CMDBench: A Benchmark for Coarse-to-fine Multimodal Data Discovery in Compound AI Systems

0
Sign in to get full access
Overview
- This paper introduces CMDBench, a benchmark for evaluating the performance of Compound AI systems in multimodal data discovery tasks.
- Compound AI systems are a new class of AI models that combine multiple specialized models to tackle complex, real-world problems.
- CMDBench aims to measure how well these systems can efficiently discover and use relevant data from diverse modalities to solve tasks.
Plain English Explanation
The researchers have developed a new benchmark called CMDBench to test the abilities of advanced AI systems that combine multiple specialized models, known as Compound AI systems. These Compound AI systems are designed to tackle complex, real-world problems that require understanding information from different sources, like text, images, and audio.
The CMDBench benchmark focuses on evaluating how well these Compound AI systems can efficiently find and utilize relevant data from various modalities to solve specific tasks. This is an important capability, as being able to discover and integrate diverse data sources is crucial for building AI systems that can operate effectively in the real world.
By providing a standardized way to measure the performance of Compound AI systems on multimodal data discovery tasks, CMDBench aims to help researchers and developers better understand the strengths and limitations of these advanced AI models. This, in turn, can inform the development of more capable and versatile Compound AI systems that can tackle increasingly complex challenges.
Technical Explanation
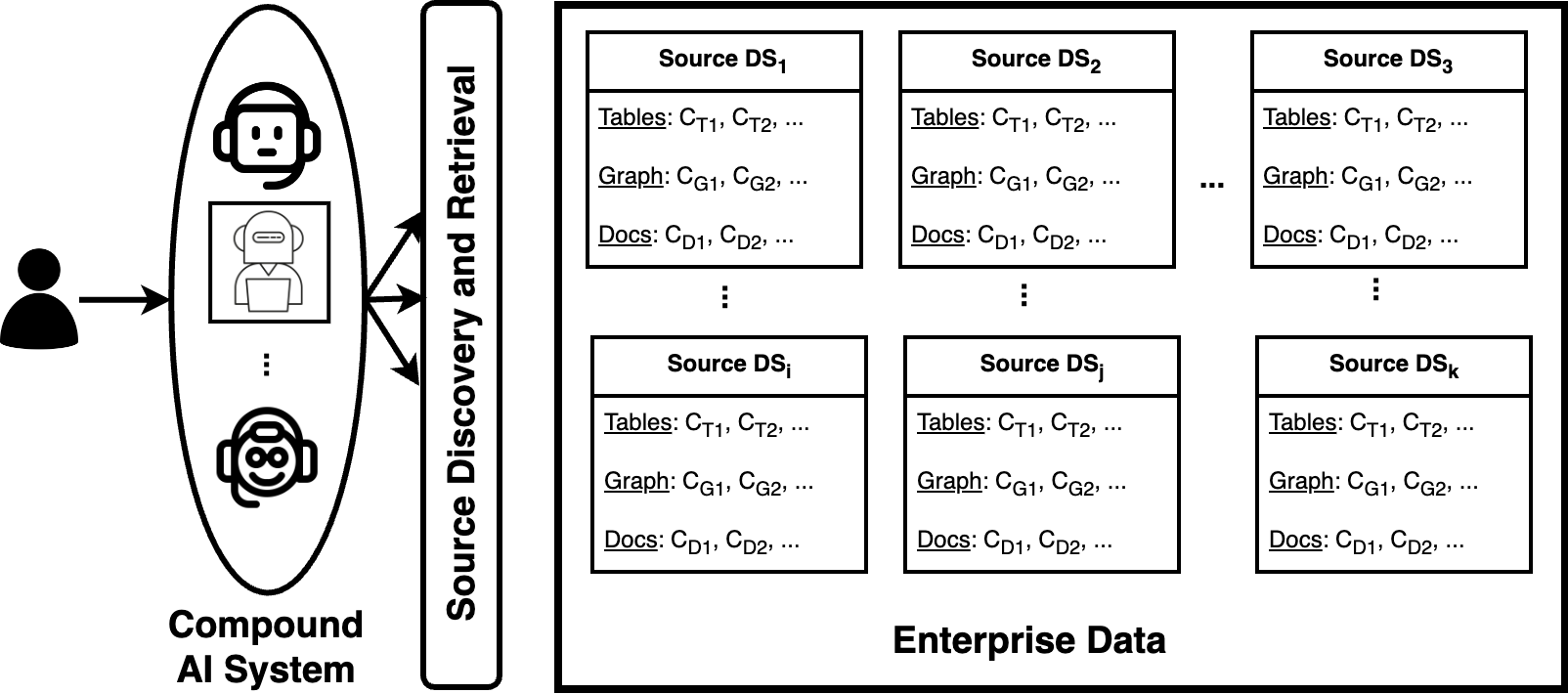
The researchers introduce CMDBench, a benchmark designed to evaluate the performance of Compound AI systems in multimodal data discovery tasks. Compound AI systems are a new class of models that combine multiple specialized sub-models to tackle complex, real-world problems.
