CLIPVQA:Video Quality Assessment via CLIP

0

Sign in to get full access
Overview
- This paper presents CLIPVQA, a video quality assessment (VQA) model that leverages the Contrastive Language-Image Pre-training (CLIP) framework.
- CLIPVQA is designed to assess the quality of "in-the-wild" videos, which are often captured in uncontrolled environments with varying conditions.
- The model uses self-attention and transformer-based architecture to effectively capture the complex relationships between video content and quality.
Plain English Explanation
CLIPVQA: Video Quality Assessment via CLIP is a new approach for evaluating the quality of videos, especially those recorded in real-world, uncontrolled settings. Traditional video quality assessment methods often struggle with these "in-the-wild" videos, which can have varying lighting, camera angles, and other factors that impact quality.
CLIPVQA tackles this challenge by leveraging the powerful CLIP (Contrastive Language-Image Pre-training) framework. CLIP is a machine learning model that has been trained on a vast amount of online data to understand the relationship between images, videos, and the words used to describe them. CLIPVQA builds on this foundation to assess video quality in a more sophisticated way.
The key innovation of CLIPVQA is its use of self-attention and transformer-based architecture. These techniques allow the model to better understand the complex relationships between the content of a video and its overall quality. By focusing on these intricate connections, CLIPVQA can provide more accurate and nuanced assessments of video quality, even for videos captured in uncontrolled, real-world conditions.
Technical Explanation
CLIPVQA: Video Quality Assessment via CLIP proposes a novel approach for video quality assessment (VQA) that leverages the Contrastive Language-Image Pre-training (CLIP) framework. The researchers designed CLIPVQA to tackle the challenge of evaluating the quality of "in-the-wild" videos, which are often captured in uncontrolled environments with varying lighting, camera angles, and other factors that can impact quality.
At the core of CLIPVQA is a self-attention-based transformer architecture that allows the model to effectively capture the complex relationships between video content and quality. The researchers fine-tuned the pre-trained CLIP model on a large-scale video quality dataset, enabling CLIPVQA to leverage the powerful cross-modal understanding learned by CLIP during its pre-training.
Through extensive experiments, the authors demonstrate that CLIPVQA outperforms state-of-the-art VQA methods on several benchmark datasets, including those focused on in-the-wild videos. The model's strong performance is attributed to its ability to learn rich video representations and effectively model the nuanced connections between video content and quality.
Critical Analysis
The CLIPVQA: Video Quality Assessment via CLIP paper presents a compelling approach to video quality assessment, leveraging the strengths of the CLIP framework to tackle the challenges of evaluating in-the-wild videos. The use of self-attention and transformer-based architecture is a well-justified choice, as these techniques have proven effective in modeling complex visual and textual relationships.
One potential limitation of the research is the reliance on pre-existing video quality datasets, which may not fully capture the diversity and complexity of real-world video scenarios. While the authors demonstrate impressive results on benchmark datasets, it would be valuable to further evaluate the model's performance on a broader range of in-the-wild videos, including those with more extreme variations in quality and content.
Additionally, the paper does not provide a detailed analysis of the model's interpretability or explainability. Understanding the specific factors and video characteristics that the model considers when assessing quality could lead to valuable insights and potential improvements.
Multiview Contrastive Learning for Completely Blind Video Quality and CLIP-Powered TASS: Target-Aware Single Stream are two related works that could provide additional perspectives and potentially complement the CLIPVQA approach.
Conclusion
CLIPVQA: Video Quality Assessment via CLIP presents a promising solution for evaluating the quality of in-the-wild videos, leveraging the power of the CLIP framework and advanced neural network architectures. By effectively modeling the complex relationships between video content and quality, CLIPVQA demonstrates significant improvements over existing VQA methods, paving the way for more accurate and reliable video quality assessment in real-world scenarios.
While the research shows promising results, further exploration of the model's interpretability and performance on a wider range of video scenarios could unlock additional insights and drive further advancements in this important field of study. As video content continues to proliferate across various platforms and applications, tools like CLIPVQA will become increasingly valuable in ensuring high-quality, engaging visual experiences for users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CLIPVQA:Video Quality Assessment via CLIP
Fengchuang Xing, Mingjie Li, Yuan-Gen Wang, Guopu Zhu, Xiaochun Cao
In learning vision-language representations from web-scale data, the contrastive language-image pre-training (CLIP) mechanism has demonstrated a remarkable performance in many vision tasks. However, its application to the widely studied video quality assessment (VQA) task is still an open issue. In this paper, we propose an efficient and effective CLIP-based Transformer method for the VQA problem (CLIPVQA). Specifically, we first design an effective video frame perception paradigm with the goal of extracting the rich spatiotemporal quality and content information among video frames. Then, the spatiotemporal quality features are adequately integrated together using a self-attention mechanism to yield video-level quality representation. To utilize the quality language descriptions of videos for supervision, we develop a CLIP-based encoder for language embedding, which is then fully aggregated with the generated content information via a cross-attention module for producing video-language representation. Finally, the video-level quality and video-language representations are fused together for final video quality prediction, where a vectorized regression loss is employed for efficient end-to-end optimization. Comprehensive experiments are conducted on eight in-the-wild video datasets with diverse resolutions to evaluate the performance of CLIPVQA. The experimental results show that the proposed CLIPVQA achieves new state-of-the-art VQA performance and up to 37% better generalizability than existing benchmark VQA methods. A series of ablation studies are also performed to validate the effectiveness of each module in CLIPVQA.
Read more7/9/2024

