SA-GS: Semantic-Aware Gaussian Splatting for Large Scene Reconstruction with Geometry Constrain
2405.16923
0
0

Abstract
With the emergence of Gaussian Splats, recent efforts have focused on large-scale scene geometric reconstruction. However, most of these efforts either concentrate on memory reduction or spatial space division, neglecting information in the semantic space. In this paper, we propose a novel method, named SA-GS, for fine-grained 3D geometry reconstruction using semantic-aware 3D Gaussian Splats. Specifically, we leverage prior information stored in large vision models such as SAM and DINO to generate semantic masks. We then introduce a geometric complexity measurement function to serve as soft regularization, guiding the shape of each Gaussian Splat within specific semantic areas. Additionally, we present a method that estimates the expected number of Gaussian Splats in different semantic areas, effectively providing a lower bound for Gaussian Splats in these areas. Subsequently, we extract the point cloud using a novel probability density-based extraction method, transforming Gaussian Splats into a point cloud crucial for downstream tasks. Our method also offers the potential for detailed semantic inquiries while maintaining high image-based reconstruction results. We provide extensive experiments on publicly available large-scale scene reconstruction datasets with highly accurate point clouds as ground truth and our novel dataset. Our results demonstrate the superiority of our method over current state-of-the-art Gaussian Splats reconstruction methods by a significant margin in terms of geometric-based measurement metrics. Code and additional results will soon be available on our project page.
Create account to get full access
Overview
• This paper presents a new approach called SA-GS: Semantic-Aware Gaussian Splatting for Large Scene Reconstruction with Geometry Constrain, which aims to improve the accuracy and efficiency of 3D scene reconstruction.
• The key ideas are to leverage semantic information and geometry constraints to enhance the Gaussian splatting process, a popular technique for dense 3D reconstruction.
• The proposed method is evaluated on large-scale indoor and outdoor scenes, demonstrating improved performance compared to existing approaches.
Plain English Explanation
The paper introduces a new technique called Semantic-Aware Gaussian Splatting (SA-GS) for creating 3D models of large scenes, such as buildings or outdoor environments. 3D reconstruction is the process of generating a three-dimensional digital representation of a real-world object or environment from sensor data, like camera images.
The core idea behind SA-GS is to use semantic information, which is data about the meaning or categorization of different elements in the scene (e.g., identifying objects as walls, floors, furniture, etc.). This semantic understanding is combined with geometric constraints, which are rules about the expected shapes and relationships of objects, to improve the accuracy and efficiency of the 3D reconstruction process.
Specifically, the method enhances a technique called "Gaussian splatting," which is a way of representing 3D data by using overlapping Gaussian distribution functions. By incorporating semantic awareness and geometric constraints into this process, the researchers were able to create more accurate 3D models of large, complex scenes compared to previous approaches.
The authors evaluate their method on indoor and outdoor environments, showing that it outperforms existing techniques in terms of reconstruction quality and computational efficiency. This could have applications in areas like virtual reality, autonomous navigation, and urban planning, where accurate and detailed 3D models of real-world spaces are highly valuable.
Technical Explanation
The paper introduces a new approach called SA-GS: Semantic-Aware Gaussian Splatting for Large Scene Reconstruction with Geometry Constrain. This method builds upon the CLIP-GS: CLIP-Informed Gaussian Splatting for Real-time 3D Reconstruction and SA-GS: Structure-Aware 3D Gaussian Splatting techniques, which use Gaussian splatting for dense 3D reconstruction.
The key innovations of SA-GS are:
-
Semantic Awareness: The method leverages semantic information about the scene, such as object categories (e.g., wall, floor, furniture), to guide the Gaussian splatting process. This helps the algorithm better understand the underlying structure of the environment.
-
Geometry Constraints: SA-GS incorporates geometric constraints, such as the expected shapes and relationships of objects, to further refine the 3D reconstruction. This helps the model generate more accurate and plausible 3D models.
The authors evaluate their approach on large-scale indoor and outdoor scenes, comparing it to GS-SLAM: Dense Visual SLAM with 3D Gaussian, 3D Geometry-Aware Deformable Gaussian Splatting for Dynamic, and SC-GS: Sparse Controlled Gaussian Splatting for Editable scenes. The results demonstrate that SA-GS achieves improved reconstruction quality and computational efficiency compared to these baseline methods.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the SA-GS method, including comparisons to several state-of-the-art techniques. The authors acknowledge that their approach relies on the availability of semantic information, which may not always be readily available in real-world scenarios.
