DCA-Bench: A Benchmark for Dataset Curation Agents

0

Sign in to get full access
Overview
- This paper introduces DCA-Bench, a benchmark for evaluating dataset curation agents (DCAs) - systems that can automatically curate datasets by identifying and fixing issues.
- DCA-Bench includes a diverse set of real-world datasets, a range of curation tasks, and comprehensive evaluation metrics to assess DCA performance.
- The authors argue that DCA-Bench can help drive progress in the important field of dataset curation, which is critical for the development of robust and reliable machine learning systems.
Plain English Explanation
The paper presents a new benchmark called DCA-Bench that is designed to evaluate the performance of systems that can automatically curate datasets. Dataset curation is the process of identifying and fixing issues in datasets, such as missing information, inconsistencies, or biases. This is an important task, as the quality of the data used to train machine learning models can have a big impact on the models' performance and reliability.
DCA-Bench includes a diverse collection of real-world datasets, along with a variety of curation tasks that these systems would need to perform, such as detecting and correcting errors, identifying biases, or enhancing dataset metadata. The benchmark also provides comprehensive metrics to assess how well the curation systems are able to identify and address these issues.
The authors believe that DCA-Bench can help drive progress in the field of dataset curation by providing a standardized way to evaluate and compare the capabilities of different curation systems. This, in turn, can lead to the development of more robust and reliable machine learning models that are built on high-quality data.
Technical Explanation
The paper introduces DCA-Bench, a new benchmark for evaluating dataset curation agents (DCAs) - systems that can automatically identify and fix issues in datasets. The benchmark includes a diverse set of real-world datasets spanning different domains, along with a range of curation tasks that DCAs would need to perform, such as detecting and correcting errors, identifying biases, and enhancing metadata.
To assess DCA performance, the authors have developed a comprehensive set of evaluation metrics that measure various aspects of curation quality, including accuracy, completeness, and efficiency. These metrics can be used to compare the capabilities of different curation systems and track progress in the field over time.
The authors argue that DCA-Bench can be a valuable tool for driving progress in dataset curation, which is a crucial step in the machine learning pipeline. By providing a standardized benchmark, DCA-Bench can help researchers and developers build more robust and reliable curation systems, leading to higher-quality datasets and, ultimately, more trustworthy machine learning models.
Critical Analysis
The DCA-Bench benchmark presented in this paper appears to be a well-designed and comprehensive tool for evaluating dataset curation systems. The authors have thoughtfully curated a diverse set of real-world datasets and defined a range of relevant curation tasks, which should provide a robust test of DCA capabilities.
One potential limitation of the benchmark is the reliance on human-annotated ground truth data to assess curation quality. While this is a common approach, it could be susceptible to human biases or inconsistencies. The authors acknowledge this challenge and suggest exploring alternative evaluation methods, such as using synthetic datasets with known issues, as an area for future work.
Additionally, the paper does not provide much insight into the specific algorithms or architectures used by the DCAs evaluated in the benchmark. Further research could explore how different curation approaches perform on the DCA-Bench tasks, which could help guide the development of more effective curation systems.
Overall, the DCA-Bench benchmark represents an important step forward in the field of dataset curation and could have significant implications for improving the reliability and robustness of machine learning systems. As the authors note, high-quality datasets are essential for building trustworthy AI, and tools like DCA-Bench can help accelerate progress in this critical area.
Conclusion
The DCA-Bench benchmark introduced in this paper is a valuable contribution to the field of dataset curation. By providing a standardized way to evaluate the performance of systems that can automatically identify and fix issues in datasets, DCA-Bench has the potential to drive significant progress in this important area of machine learning research.
The benchmark's diverse set of real-world datasets, comprehensive curation tasks, and rigorous evaluation metrics make it a robust and versatile tool for assessing the capabilities of different curation systems. As the authors suggest, DCA-Bench could ultimately lead to the development of more reliable and trustworthy machine learning models, which could have far-reaching implications for a wide range of applications.
While the paper highlights some potential limitations, such as the reliance on human-annotated ground truth data, the authors have laid the groundwork for future research to explore alternative evaluation methods and further refine the benchmark. Overall, DCA-Bench represents an important step forward in the quest to build high-quality datasets and more robust AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DCA-Bench: A Benchmark for Dataset Curation Agents
Benhao Huang, Yingzhuo Yu, Jin Huang, Xingjian Zhang, Jiaqi Ma
The quality of datasets plays an increasingly crucial role in the research and development of modern artificial intelligence (AI). Despite the proliferation of open dataset platforms nowadays, data quality issues, such as insufficient documentation, inaccurate annotations, and ethical concerns, remain common in datasets widely used in AI. Furthermore, these issues are often subtle and difficult to be detected by rule-based scripts, requiring expensive manual identification and verification by dataset users or maintainers. With the increasing capability of large language models (LLMs), it is promising to streamline the curation of datasets with LLM agents. In this work, as the initial step towards this goal, we propose a dataset curation agent benchmark, DCA-Bench, to measure LLM agents' capability of detecting hidden dataset quality issues. Specifically, we collect diverse real-world dataset quality issues from eight open dataset platforms as a testbed. Additionally, to establish an automatic pipeline for evaluating the success of LLM agents, which requires a nuanced understanding of the agent outputs, we implement a dedicated Evaluator using another LLM agent. We demonstrate that the LLM-based Evaluator empirically aligns well with human evaluation, allowing reliable automatic evaluation on the proposed benchmark. We further conduct experiments on several baseline LLM agents on the proposed benchmark and demonstrate the complexity of the task, indicating that applying LLMs to real-world dataset curation still requires further in-depth exploration and innovation. Finally, the proposed benchmark can also serve as a testbed for measuring the capability of LLMs in problem discovery rather than just problem-solving. The benchmark suite is available at url{https://github.com/TRAIS-Lab/dca-bench}.
Read more6/12/2024