0
CLIP with Quality Captions: A Strong Pretraining for Vision Tasks
Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Oncel Tuzel
CLIP models perform remarkably well on zero-shot classification and retrieval tasks. But recent studies have shown that learnt representations in CLIP are not well suited for dense prediction tasks like object detection, semantic segmentation or depth estimation. More recently, multi-stage training methods for CLIP models was introduced to mitigate the weak performance of CLIP on downstream tasks. In this work, we find that simply improving the quality of captions in image-text datasets improves the quality of CLIP's visual representations, resulting in significant improvement on downstream dense prediction vision tasks. In fact, we find that CLIP pretraining with good quality captions can surpass recent supervised, self-supervised and weakly supervised pretraining methods. We show that when CLIP model with ViT-B/16 as image encoder is trained on well aligned image-text pairs it obtains 12.1% higher mIoU and 11.5% lower RMSE on semantic segmentation and depth estimation tasks over recent state-of-the-art Masked Image Modeling (MIM) pretraining methods like Masked Autoencoder (MAE). We find that mobile architectures also benefit significantly from CLIP pretraining. A recent mobile vision architecture, MCi2, with CLIP pretraining obtains similar performance as Swin-L, pretrained on ImageNet-22k for semantic segmentation task while being 6.1$times$ smaller. Moreover, we show that improving caption quality results in $10times$ data efficiency when finetuning for dense prediction tasks.
Read more5/16/2024
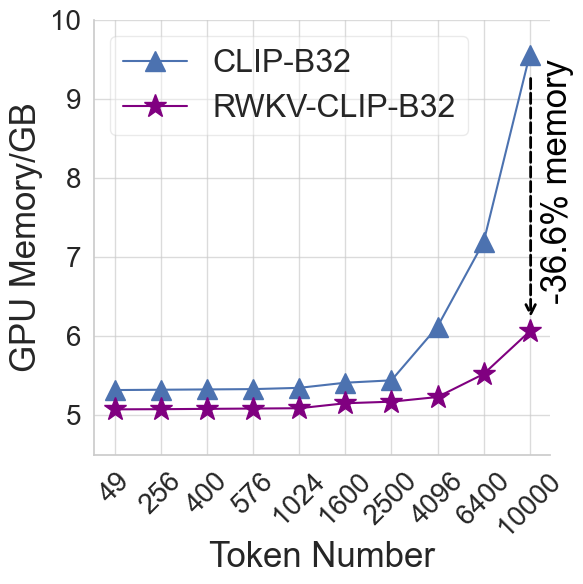
0
RWKV-CLIP: A Robust Vision-Language Representation Learner
Tiancheng Gu, Kaicheng Yang, Xiang An, Ziyong Feng, Dongnan Liu, Weidong Cai, Jiankang Deng
Contrastive Language-Image Pre-training (CLIP) has significantly improved performance in various vision-language tasks by expanding the dataset with image-text pairs obtained from websites. This paper further explores CLIP from the perspectives of data and model architecture. To address the prevalence of noisy data and enhance the quality of large-scale image-text data crawled from the internet, we introduce a diverse description generation framework that can leverage Large Language Models (LLMs) to synthesize and refine content from web-based texts, synthetic captions, and detection tags. Furthermore, we propose RWKV-CLIP, the first RWKV-driven vision-language representation learning model that combines the effective parallel training of transformers with the efficient inference of RNNs. Comprehensive experiments across various model scales and pre-training datasets demonstrate that RWKV-CLIP is a robust and efficient vision-language representation learner, it achieves state-of-the-art performance in several downstream tasks, including linear probe, zero-shot classification, and zero-shot image-text retrieval. To facilitate future research, the code and pre-trained models are released at https://github.com/deepglint/RWKV-CLIP
Read more6/12/2024

0
CLIP-AGIQA: Boosting the Performance of AI-Generated Image Quality Assessment with CLIP
Zhenchen Tang, Zichuan Wang, Bo Peng, Jing Dong
With the rapid development of generative technologies, AI-Generated Images (AIGIs) have been widely applied in various aspects of daily life. However, due to the immaturity of the technology, the quality of the generated images varies, so it is important to develop quality assessment techniques for the generated images. Although some models have been proposed to assess the quality of generated images, they are inadequate when faced with the ever-increasing and diverse categories of generated images. Consequently, the development of more advanced and effective models for evaluating the quality of generated images is urgently needed. Recent research has explored the significant potential of the visual language model CLIP in image quality assessment, finding that it performs well in evaluating the quality of natural images. However, its application to generated images has not been thoroughly investigated. In this paper, we build on this idea and further explore the potential of CLIP in evaluating the quality of generated images. We design CLIP-AGIQA, a CLIP-based regression model for quality assessment of generated images, leveraging rich visual and textual knowledge encapsulated in CLIP. Particularly, we implement multi-category learnable prompts to fully utilize the textual knowledge in CLIP for quality assessment. Extensive experiments on several generated image quality assessment benchmarks, including AGIQA-3K and AIGCIQA2023, demonstrate that CLIP-AGIQA outperforms existing IQA models, achieving excellent results in evaluating the quality of generated images.
Read more8/28/2024