CLIP-Powered TASS: Target-Aware Single-Stream Network for Audio-Visual Question Answering

0
🌐
Sign in to get full access
Overview
- The paper explores the potential of vision-language pretrained models (VLMs) in audio-visual question answering (AVQA), a task that requires fine-grained audio-visual reasoning.
- Previous AVQA methods have limitations, such as underutilizing the knowledge of CLIP models and treating audio and video as separate entities.
- The proposed solution, CLIP-powered target-aware single-stream (TASS) network, aims to address these challenges.
Plain English Explanation
The paper looks at how well-trained models that can understand both images and language (VLMs) can be used for a specific task called audio-visual question answering (AVQA). AVQA involves answering questions that require carefully examining both the visual and audio information in a video.
Previous methods for AVQA had some issues. They didn't fully take advantage of the knowledge stored in CLIP, a popular VLM model. They also treated the audio and video parts of a video as completely separate, even though they're naturally connected.
The researchers propose a new model called TASS that tries to fix these problems. TASS has two key components:
-
Target-aware Spatial Grounding (TSG+): This module allows TASS to transfer the image-text matching knowledge from CLIP to the process of matching regions in the video to the relevant text, without needing labeled data.
-
Single-stream Joint Temporal Grounding (JTG): Instead of keeping audio and video separate, JTG treats them as a single, connected entity. It uses the temporal relationship between audio and video to extend CLIP's image-text knowledge to also match audio with text.
By using these innovations, the researchers show that TASS outperforms other state-of-the-art AVQA methods on a benchmark dataset.
Technical Explanation
The paper proposes a new CLIP-powered target-aware single-stream (TASS) network for audio-visual question answering (AVQA). AVQA is a task that requires fine-grained audio-visual reasoning, which has not been well explored by existing vision-language pretrained models (VLMs).
The key components of TASS are:
-
Target-aware Spatial Grounding (TSG+): This module transfers the image-text matching knowledge from CLIP to the region-text matching process in AVQA, without requiring ground-truth labels. This allows TASS to better utilize the knowledge stored in CLIP.
-
Single-stream Joint Temporal Grounding (JTG): Unlike previous separate dual-stream networks that still required an additional audio-visual fusion module, JTG unifies audio-visual fusion and question-aware temporal grounding in a single-stream architecture. It treats audio and video as a cohesive entity and extends CLIP's image-text knowledge to audio-text matching by preserving their temporal correlation using a proposed cross-modal synchrony (CMS) loss.
The researchers extensively evaluated TASS on the MUSIC-AVQA benchmark and showed that it outperforms existing state-of-the-art AVQA methods that either underutilized CLIP's knowledge or treated audio and video separately.
Critical Analysis
The paper presents a thoughtful approach to leveraging VLMs for audio-visual reasoning tasks like AVQA. The proposed TASS network addresses several limitations of previous methods, such as the underutilization of CLIP's knowledge and the separate treatment of audio and video.
One potential concern is the reliance on CLIP, which was trained on internet data and may have biases or limitations that could be reflected in the TASS model. The researchers could explore ways to further fine-tune or adapt CLIP to the AVQA task to mitigate such issues.
Additionally, the paper focuses on the MUSIC-AVQA benchmark, which may not be representative of all audio-visual reasoning scenarios. It would be valuable to evaluate TASS on a broader range of AVQA datasets to assess its generalizability.
Further research could also investigate ways to make the TASS architecture more efficient or scalable, as the single-stream design may have implications for computational complexity or memory requirements.
Overall, the TASS network presents an interesting and promising approach to advancing the state of the art in audio-visual reasoning. However, as with any research, there are opportunities for continued refinement and exploration to address potential limitations and expand the model's capabilities.
Conclusion
The paper introduces a new CLIP-powered target-aware single-stream (TASS) network for audio-visual question answering (AVQA). TASS addresses the limitations of previous AVQA methods by better utilizing CLIP's knowledge and treating audio and video as a cohesive entity.
The key innovations of TASS are the target-aware spatial grounding (TSG+) module and the single-stream joint temporal grounding (JTG) module. These components allow TASS to outperform existing state-of-the-art AVQA methods on the MUSIC-AVQA benchmark.
