CLIP-CID: Efficient CLIP Distillation via Cluster-Instance Discrimination

0
Sign in to get full access
Overview
- The paper introduces CLIP-CID, a method for efficiently distilling knowledge from a large and powerful CLIP (Contrastive Language-Image Pretraining) model to a smaller and faster student model.
- CLIP-CID uses a novel Cluster-Instance Discrimination (CID) approach to effectively transfer the learned CLIP knowledge.
- The authors show that CLIP-CID outperforms existing CLIP distillation methods, while being computationally efficient and requiring less training time.
Plain English Explanation
The researchers developed a new way to take the knowledge learned by a large and complex AI model called CLIP and transfer it to a smaller, simpler model. CLIP is a powerful AI system that can understand and process both text and images, but it is large and slow to use. The goal was to create a smaller, faster model that could still benefit from CLIP's capabilities.
The key innovation in their approach, called CLIP-CID, is a "Cluster-Instance Discrimination" technique. This means the smaller model learns not just to mimic the outputs of the larger CLIP model, but also to recognize the underlying structure and relationships in the data.
By capturing this deeper understanding, the smaller model can achieve better performance than previous CLIP distillation methods, while still being much faster and more efficient to use. This could enable the benefits of CLIP to be deployed more widely, in applications where the large model would be too slow or resource-intensive.
Technical Explanation
The paper introduces CLIP-CID, a novel knowledge distillation method for efficiently transferring the capabilities of a large CLIP model to a smaller student model.
The key innovation is the use of Cluster-Instance Discrimination (CID), which encourages the student model to not only mimic the outputs of the teacher CLIP model, but also to learn the underlying cluster structure and relationships in the data. This is achieved by having the student model learn to:
- Classify each input into the correct cluster learned by the teacher model.
- Distinguish each individual input instance from other instances within the same cluster.
This CID objective, combined with a standard distillation loss, allows the student model to capture richer information from the teacher beyond just output predictions. The authors show that this results in superior performance compared to prior CLIP distillation methods, while being more computationally efficient and requiring less training time.
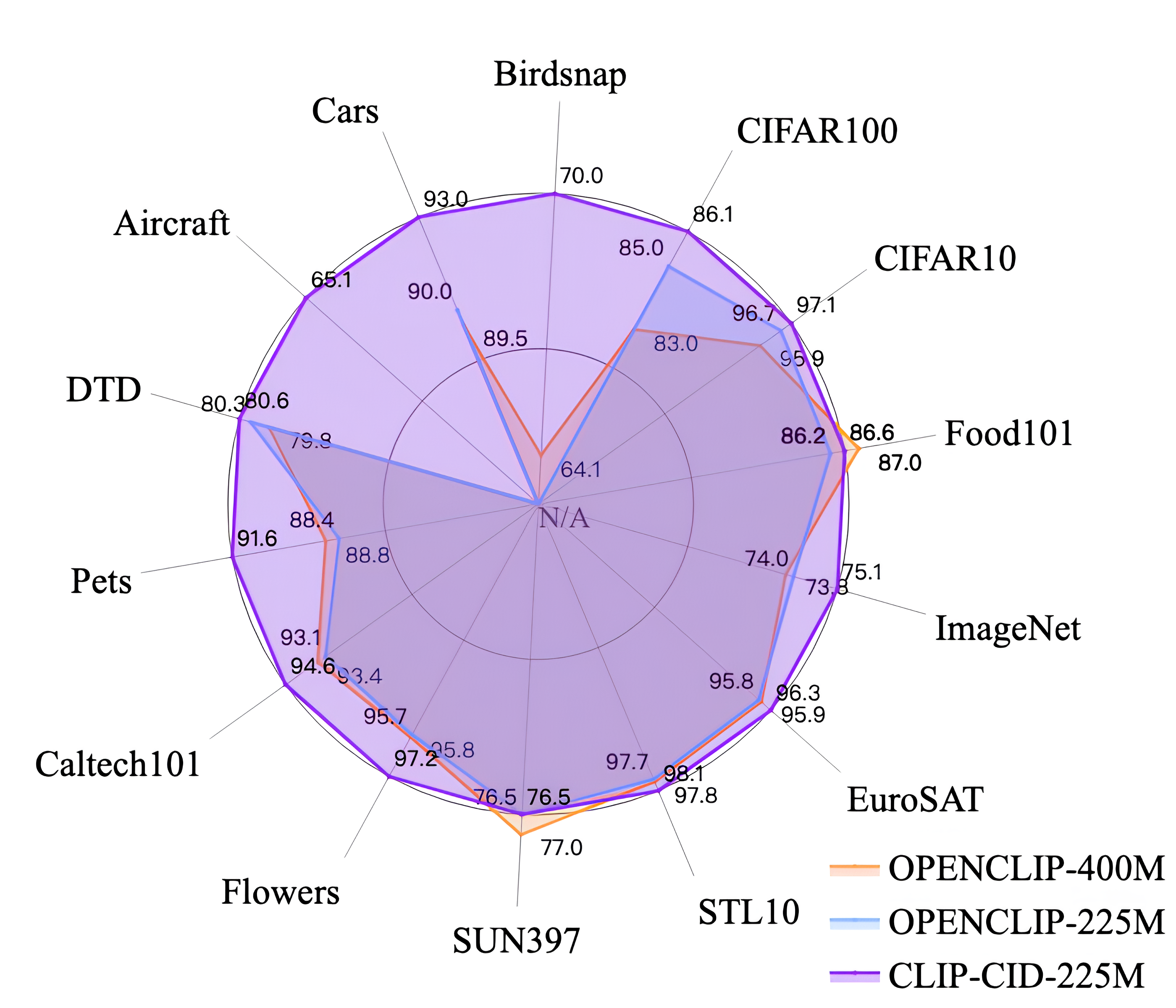
Experiments on various image classification benchmarks demonstrate the effectiveness of CLIP-CID. The student model achieves comparable or better accuracy than the teacher CLIP model, while being significantly smaller and faster.
Critical Analysis
The authors provide a thorough evaluation of CLIP-CID and demonstrate its advantages over previous CLIP distillation approaches. However, the paper does not extensively discuss potential limitations or caveats of the proposed method.