CMDBench is structured as a coarse-to-fine data discovery task, where the system must first broadly identify relevant data sources and then progressively refine its understanding to extract the most useful information. The benchmark includes a diverse set of multimodal data sources, including text, images, and audio, which the Compound AI system must efficiently navigate and integrate to solve the given task.
The researchers describe the dataset curation process, task formulation, and evaluation metrics used in CMDBench. They also discuss the potential benefits of this benchmark for advancing the development of Compound AI systems, including better understanding of their strengths, weaknesses, and trade-offs in real-world applications.
Critical Analysis
The CMDBench benchmark appears to be a well-designed and comprehensive tool for evaluating the multimodal data discovery capabilities of Compound AI systems. By focusing on coarse-to-fine data discovery, the benchmark captures an important aspect of how these systems must operate in complex, information-rich environments.
However, the researchers acknowledge that CMDBench may not fully represent all the challenges faced by Compound AI systems in real-world scenarios. For example, the dataset curation process and task formulation may not fully capture the nuances and ambiguities of natural data sources and problem statements.
Additionally, while the benchmark provides a standardized way to compare the performance of different Compound AI systems, it remains to be seen how well these results will translate to actual application-level performance. Further research and validation may be needed to ensure the benchmark's relevance and usefulness for guiding the development of more capable and versatile Compound AI systems.
Conclusion
The CMDBench benchmark introduced in this paper represents an important step forward in evaluating the multimodal data discovery capabilities of Compound AI systems. By providing a standardized and comprehensive test bed, CMDBench can help researchers and developers better understand the strengths, weaknesses, and trade-offs of these advanced AI models.
As Compound AI systems continue to evolve and tackle increasingly complex real-world problems, tools like CMDBench will become increasingly valuable for driving progress and ensuring these systems can effectively leverage diverse data sources to solve important challenges. The insights gained from this benchmark can inform the development of more robust and adaptable Compound AI systems that can operate effectively in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CMDBench: A Benchmark for Coarse-to-fine Multimodal Data Discovery in Compound AI Systems
Yanlin Feng, Sajjadur Rahman, Aaron Feng, Vincent Chen, Eser Kandogan
Compound AI systems (CASs) that employ LLMs as agents to accomplish knowledge-intensive tasks via interactions with tools and data retrievers have garnered significant interest within database and AI communities. While these systems have the potential to supplement typical analysis workflows of data analysts in enterprise data platforms, unfortunately, CASs are subject to the same data discovery challenges that analysts have encountered over the years -- silos of multimodal data sources, created across teams and departments within an organization, make it difficult to identify appropriate data sources for accomplishing the task at hand. Existing data discovery benchmarks do not model such multimodality and multiplicity of data sources. Moreover, benchmarks of CASs prioritize only evaluating end-to-end task performance. To catalyze research on evaluating the data discovery performance of multimodal data retrievers in CASs within a real-world setting, we propose CMDBench, a benchmark modeling the complexity of enterprise data platforms. We adapt existing datasets and benchmarks in open-domain -- from question answering and complex reasoning tasks to natural language querying over structured data -- to evaluate coarse- and fine-grained data discovery and task execution performance. Our experiments reveal the impact of data retriever design on downstream task performance -- a 46% drop in task accuracy on average -- across various modalities, data sources, and task difficulty. The results indicate the need to develop optimization strategies to identify appropriate LLM agents and retrievers for efficient execution of CASs over enterprise data.
