RT-GS2: Real-Time Generalizable Semantic Segmentation for 3D Gaussian Representations of Radiance Fields
2405.18033
0
0
Abstract
Gaussian Splatting has revolutionized the world of novel view synthesis by achieving high rendering performance in real-time. Recently, studies have focused on enriching these 3D representations with semantic information for downstream tasks. In this paper, we introduce RT-GS2, the first generalizable semantic segmentation method employing Gaussian Splatting. While existing Gaussian Splatting-based approaches rely on scene-specific training, RT-GS2 demonstrates the ability to generalize to unseen scenes. Our method adopts a new approach by first extracting view-independent 3D Gaussian features in a self-supervised manner, followed by a novel View-Dependent / View-Independent (VDVI) feature fusion to enhance semantic consistency over different views. Extensive experimentation on three different datasets showcases RT-GS2's superiority over the state-of-the-art methods in semantic segmentation quality, exemplified by a 8.01% increase in mIoU on the Replica dataset. Moreover, our method achieves real-time performance of 27.03 FPS, marking an astonishing 901 times speedup compared to existing approaches. This work represents a significant advancement in the field by introducing, to the best of our knowledge, the first real-time generalizable semantic segmentation method for 3D Gaussian representations of radiance fields.
Create account to get full access
Overview
- This paper introduces RT-GS2, a real-time generalizable semantic segmentation model for 3D Gaussian representations of radiance fields.
- The model leverages a novel 3D Gaussian splatting architecture to enable fast and efficient inference on 3D data.
- The paper demonstrates the effectiveness of RT-GS2 on various 3D semantic segmentation benchmarks, showcasing its ability to outperform state-of-the-art methods in terms of both accuracy and inference speed.
Plain English Explanation
RT-GS2 is a machine learning model that can quickly and accurately understand the contents of 3D scenes. It works by representing the 3D world as a collection of Gaussian "blobs" that capture the shape and appearance of objects. The model is trained to recognize different types of objects, like people, cars, or buildings, within this 3D Gaussian representation.
One of the key innovations of RT-GS2 is its speed. Traditional 3D segmentation models can be slow, making them impractical for many real-world applications. RT-GS2, on the other hand, is designed to run in real-time, allowing it to be used in scenarios like self-driving cars or augmented reality applications where fast, accurate analysis of the 3D environment is crucial.
The model's generalizability is another important aspect. It can be applied to a wide variety of 3D scenes, from indoor spaces to outdoor environments, without needing to be retrained for each new setting. This makes RT-GS2 a versatile tool that can be deployed in many different contexts.
Overall, RT-GS2 represents an important advancement in the field of 3D perception, making it possible to understand the contents of complex 3D scenes quickly and accurately. This could have significant implications for a range of applications, from autonomous navigation to interactive augmented reality experiences.
Technical Explanation
The core of RT-GS2 is a novel 3D Gaussian splatting architecture that allows for efficient processing of 3D data. The model takes as input a 3D scene represented as a set of Gaussian "blobs" that encode information about the shape, appearance, and spatial relationships of objects in the environment.
The RT-GS2 network then applies a series of 3D convolutional layers to extract features from this Gaussian representation. These features are then used to predict a semantic segmentation map, where each voxel in the 3D scene is assigned a class label (e.g., "person," "car," "building").
The authors demonstrate the effectiveness of RT-GS2 on a range of 3D semantic segmentation benchmarks, including Feature-3DGS, SA-GS, and SparseGS. The model outperforms state-of-the-art methods in terms of both accuracy and inference speed, highlighting its potential for real-world applications.
The authors also discuss the broader implications of their work, noting its connections to other 3D perception tasks like RT-SLAM and its relevance to the growing body of research on 3D Gaussian splatting.
Critical Analysis
The authors provide a thorough evaluation of RT-GS2, demonstrating its strong performance across a range of 3D semantic segmentation benchmarks. However, the paper does not address potential limitations or areas for further research.
One potential concern is the model's reliance on a Gaussian representation of the 3D world. While this approach has proven effective, it may struggle to capture complex geometric structures or fine-grained details that are better represented using other 3D data formats, such as point clouds or meshes.
Additionally, the paper does not discuss the model's sensitivity to noise or missing data, which can be a critical factor in real-world applications where sensor data may be imperfect or incomplete.
Further research could explore ways to incorporate more diverse 3D representations into the RT-GS2 architecture or to make the model more robust to challenging real-world conditions. Investigating the model's generalization capabilities across a wider range of environments and tasks could also be a fruitful direction for future work.