One potential limitation is that the method may struggle with highly dynamic or deformable scenes, as the geometric constraints are primarily focused on static structures. Further research could explore ways to extend the approach to handle more complex and changing environments.
Additionally, the paper does not provide a detailed analysis of the computational complexity or runtime performance of SA-GS compared to the baselines. This information would be valuable for understanding the practical applicability of the method, especially in real-time or resource-constrained settings.
Overall, the proposed SA-GS technique represents a promising advancement in 3D reconstruction, leveraging semantic understanding and geometry constraints to enhance the Gaussian splatting process. The authors have made a significant contribution to the field, and the insights from this work could inspire further developments in this area.
Conclusion
The SA-GS: Semantic-Aware Gaussian Splatting for Large Scene Reconstruction with Geometry Constrain paper presents a novel approach to 3D reconstruction that combines semantic information and geometric constraints to improve the accuracy and efficiency of the Gaussian splatting technique.
The key innovations include leveraging semantic awareness to better understand the scene structure and incorporating geometric constraints to generate more plausible 3D models. The authors' evaluation on large-scale indoor and outdoor scenes demonstrates the effectiveness of their method compared to existing techniques.
This research has important implications for various applications that rely on accurate 3D reconstruction, such as virtual reality, autonomous navigation, and urban planning. By enhancing the quality and efficiency of 3D modeling, the SA-GS approach could contribute to the development of more advanced and reliable systems in these domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CLIP-GS: CLIP-Informed Gaussian Splatting for Real-time and View-consistent 3D Semantic Understanding
Guibiao Liao, Jiankun Li, Zhenyu Bao, Xiaoqing Ye, Jingdong Wang, Qing Li, Kanglin Liu
0
0
The recent 3D Gaussian Splatting (GS) exhibits high-quality and real-time synthesis of novel views in 3D scenes. Currently, it primarily focuses on geometry and appearance modeling, while lacking the semantic understanding of scenes. To bridge this gap, we present CLIP-GS, which integrates semantics from Contrastive Language-Image Pre-Training (CLIP) into Gaussian Splatting to efficiently comprehend 3D environments without annotated semantic data. In specific, rather than straightforwardly learning and rendering high-dimensional semantic features of 3D Gaussians, which significantly diminishes the efficiency, we propose a Semantic Attribute Compactness (SAC) approach. SAC exploits the inherent unified semantics within objects to learn compact yet effective semantic representations of 3D Gaussians, enabling highly efficient rendering (>100 FPS). Additionally, to address the semantic ambiguity, caused by utilizing view-inconsistent 2D CLIP semantics to supervise Gaussians, we introduce a 3D Coherent Self-training (3DCS) strategy, resorting to the multi-view consistency originated from the 3D model. 3DCS imposes cross-view semantic consistency constraints by leveraging refined, self-predicted pseudo-labels derived from the trained 3D Gaussian model, thereby enhancing precise and view-consistent segmentation results. Extensive experiments demonstrate that our method remarkably outperforms existing state-of-the-art approaches, achieving improvements of 17.29% and 20.81% in mIoU metric on Replica and ScanNet datasets, respectively, while maintaining real-time rendering speed. Furthermore, our approach exhibits superior performance even with sparse input data, verifying the robustness of our method.