One area that could be explored further is the sensitivity of CLIP-CID to the quality and diversity of the training data. The performance of the distilled model may be dependent on how well the training data covers the distribution of the target task.
Additionally, the paper focuses on image classification tasks, and it would be valuable to investigate the effectiveness of CLIP-CID for other modalities, such as text-based tasks or multimodal applications.
Overall, the CLIP-CID method presents a promising approach for efficiently leveraging the capabilities of large, powerful models like CLIP, and the authors have demonstrated its strong empirical performance. Further research into its robustness and broader applicability could provide valuable insights.
Conclusion
The paper introduces CLIP-CID, a novel knowledge distillation method that allows for efficient transfer of knowledge from a large CLIP model to a smaller, more computationally efficient student model. The key contribution is the use of Cluster-Instance Discrimination, which enables the student model to capture richer information from the teacher beyond just output predictions.
The authors show that CLIP-CID outperforms previous CLIP distillation approaches, while being more computationally efficient and requiring less training time. This advance could enable the benefits of large, powerful models like CLIP to be more widely deployed in real-world applications that require faster and more resource-efficient inference.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CLIP-CID: Efficient CLIP Distillation via Cluster-Instance Discrimination
Kaicheng Yang, Tiancheng Gu, Xiang An, Haiqiang Jiang, Xiangzi Dai, Ziyong Feng, Weidong Cai, Jiankang Deng
Contrastive Language-Image Pre-training (CLIP) has achieved excellent performance over a wide range of tasks. However, the effectiveness of CLIP heavily relies on a substantial corpus of pre-training data, resulting in notable consumption of computational resources. Although knowledge distillation has been widely applied in single modality models, how to efficiently expand knowledge distillation to vision-language foundation models with extensive data remains relatively unexplored. In this paper, we introduce CLIP-CID, a novel distillation mechanism that effectively transfers knowledge from a large vision-language foundation model to a smaller model. We initially propose a simple but efficient image semantic balance method to reduce transfer learning bias and improve distillation efficiency. This method filters out 43.7% of image-text pairs from the LAION400M while maintaining superior performance. After that, we leverage cluster-instance discrimination to facilitate knowledge transfer from the teacher model to the student model, thereby empowering the student model to acquire a holistic semantic comprehension of the pre-training data. Experimental results demonstrate that CLIP-CID achieves state-of-the-art performance on various downstream tasks including linear probe and zero-shot classification.