Conclusion
In conclusion, RT-GS2 represents an important advancement in the field of 3D perception, offering a fast and generalizable approach to semantic segmentation of 3D Gaussian representations of radiance fields. The model's strong performance on benchmark tasks and its potential for real-time applications make it a promising tool for a range of emerging technologies, from autonomous vehicles to interactive augmented reality experiences.
While the paper does not address all of the potential limitations of the approach, the core innovations of RT-GS2 highlight the ongoing progress in the field of 3D machine learning and the growing importance of efficient and versatile 3D perception models for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
Feature 3DGS: Supercharging 3D Gaussian Splatting to Enable Distilled Feature Fields
Shijie Zhou, Haoran Chang, Sicheng Jiang, Zhiwen Fan, Zehao Zhu, Dejia Xu, Pradyumna Chari, Suya You, Zhangyang Wang, Achuta Kadambi
0
0
3D scene representations have gained immense popularity in recent years. Methods that use Neural Radiance fields are versatile for traditional tasks such as novel view synthesis. In recent times, some work has emerged that aims to extend the functionality of NeRF beyond view synthesis, for semantically aware tasks such as editing and segmentation using 3D feature field distillation from 2D foundation models. However, these methods have two major limitations: (a) they are limited by the rendering speed of NeRF pipelines, and (b) implicitly represented feature fields suffer from continuity artifacts reducing feature quality. Recently, 3D Gaussian Splatting has shown state-of-the-art performance on real-time radiance field rendering. In this work, we go one step further: in addition to radiance field rendering, we enable 3D Gaussian splatting on arbitrary-dimension semantic features via 2D foundation model distillation. This translation is not straightforward: naively incorporating feature fields in the 3DGS framework encounters significant challenges, notably the disparities in spatial resolution and channel consistency between RGB images and feature maps. We propose architectural and training changes to efficiently avert this problem. Our proposed method is general, and our experiments showcase novel view semantic segmentation, language-guided editing and segment anything through learning feature fields from state-of-the-art 2D foundation models such as SAM and CLIP-LSeg. Across experiments, our distillation method is able to provide comparable or better results, while being significantly faster to both train and render. Additionally, to the best of our knowledge, we are the first method to enable point and bounding-box prompting for radiance field manipulation, by leveraging the SAM model. Project website at: https://feature-3dgs.github.io/
4/9/2024

SA-GS: Semantic-Aware Gaussian Splatting for Large Scene Reconstruction with Geometry Constrain
Butian Xiong, Xiaoyu Ye, Tze Ho Elden Tse, Kai Han, Shuguang Cui, Zhen Li
0
0
With the emergence of Gaussian Splats, recent efforts have focused on large-scale scene geometric reconstruction. However, most of these efforts either concentrate on memory reduction or spatial space division, neglecting information in the semantic space. In this paper, we propose a novel method, named SA-GS, for fine-grained 3D geometry reconstruction using semantic-aware 3D Gaussian Splats. Specifically, we leverage prior information stored in large vision models such as SAM and DINO to generate semantic masks. We then introduce a geometric complexity measurement function to serve as soft regularization, guiding the shape of each Gaussian Splat within specific semantic areas. Additionally, we present a method that estimates the expected number of Gaussian Splats in different semantic areas, effectively providing a lower bound for Gaussian Splats in these areas. Subsequently, we extract the point cloud using a novel probability density-based extraction method, transforming Gaussian Splats into a point cloud crucial for downstream tasks. Our method also offers the potential for detailed semantic inquiries while maintaining high image-based reconstruction results. We provide extensive experiments on publicly available large-scale scene reconstruction datasets with highly accurate point clouds as ground truth and our novel dataset. Our results demonstrate the superiority of our method over current state-of-the-art Gaussian Splats reconstruction methods by a significant margin in terms of geometric-based measurement metrics. Code and additional results will soon be available on our project page.
5/29/2024
2D Gaussian Splatting for Geometrically Accurate Radiance Fields
Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, Shenghua Gao
0
0
3D Gaussian Splatting (3DGS) has recently revolutionized radiance field reconstruction, achieving high quality novel view synthesis and fast rendering speed without baking. However, 3DGS fails to accurately represent surfaces due to the multi-view inconsistent nature of 3D Gaussians. We present 2D Gaussian Splatting (2DGS), a novel approach to model and reconstruct geometrically accurate radiance fields from multi-view images. Our key idea is to collapse the 3D volume into a set of 2D oriented planar Gaussian disks. Unlike 3D Gaussians, 2D Gaussians provide view-consistent geometry while modeling surfaces intrinsically. To accurately recover thin surfaces and achieve stable optimization, we introduce a perspective-correct 2D splatting process utilizing ray-splat intersection and rasterization. Additionally, we incorporate depth distortion and normal consistency terms to further enhance the quality of the reconstructions. We demonstrate that our differentiable renderer allows for noise-free and detailed geometry reconstruction while maintaining competitive appearance quality, fast training speed, and real-time rendering.
