaknesses, and broader applicability of this approach, particularly in challenging real-world conditions. Nonetheless, the PATN method showcases the potential of leveraging structural similarities to enable open-vocabulary recognition, and it is an exciting development in the field of computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
CLIP-VIS: Adapting CLIP for Open-Vocabulary Video Instance Segmentation
Wenqi Zhu, Jiale Cao, Jin Xie, Shuangming Yang, Yanwei Pang
0
0
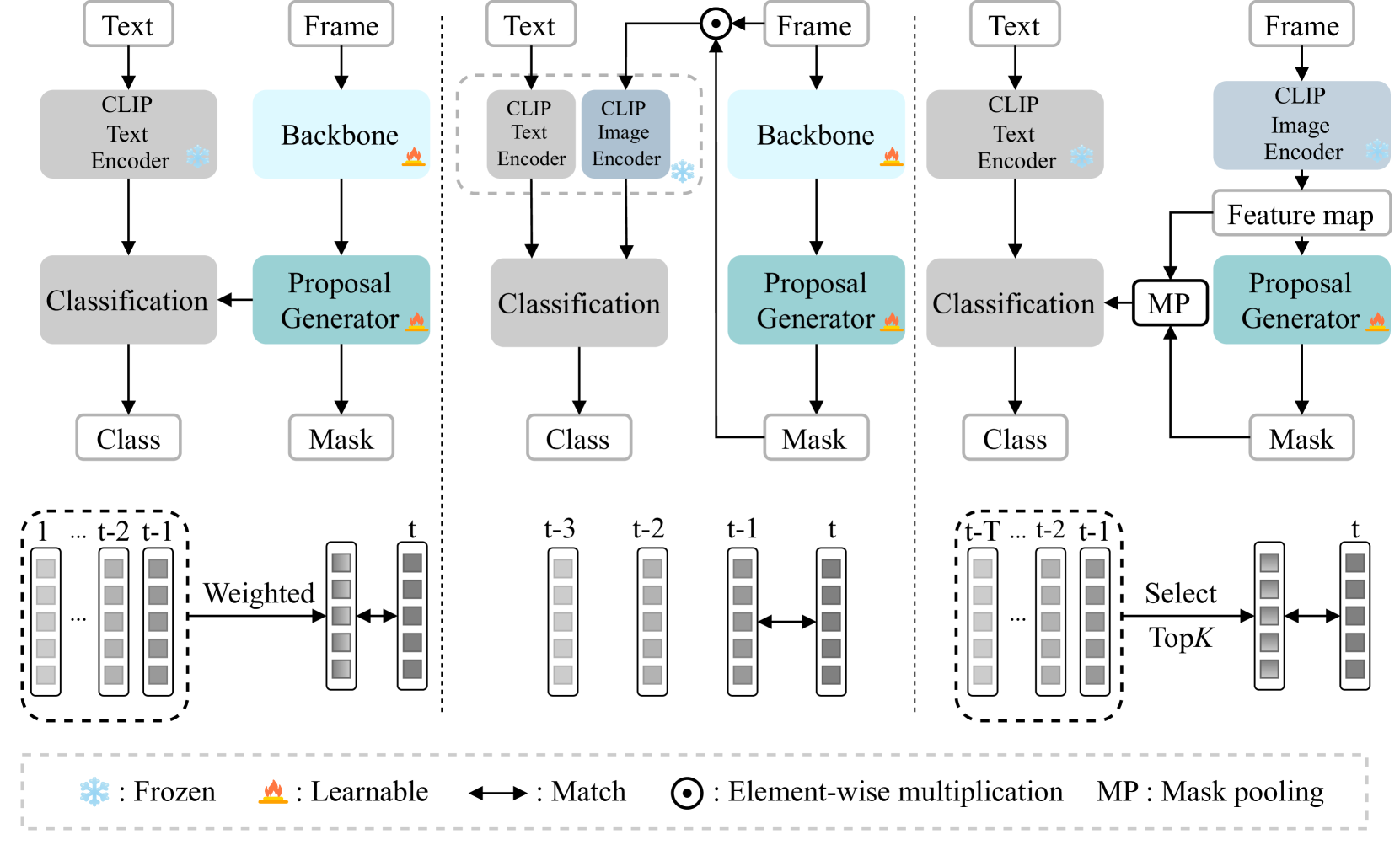
Open-vocabulary video instance segmentation strives to segment and track instances belonging to an open set of categories in a video. The vision-language model Contrastive Language-Image Pre-training (CLIP) has shown robust zero-shot classification ability in image-level open-vocabulary task. In this paper, we propose a simple encoder-decoder network, called CLIP-VIS, to adapt CLIP for open-vocabulary video instance segmentation. Our CLIP-VIS adopts frozen CLIP image encoder and introduces three modules, including class-agnostic mask generation, temporal topK-enhanced matching, and weighted open-vocabulary classification. Given a set of initial queries, class-agnostic mask generation employs a transformer decoder to predict query masks and corresponding object scores and mask IoU scores. Then, temporal topK-enhanced matching performs query matching across frames by using K mostly matched frames. Finally, weighted open-vocabulary classification first generates query visual features with mask pooling, and second performs weighted classification using object scores and mask IoU scores.Our CLIP-VIS does not require the annotations of instance categories and identities. The experiments are performed on various video instance segmentation datasets, which demonstrate the effectiveness of our proposed method, especially on novel categories. When using ConvNeXt-B as backbone, our CLIP-VIS achieves the AP and APn scores of 32.2% and 40.2% on validation set of LV-VIS dataset, which outperforms OV2Seg by 11.1% and 23.9% respectively. We will release the source code and models at https://github.com/zwq456/CLIP-VIS.git.