4/23/2024
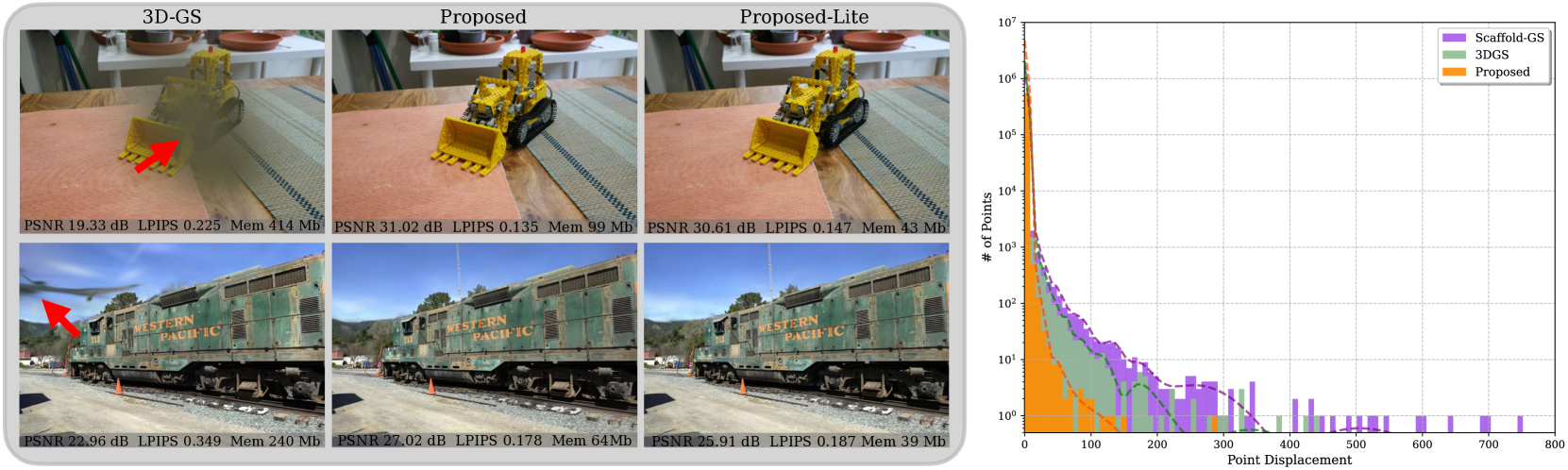
SAGS: Structure-Aware 3D Gaussian Splatting
Evangelos Ververas, Rolandos Alexandros Potamias, Jifei Song, Jiankang Deng, Stefanos Zafeiriou
0
0
Following the advent of NeRFs, 3D Gaussian Splatting (3D-GS) has paved the way to real-time neural rendering overcoming the computational burden of volumetric methods. Following the pioneering work of 3D-GS, several methods have attempted to achieve compressible and high-fidelity performance alternatives. However, by employing a geometry-agnostic optimization scheme, these methods neglect the inherent 3D structure of the scene, thereby restricting the expressivity and the quality of the representation, resulting in various floating points and artifacts. In this work, we propose a structure-aware Gaussian Splatting method (SAGS) that implicitly encodes the geometry of the scene, which reflects to state-of-the-art rendering performance and reduced storage requirements on benchmark novel-view synthesis datasets. SAGS is founded on a local-global graph representation that facilitates the learning of complex scenes and enforces meaningful point displacements that preserve the scene's geometry. Additionally, we introduce a lightweight version of SAGS, using a simple yet effective mid-point interpolation scheme, which showcases a compact representation of the scene with up to 24$times$ size reduction without the reliance on any compression strategies. Extensive experiments across multiple benchmark datasets demonstrate the superiority of SAGS compared to state-of-the-art 3D-GS methods under both rendering quality and model size. Besides, we demonstrate that our structure-aware method can effectively mitigate floating artifacts and irregular distortions of previous methods while obtaining precise depth maps. Project page https://eververas.github.io/SAGS/.
5/1/2024

Superpoint Gaussian Splatting for Real-Time High-Fidelity Dynamic Scene Reconstruction
Diwen Wan, Ruijie Lu, Gang Zeng
0
0
Rendering novel view images in dynamic scenes is a crucial yet challenging task. Current methods mainly utilize NeRF-based methods to represent the static scene and an additional time-variant MLP to model scene deformations, resulting in relatively low rendering quality as well as slow inference speed. To tackle these challenges, we propose a novel framework named Superpoint Gaussian Splatting (SP-GS). Specifically, our framework first employs explicit 3D Gaussians to reconstruct the scene and then clusters Gaussians with similar properties (e.g., rotation, translation, and location) into superpoints. Empowered by these superpoints, our method manages to extend 3D Gaussian splatting to dynamic scenes with only a slight increase in computational expense. Apart from achieving state-of-the-art visual quality and real-time rendering under high resolutions, the superpoint representation provides a stronger manipulation capability. Extensive experiments demonstrate the practicality and effectiveness of our approach on both synthetic and real-world datasets. Please see our project page at https://dnvtmf.github.io/SP_GS.github.io.