6/11/2024
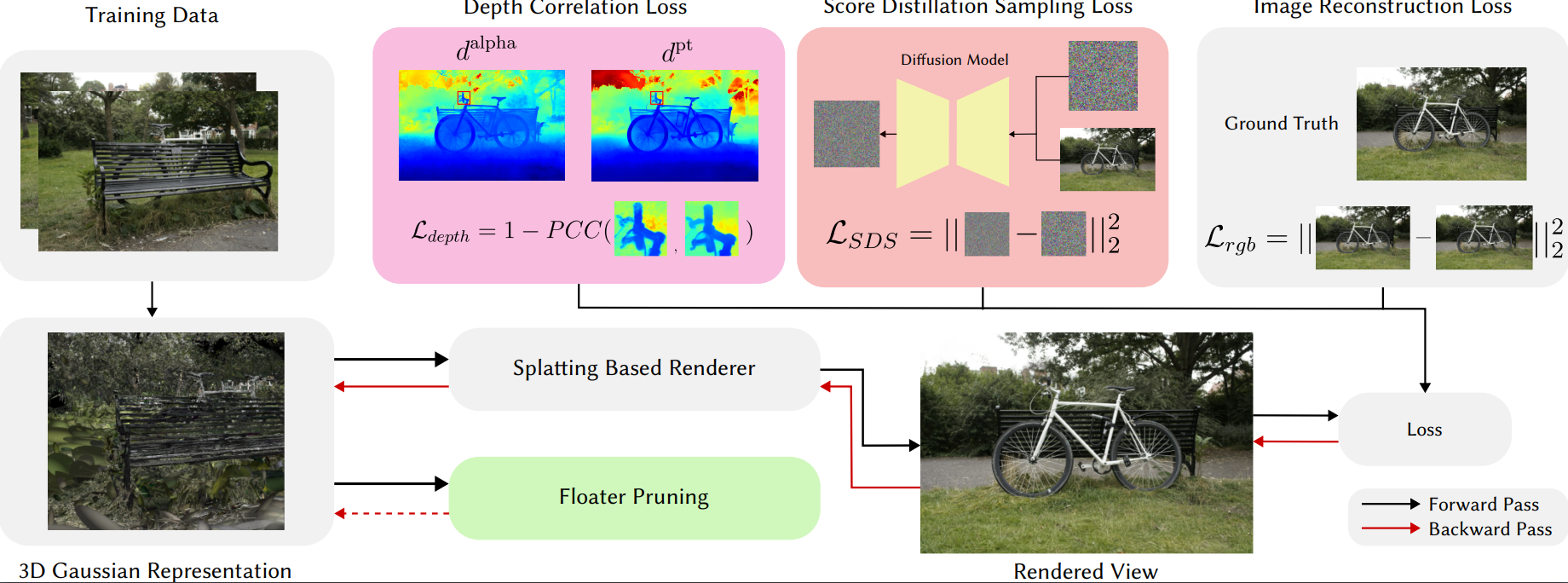
SparseGS: Real-Time 360{deg} Sparse View Synthesis using Gaussian Splatting
Haolin Xiong, Sairisheek Muttukuru, Rishi Upadhyay, Pradyumna Chari, Achuta Kadambi
0
0
The problem of novel view synthesis has grown significantly in popularity recently with the introduction of Neural Radiance Fields (NeRFs) and other implicit scene representation methods. A recent advance, 3D Gaussian Splatting (3DGS), leverages an explicit representation to achieve real-time rendering with high-quality results. However, 3DGS still requires an abundance of training views to generate a coherent scene representation. In few shot settings, similar to NeRF, 3DGS tends to overfit to training views, causing background collapse and excessive floaters, especially as the number of training views are reduced. We propose a method to enable training coherent 3DGS-based radiance fields of 360-degree scenes from sparse training views. We integrate depth priors with generative and explicit constraints to reduce background collapse, remove floaters, and enhance consistency from unseen viewpoints. Experiments show that our method outperforms base 3DGS by 6.4% in LPIPS and by 12.2% in PSNR, and NeRF-based methods by at least 17.6% in LPIPS on the MipNeRF-360 dataset with substantially less training and inference cost.
5/14/2024