6/11/2024
⛏️
Tuning-free Universally-Supervised Semantic Segmentation
Xiaobo Yang, Xiaojin Gong
0
0
This work presents a tuning-free semantic segmentation framework based on classifying SAM masks by CLIP, which is universally applicable to various types of supervision. Initially, we utilize CLIP's zero-shot classification ability to generate pseudo-labels or perform open-vocabulary segmentation. However, the misalignment between mask and CLIP text embeddings leads to suboptimal results. To address this issue, we propose discrimination-bias aligned CLIP to closely align mask and text embedding, offering an overhead-free performance gain. We then construct a global-local consistent classifier to classify SAM masks, which reveals the intrinsic structure of high-quality embeddings produced by DBA-CLIP and demonstrates robustness against noisy pseudo-labels. Extensive experiments validate the efficiency and effectiveness of our method, and we achieve state-of-the-art (SOTA) or competitive performance across various datasets and supervision types.
5/24/2024

Emergent Open-Vocabulary Semantic Segmentation from Off-the-shelf Vision-Language Models
Jiayun Luo, Siddhesh Khandelwal, Leonid Sigal, Boyang Li
0
0
From image-text pairs, large-scale vision-language models (VLMs) learn to implicitly associate image regions with words, which prove effective for tasks like visual question answering. However, leveraging the learned association for open-vocabulary semantic segmentation remains a challenge. In this paper, we propose a simple, yet extremely effective, training-free technique, Plug-and-Play Open-Vocabulary Semantic Segmentation (PnP-OVSS) for this task. PnP-OVSS leverages a VLM with direct text-to-image cross-attention and an image-text matching loss. To balance between over-segmentation and under-segmentation, we introduce Salience Dropout; by iteratively dropping patches that the model is most attentive to, we are able to better resolve the entire extent of the segmentation mask. PnP-OVSS does not require any neural network training and performs hyperparameter tuning without the need for any segmentation annotations, even for a validation set. PnP-OVSS demonstrates substantial improvements over comparable baselines (+26.2% mIoU on Pascal VOC, +20.5% mIoU on MS COCO, +3.1% mIoU on COCO Stuff and +3.0% mIoU on ADE20K). Our codebase is at https://github.com/letitiabanana/PnP-OVSS.
6/18/2024

kNN-CLIP: Retrieval Enables Training-Free Segmentation on Continually Expanding Large Vocabularies
Zhongrui Gui, Shuyang Sun, Runjia Li, Jianhao Yuan, Zhaochong An, Karsten Roth, Ameya Prabhu, Philip Torr
0
0
Rapid advancements in continual segmentation have yet to bridge the gap of scaling to large continually expanding vocabularies under compute-constrained scenarios. We discover that traditional continual training leads to catastrophic forgetting under compute constraints, unable to outperform zero-shot segmentation methods. We introduce a novel strategy for semantic and panoptic segmentation with zero forgetting, capable of adapting to continually growing vocabularies without the need for retraining or large memory costs. Our training-free approach, kNN-CLIP, leverages a database of instance embeddings to enable open-vocabulary segmentation approaches to continually expand their vocabulary on any given domain with a single-pass through data, while only storing embeddings minimizing both compute and memory costs. This method achieves state-of-the-art mIoU performance across large-vocabulary semantic and panoptic segmentation datasets. We hope kNN-CLIP represents a step forward in enabling more efficient and adaptable continual segmentation, paving the way for advances in real-world large-vocabulary continual segmentation methods.
4/16/2024