6/7/2024
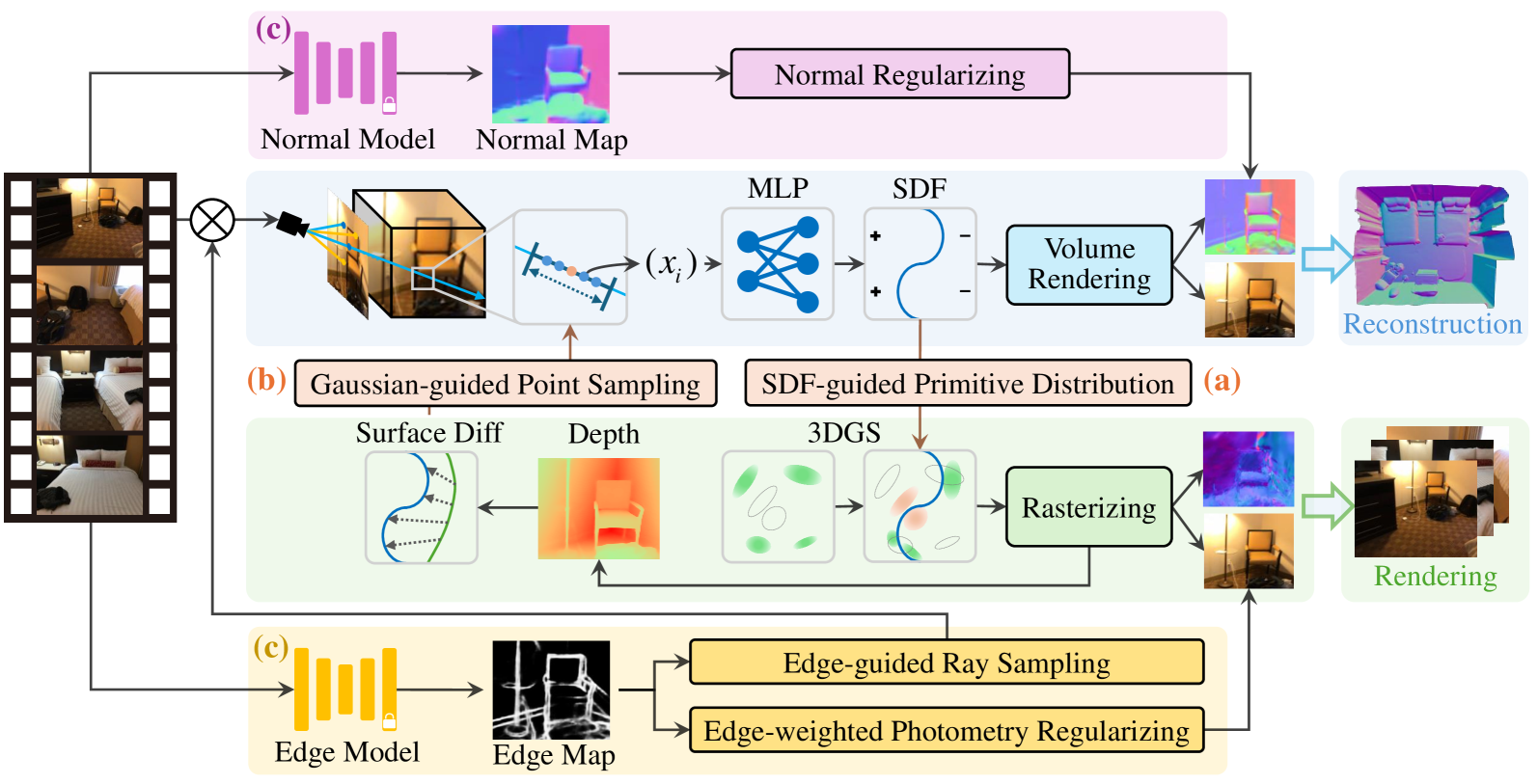
GaussianRoom: Improving 3D Gaussian Splatting with SDF Guidance and Monocular Cues for Indoor Scene Reconstruction
Haodong Xiang, Xinghui Li, Xiansong Lai, Wanting Zhang, Zhichao Liao, Kai Cheng, Xueping Liu
0
0
Recently, 3D Gaussian Splatting(3DGS) has revolutionized neural rendering with its high-quality rendering and real-time speed. However, when it comes to indoor scenes with a significant number of textureless areas, 3DGS yields incomplete and noisy reconstruction results due to the poor initialization of the point cloud and under-constrained optimization. Inspired by the continuity of signed distance field (SDF), which naturally has advantages in modeling surfaces, we present a unified optimizing framework integrating neural SDF with 3DGS. This framework incorporates a learnable neural SDF field to guide the densification and pruning of Gaussians, enabling Gaussians to accurately model scenes even with poor initialized point clouds. At the same time, the geometry represented by Gaussians improves the efficiency of the SDF field by piloting its point sampling. Additionally, we regularize the optimization with normal and edge priors to eliminate geometry ambiguity in textureless areas and improve the details. Extensive experiments in ScanNet and ScanNet++ show that our method achieves state-of-the-art performance in both surface reconstruction and novel view synthesis.
5/31/2024