The research presented in this paper represents an important step forward in leveraging VLMs for audio-visual reasoning tasks. By addressing the specific challenges of AVQA, the TASS network demonstrates the potential for these models to excel in fine-grained multimodal understanding beyond just image-text tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
0
CLIP-Powered TASS: Target-Aware Single-Stream Network for Audio-Visual Question Answering
Yuanyuan Jiang, Jianqin Yin
While vision-language pretrained models (VLMs) excel in various multimodal understanding tasks, their potential in fine-grained audio-visual reasoning, particularly for audio-visual question answering (AVQA), remains largely unexplored. AVQA presents specific challenges for VLMs due to the requirement of visual understanding at the region level and seamless integration with audio modality. Previous VLM-based AVQA methods merely used CLIP as a feature encoder but underutilized its knowledge, and mistreated audio and video as separate entities in a dual-stream framework as most AVQA methods. This paper proposes a new CLIP-powered target-aware single-stream (TASS) network for AVQA using the image-text matching knowledge of the pretrained model through the audio-visual matching characteristic of nature. It consists of two key components: the target-aware spatial grounding module (TSG+) and the single-stream joint temporal grounding module (JTG). Specifically, we propose a TSG+ module to transfer the image-text matching knowledge from CLIP models to our region-text matching process without corresponding ground-truth labels. Moreover, unlike previous separate dual-stream networks that still required an additional audio-visual fusion module, JTG unifies audio-visual fusion and question-aware temporal grounding in a simplified single-stream architecture. It treats audio and video as a cohesive entity and further extends the pretrained image-text knowledge to audio-text matching by preserving their temporal correlation with our proposed cross-modal synchrony (CMS) loss. Extensive experiments conducted on the MUSIC-AVQA benchmark verified the effectiveness of our proposed method over existing state-of-the-art methods.
Read more5/14/2024

0
CLIPVQA:Video Quality Assessment via CLIP
Fengchuang Xing, Mingjie Li, Yuan-Gen Wang, Guopu Zhu, Xiaochun Cao
In learning vision-language representations from web-scale data, the contrastive language-image pre-training (CLIP) mechanism has demonstrated a remarkable performance in many vision tasks. However, its application to the widely studied video quality assessment (VQA) task is still an open issue. In this paper, we propose an efficient and effective CLIP-based Transformer method for the VQA problem (CLIPVQA). Specifically, we first design an effective video frame perception paradigm with the goal of extracting the rich spatiotemporal quality and content information among video frames. Then, the spatiotemporal quality features are adequately integrated together using a self-attention mechanism to yield video-level quality representation. To utilize the quality language descriptions of videos for supervision, we develop a CLIP-based encoder for language embedding, which is then fully aggregated with the generated content information via a cross-attention module for producing video-language representation. Finally, the video-level quality and video-language representations are fused together for final video quality prediction, where a vectorized regression loss is employed for efficient end-to-end optimization. Comprehensive experiments are conducted on eight in-the-wild video datasets with diverse resolutions to evaluate the performance of CLIPVQA. The experimental results show that the proposed CLIPVQA achieves new state-of-the-art VQA performance and up to 37% better generalizability than existing benchmark VQA methods. A series of ablation studies are also performed to validate the effectiveness of each module in CLIPVQA.
Read more7/9/2024
🏅
0
Boosting Audio Visual Question Answering via Key Semantic-Aware Cues
Guangyao Li, Henghui Du, Di Hu
The Audio Visual Question Answering (AVQA) task aims to answer questions related to various visual objects, sounds, and their interactions in videos. Such naturally multimodal videos contain rich and complex dynamic audio-visual components, with only a portion of them closely related to the given questions. Hence, effectively perceiving audio-visual cues relevant to the given questions is crucial for correctly answering them. In this paper, we propose a Temporal-Spatial Perception Model (TSPM), which aims to empower the model to perceive key visual and auditory cues related to the questions. Specifically, considering the challenge of aligning non-declarative questions and visual representations into the same semantic space using visual-language pretrained models, we construct declarative sentence prompts derived from the question template, to assist the temporal perception module in better identifying critical segments relevant to the questions. Subsequently, a spatial perception module is designed to merge visual tokens from selected segments to highlight key latent targets, followed by cross-modal interaction with audio to perceive potential sound-aware areas. Finally, the significant temporal-spatial cues from these modules are integrated to answer the question. Extensive experiments on multiple AVQA benchmarks demonstrate that our framework excels not only in understanding audio-visual scenes but also in answering complex questions effectively. Code is available at https://github.com/GeWu-Lab/TSPM.
