CLIP-GS: CLIP-Informed Gaussian Splatting for Real-time and View-consistent 3D Semantic Understanding
2404.14249
0
0

Abstract
The recent 3D Gaussian Splatting (GS) exhibits high-quality and real-time synthesis of novel views in 3D scenes. Currently, it primarily focuses on geometry and appearance modeling, while lacking the semantic understanding of scenes. To bridge this gap, we present CLIP-GS, which integrates semantics from Contrastive Language-Image Pre-Training (CLIP) into Gaussian Splatting to efficiently comprehend 3D environments without annotated semantic data. In specific, rather than straightforwardly learning and rendering high-dimensional semantic features of 3D Gaussians, which significantly diminishes the efficiency, we propose a Semantic Attribute Compactness (SAC) approach. SAC exploits the inherent unified semantics within objects to learn compact yet effective semantic representations of 3D Gaussians, enabling highly efficient rendering (>100 FPS). Additionally, to address the semantic ambiguity, caused by utilizing view-inconsistent 2D CLIP semantics to supervise Gaussians, we introduce a 3D Coherent Self-training (3DCS) strategy, resorting to the multi-view consistency originated from the 3D model. 3DCS imposes cross-view semantic consistency constraints by leveraging refined, self-predicted pseudo-labels derived from the trained 3D Gaussian model, thereby enhancing precise and view-consistent segmentation results. Extensive experiments demonstrate that our method remarkably outperforms existing state-of-the-art approaches, achieving improvements of 17.29% and 20.81% in mIoU metric on Replica and ScanNet datasets, respectively, while maintaining real-time rendering speed. Furthermore, our approach exhibits superior performance even with sparse input data, verifying the robustness of our method.
Create account to get full access
Overview
- This paper introduces CLIP-GS, a novel approach for real-time and view-consistent 3D semantic understanding using a combination of CLIP (Contrastive Language-Image Pre-training) and Gaussian splatting.
- CLIP-GS leverages CLIP's ability to embed 2D images and their associated captions to provide semantic information for 3D point clouds, while Gaussian splatting is used to efficiently represent and process the 3D data.
- The proposed method aims to enable high-quality 3D semantic segmentation and scene understanding that is robust to changes in viewpoint.
Plain English Explanation
CLIP-GS: CLIP-Informed Gaussian Splatting for Real-time and View-consistent 3D Semantic Understanding is a new technique that combines two powerful ideas to help computers better understand 3D scenes.
The first part is CLIP, which is a machine learning model that can connect images with the words that describe them. This allows the computer to understand the meaning and content of 2D images.
The second part is Gaussian splatting, which is a way of efficiently representing 3D data, like the points that make up a 3D scene, using Gaussian "blobs" or splatats.
By combining these two ideas, the researchers created a new system called CLIP-GS that can take 3D point cloud data and use CLIP to understand what the 3D scene contains, even as the viewpoint changes. This allows for high-quality 3D semantic segmentation, where the computer can identify and label different objects and elements in the 3D scene.
The 3D geometry-aware deformable Gaussian splatting approach used in CLIP-GS also helps make the system efficient and able to run in real-time, which is important for applications like robotics and augmented reality.
Technical Explanation
The key innovation in CLIP-GS: CLIP-Informed Gaussian Splatting for Real-time and View-consistent 3D Semantic Understanding is the integration of CLIP, a powerful language-vision model, with Gaussian splatting, an efficient 3D representation technique.
CLIP is used to provide semantic information for 3D point clouds by embedding the 2D images and their associated captions. This allows the system to leverage CLIP's ability to associate visual content with natural language descriptions. The sparse-controlled Gaussian splatting (SC-GS) approach is then used to represent the 3D data, enabling efficient processing and view-consistent 3D semantic understanding.
The paper presents a detailed architecture for CLIP-GS, which includes a CLIP-based semantic encoder, a 3D geometry-aware deformable Gaussian splatting module, and a semantic fusion component. Extensive experiments demonstrate CLIP-GS's ability to achieve real-time performance and view-consistent 3D semantic segmentation, outperforming state-of-the-art methods.
Critical Analysis
The CLIP-GS paper presents a compelling approach for addressing the challenge of real-time and view-consistent 3D semantic understanding. The authors' integration of CLIP and Gaussian splatting is a novel and promising direction, leveraging the strengths of both techniques.
One potential limitation is the reliance on 2D images and captions to provide semantic information for the 3D point clouds. While this approach allows CLIP-GS to benefit from the rich semantic knowledge captured by CLIP, it may not fully capture the nuances and context of the 3D scene. Exploring ways to directly incorporate 3D semantic information could be an area for future research.