Read more6/4/2024
🤖
0
New!A Survey on Multimodal Benchmarks: In the Era of Large AI Models
Lin Li, Guikun Chen, Hanrong Shi, Jun Xiao, Long Chen
The rapid evolution of Multimodal Large Language Models (MLLMs) has brought substantial advancements in artificial intelligence, significantly enhancing the capability to understand and generate multimodal content. While prior studies have largely concentrated on model architectures and training methodologies, a thorough analysis of the benchmarks used for evaluating these models remains underexplored. This survey addresses this gap by systematically reviewing 211 benchmarks that assess MLLMs across four core domains: understanding, reasoning, generation, and application. We provide a detailed analysis of task designs, evaluation metrics, and dataset constructions, across diverse modalities. We hope that this survey will contribute to the ongoing advancement of MLLM research by offering a comprehensive overview of benchmarking practices and identifying promising directions for future work. An associated GitHub repository collecting the latest papers is available.
Read more9/30/2024
🔍
0
3DBench: A Scalable 3D Benchmark and Instruction-Tuning Dataset
Junjie Zhang, Tianci Hu, Xiaoshui Huang, Yongshun Gong, Dan Zeng
Evaluating the performance of Multi-modal Large Language Models (MLLMs), integrating both point cloud and language, presents significant challenges. The lack of a comprehensive assessment hampers determining whether these models truly represent advancements, thereby impeding further progress in the field. Current evaluations heavily rely on classification and caption tasks, falling short in providing a thorough assessment of MLLMs. A pressing need exists for a more sophisticated evaluation method capable of thoroughly analyzing the spatial understanding and expressive capabilities of these models. To address these issues, we introduce a scalable 3D benchmark, accompanied by a large-scale instruction-tuning dataset known as 3DBench, providing an extensible platform for a comprehensive evaluation of MLLMs. Specifically, we establish the benchmark that spans a wide range of spatial and semantic scales, from object-level to scene-level, addressing both perception and planning tasks. Furthermore, we present a rigorous pipeline for automatically constructing scalable 3D instruction-tuning datasets, covering 10 diverse multi-modal tasks with more than 0.23 million QA pairs generated in total. Thorough experiments evaluating trending MLLMs, comparisons against existing datasets, and variations of training protocols demonstrate the superiority of 3DBench, offering valuable insights into current limitations and potential research directions.
Read more4/24/2024

0
DCA-Bench: A Benchmark for Dataset Curation Agents
Benhao Huang, Yingzhuo Yu, Jin Huang, Xingjian Zhang, Jiaqi Ma
The quality of datasets plays an increasingly crucial role in the research and development of modern artificial intelligence (AI). Despite the proliferation of open dataset platforms nowadays, data quality issues, such as insufficient documentation, inaccurate annotations, and ethical concerns, remain common in datasets widely used in AI. Furthermore, these issues are often subtle and difficult to be detected by rule-based scripts, requiring expensive manual identification and verification by dataset users or maintainers. With the increasing capability of large language models (LLMs), it is promising to streamline the curation of datasets with LLM agents. In this work, as the initial step towards this goal, we propose a dataset curation agent benchmark, DCA-Bench, to measure LLM agents' capability of detecting hidden dataset quality issues. Specifically, we collect diverse real-world dataset quality issues from eight open dataset platforms as a testbed. Additionally, to establish an automatic pipeline for evaluating the success of LLM agents, which requires a nuanced understanding of the agent outputs, we implement a dedicated Evaluator using another LLM agent. We demonstrate that the LLM-based Evaluator empirically aligns well with human evaluation, allowing reliable automatic evaluation on the proposed benchmark. We further conduct experiments on several baseline LLM agents on the proposed benchmark and demonstrate the complexity of the task, indicating that applying LLMs to real-world dataset curation still requires further in-depth exploration and innovation. Finally, the proposed benchmark can also serve as a testbed for measuring the capability of LLMs in problem discovery rather than just problem-solving. The benchmark suite is available at url{https://github.com/TRAIS-Lab/dca-bench}.
Read more6/12/2024