Read more7/31/2024
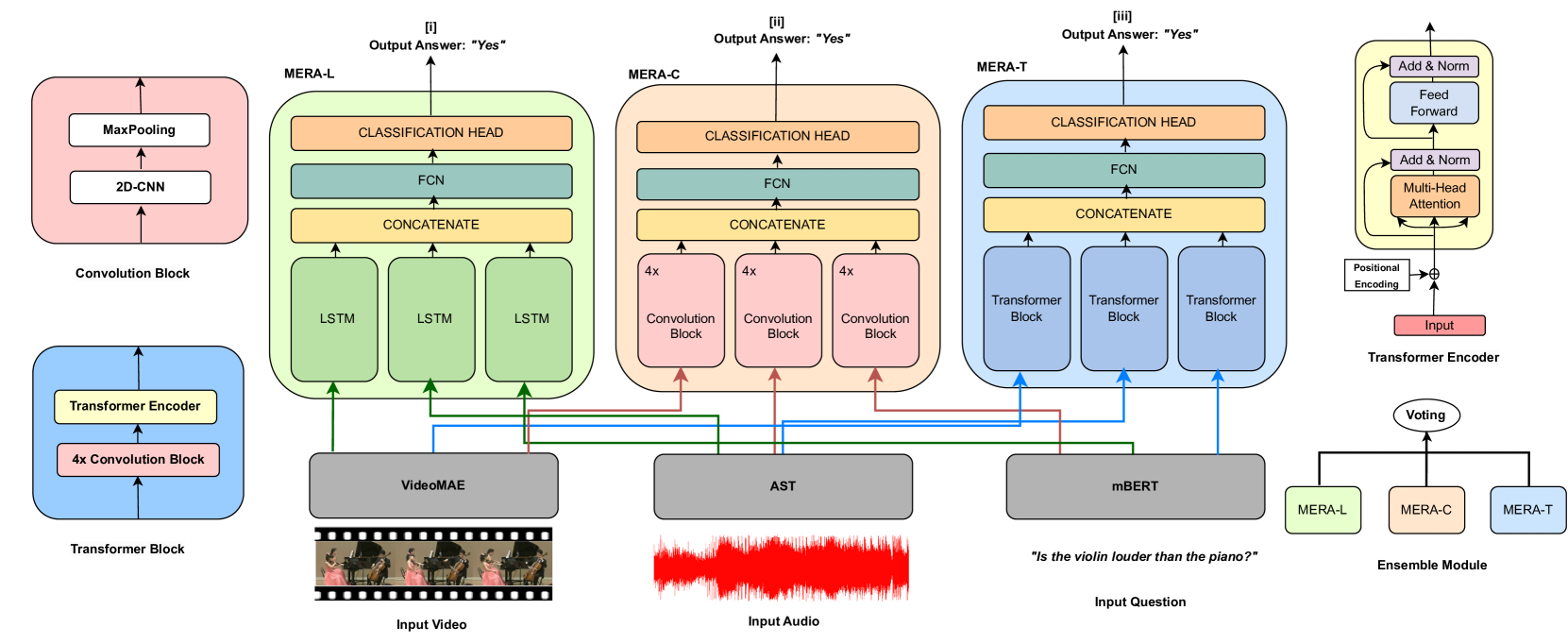
0
Towards Multilingual Audio-Visual Question Answering
Orchid Chetia Phukan, Priyabrata Mallick, Swarup Ranjan Behera, Aalekhya Satya Narayani, Arun Balaji Buduru, Rajesh Sharma
In this paper, we work towards extending Audio-Visual Question Answering (AVQA) to multilingual settings. Existing AVQA research has predominantly revolved around English and replicating it for addressing AVQA in other languages requires a substantial allocation of resources. As a scalable solution, we leverage machine translation and present two multilingual AVQA datasets for eight languages created from existing benchmark AVQA datasets. This prevents extra human annotation efforts of collecting questions and answers manually. To this end, we propose, MERA framework, by leveraging state-of-the-art (SOTA) video, audio, and textual foundation models for AVQA in multiple languages. We introduce a suite of models namely MERA-L, MERA-C, MERA-T with varied model architectures to benchmark the proposed datasets. We believe our work will open new research directions and act as a reference benchmark for future works in multilingual AVQA.
Read more6/14/2024