Additionally, the paper focuses on evaluating CLIP-GS on standard benchmarks, but it would be interesting to see how the system performs in more real-world, dynamic scenarios, where the ability to maintain view consistency could be particularly valuable, such as in robotics or augmented reality applications.
Overall, the CLIP-GS paper represents an important step forward in the field of 3D semantic understanding, and the authors' innovative approach holds promise for enabling more effective and efficient 3D scene analysis.
Conclusion
The CLIP-GS paper introduces a novel technique that combines CLIP, a powerful language-vision model, with Gaussian splatting, an efficient 3D representation method, to enable real-time and view-consistent 3D semantic understanding. By leveraging CLIP's semantic knowledge and the advantages of Gaussian splatting, CLIP-GS achieves state-of-the-art performance in 3D semantic segmentation tasks.
This work highlights the potential of integrating advanced machine learning models, such as CLIP, with specialized 3D processing techniques to unlock new capabilities in areas like robotics, augmented reality, and digital twins. As the field of 3D scene understanding continues to evolve, the CLIP-GS approach represents an important contribution that could inspire further advancements in this rapidly growing area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SA-GS: Semantic-Aware Gaussian Splatting for Large Scene Reconstruction with Geometry Constrain
Butian Xiong, Xiaoyu Ye, Tze Ho Elden Tse, Kai Han, Shuguang Cui, Zhen Li
0
0
With the emergence of Gaussian Splats, recent efforts have focused on large-scale scene geometric reconstruction. However, most of these efforts either concentrate on memory reduction or spatial space division, neglecting information in the semantic space. In this paper, we propose a novel method, named SA-GS, for fine-grained 3D geometry reconstruction using semantic-aware 3D Gaussian Splats. Specifically, we leverage prior information stored in large vision models such as SAM and DINO to generate semantic masks. We then introduce a geometric complexity measurement function to serve as soft regularization, guiding the shape of each Gaussian Splat within specific semantic areas. Additionally, we present a method that estimates the expected number of Gaussian Splats in different semantic areas, effectively providing a lower bound for Gaussian Splats in these areas. Subsequently, we extract the point cloud using a novel probability density-based extraction method, transforming Gaussian Splats into a point cloud crucial for downstream tasks. Our method also offers the potential for detailed semantic inquiries while maintaining high image-based reconstruction results. We provide extensive experiments on publicly available large-scale scene reconstruction datasets with highly accurate point clouds as ground truth and our novel dataset. Our results demonstrate the superiority of our method over current state-of-the-art Gaussian Splats reconstruction methods by a significant margin in terms of geometric-based measurement metrics. Code and additional results will soon be available on our project page.
5/29/2024
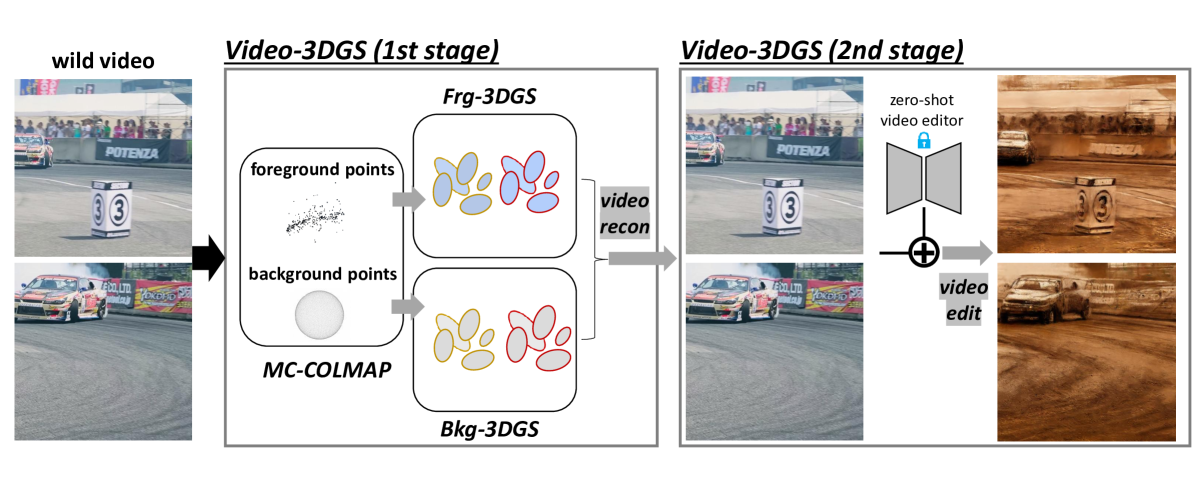
Enhancing Temporal Consistency in Video Editing by Reconstructing Videos with 3D Gaussian Splatting
Inkyu Shin, Qihang Yu, Xiaohui Shen, In So Kweon, Kuk-Jin Yoon, Liang-Chieh Chen
0
0