Read more8/20/2024
📈
0
CLIP-KD: An Empirical Study of CLIP Model Distillation
Chuanguang Yang, Zhulin An, Libo Huang, Junyu Bi, Xinqiang Yu, Han Yang, Boyu Diao, Yongjun Xu
Contrastive Language-Image Pre-training (CLIP) has become a promising language-supervised visual pre-training framework. This paper aims to distill small CLIP models supervised by a large teacher CLIP model. We propose several distillation strategies, including relation, feature, gradient and contrastive paradigms, to examine the effectiveness of CLIP-Knowledge Distillation (KD). We show that a simple feature mimicry with Mean Squared Error loss works surprisingly well. Moreover, interactive contrastive learning across teacher and student encoders is also effective in performance improvement. We explain that the success of CLIP-KD can be attributed to maximizing the feature similarity between teacher and student. The unified method is applied to distill several student models trained on CC3M+12M. CLIP-KD improves student CLIP models consistently over zero-shot ImageNet classification and cross-modal retrieval benchmarks. When using ViT-L/14 pretrained on Laion-400M as the teacher, CLIP-KD achieves 57.5% and 55.4% zero-shot top-1 ImageNet accuracy over ViT-B/16 and ResNet-50, surpassing the original CLIP without KD by 20.5% and 20.1% margins, respectively. Our code is released on https://github.com/winycg/CLIP-KD.
Read more5/8/2024

0
ComKD-CLIP: Comprehensive Knowledge Distillation for Contrastive Language-Image Pre-traning Model
Yifan Chen, Xiaozhen Qiao, Zhe Sun, Xuelong Li
Contrastive Language-Image Pre-training (CLIP) models excel in integrating semantic information between images and text through contrastive learning techniques. It has achieved remarkable performance in various multimodal tasks. However, the deployment of large CLIP models is hindered in resource-limited environments, while smaller models frequently fail to meet the performance benchmarks required for practical applications. In this paper, we propose a novel approach, ComKD-CLIP: Comprehensive Knowledge Distillation for Contrastive Language-Image Pre-traning Model, which aims to comprehensively distill the knowledge from a large teacher CLIP model into a smaller student model, ensuring comparable performance with significantly reduced parameters. ComKD-CLIP is composed of two key mechanisms: Image Feature Alignment (IFAlign) and Educational Attention (EduAttention). IFAlign makes the image features extracted by the student model closely match those extracted by the teacher model, enabling the student to learn teacher's knowledge of extracting image features. EduAttention explores the cross-relationships between text features extracted by the teacher model and image features extracted by the student model, enabling the student model to learn how the teacher model integrates text-image features. In addition, ComKD-CLIP can refine the knowledge distilled from IFAlign and EduAttention by leveraging the text-image feature fusion results of the teacher model, ensuring the student model accurately absorbs the teacher's knowledge. Extensive experiments conducted on 11 datasets have demonstrated the superiority of the proposed method.
Read more8/22/2024
✨
0
Distilling Knowledge from Text-to-Image Generative Models Improves Visio-Linguistic Reasoning in CLIP
Samyadeep Basu, Shell Xu Hu, Maziar Sanjabi, Daniela Massiceti, Soheil Feizi
Image-text contrastive models like CLIP have wide applications in zero-shot classification, image-text retrieval, and transfer learning. However, they often struggle on compositional visio-linguistic tasks (e.g., attribute-binding or object-relationships) where their performance is no better than random chance. To address this, we introduce SDS-CLIP, a lightweight and sample-efficient distillation method to enhance CLIP's compositional visio-linguistic reasoning. Our approach fine-tunes CLIP using a distillation objective borrowed from large text-to-image generative models like Stable-Diffusion, which are known for their strong visio-linguistic reasoning abilities. On the challenging Winoground benchmark, SDS-CLIP improves the visio-linguistic performance of various CLIP models by up to 7%, while on the ARO dataset, it boosts performance by up to 3%. This work underscores the potential of well-designed distillation objectives from generative models to enhance contrastive image-text models with improved visio-linguistic reasoning capabilities.
Read more7/2/2024