Recent advancements in zero-shot video diffusion models have shown promise for text-driven video editing, but challenges remain in achieving high temporal consistency. To address this, we introduce Video-3DGS, a 3D Gaussian Splatting (3DGS)-based video refiner designed to enhance temporal consistency in zero-shot video editors. Our approach utilizes a two-stage 3D Gaussian optimizing process tailored for editing dynamic monocular videos. In the first stage, Video-3DGS employs an improved version of COLMAP, referred to as MC-COLMAP, which processes original videos using a Masked and Clipped approach. For each video clip, MC-COLMAP generates the point clouds for dynamic foreground objects and complex backgrounds. These point clouds are utilized to initialize two sets of 3D Gaussians (Frg-3DGS and Bkg-3DGS) aiming to represent foreground and background views. Both foreground and background views are then merged with a 2D learnable parameter map to reconstruct full views. In the second stage, we leverage the reconstruction ability developed in the first stage to impose the temporal constraints on the video diffusion model. To demonstrate the efficacy of Video-3DGS on both stages, we conduct extensive experiments across two related tasks: Video Reconstruction and Video Editing. Video-3DGS trained with 3k iterations significantly improves video reconstruction quality (+3 PSNR, +7 PSNR increase) and training efficiency (x1.9, x4.5 times faster) over NeRF-based and 3DGS-based state-of-art methods on DAVIS dataset, respectively. Moreover, it enhances video editing by ensuring temporal consistency across 58 dynamic monocular videos.
6/7/2024

View-Consistent 3D Editing with Gaussian Splatting
Yuxuan Wang, Xuanyu Yi, Zike Wu, Na Zhao, Long Chen, Hanwang Zhang
0
0
The advent of 3D Gaussian Splatting (3DGS) has revolutionized 3D editing, offering efficient, high-fidelity rendering and enabling precise local manipulations. Currently, diffusion-based 2D editing models are harnessed to modify multi-view rendered images, which then guide the editing of 3DGS models. However, this approach faces a critical issue of multi-view inconsistency, where the guidance images exhibit significant discrepancies across views, leading to mode collapse and visual artifacts of 3DGS. To this end, we introduce View-consistent Editing (VcEdit), a novel framework that seamlessly incorporates 3DGS into image editing processes, ensuring multi-view consistency in edited guidance images and effectively mitigating mode collapse issues. VcEdit employs two innovative consistency modules: the Cross-attention Consistency Module and the Editing Consistency Module, both designed to reduce inconsistencies in edited images. By incorporating these consistency modules into an iterative pattern, VcEdit proficiently resolves the issue of multi-view inconsistency, facilitating high-quality 3DGS editing across a diverse range of scenes. Further code and video results are re- leased at http://yuxuanw.me/vcedit/.
5/22/2024
RT-GS2: Real-Time Generalizable Semantic Segmentation for 3D Gaussian Representations of Radiance Fields
Mihnea-Bogdan Jurca, Remco Royen, Ion Giosan, Adrian Munteanu
0
0
Gaussian Splatting has revolutionized the world of novel view synthesis by achieving high rendering performance in real-time. Recently, studies have focused on enriching these 3D representations with semantic information for downstream tasks. In this paper, we introduce RT-GS2, the first generalizable semantic segmentation method employing Gaussian Splatting. While existing Gaussian Splatting-based approaches rely on scene-specific training, RT-GS2 demonstrates the ability to generalize to unseen scenes. Our method adopts a new approach by first extracting view-independent 3D Gaussian features in a self-supervised manner, followed by a novel View-Dependent / View-Independent (VDVI) feature fusion to enhance semantic consistency over different views. Extensive experimentation on three different datasets showcases RT-GS2's superiority over the state-of-the-art methods in semantic segmentation quality, exemplified by a 8.01% increase in mIoU on the Replica dataset. Moreover, our method achieves real-time performance of 27.03 FPS, marking an astonishing 901 times speedup compared to existing approaches. This work represents a significant advancement in the field by introducing, to the best of our knowledge, the first real-time generalizable semantic segmentation method for 3D Gaussian representations of radiance fields.
5/29/2024