0
DSBench: How Far Are Data Science Agents to Becoming Data Science Experts?
Liqiang Jing, Zhehui Huang, Xiaoyang Wang, Wenlin Yao, Wenhao Yu, Kaixin Ma, Hongming Zhang, Xinya Du, Dong Yu
Large Language Models (LLMs) and Large Vision-Language Models (LVLMs) have demonstrated impressive language/vision reasoning abilities, igniting the recent trend of building agents for targeted applications such as shopping assistants or AI software engineers. Recently, many data science benchmarks have been proposed to investigate their performance in the data science domain. However, existing data science benchmarks still fall short when compared to real-world data science applications due to their simplified settings. To bridge this gap, we introduce DSBench, a comprehensive benchmark designed to evaluate data science agents with realistic tasks. This benchmark includes 466 data analysis tasks and 74 data modeling tasks, sourced from Eloquence and Kaggle competitions. DSBench offers a realistic setting by encompassing long contexts, multimodal task backgrounds, reasoning with large data files and multi-table structures, and performing end-to-end data modeling tasks. Our evaluation of state-of-the-art LLMs, LVLMs, and agents shows that they struggle with most tasks, with the best agent solving only 34.12% of data analysis tasks and achieving a 34.74% Relative Performance Gap (RPG). These findings underscore the need for further advancements in developing more practical, intelligent, and autonomous data science agents.
Read more9/14/2024

0
InsightBench: Evaluating Business Analytics Agents Through Multi-Step Insight Generation
Gaurav Sahu, Abhay Puri, Juan Rodriguez, Alexandre Drouin, Perouz Taslakian, Valentina Zantedeschi, Alexandre Lacoste, David Vazquez, Nicolas Chapados, Christopher Pal, Sai Rajeswar Mudumba, Issam Hadj Laradji
Data analytics is essential for extracting valuable insights from data that can assist organizations in making effective decisions. We introduce InsightBench, a benchmark dataset with three key features. First, it consists of 31 datasets representing diverse business use cases such as finance and incident management, each accompanied by a carefully curated set of insights planted in the datasets. Second, unlike existing benchmarks focusing on answering single queries, InsightBench evaluates agents based on their ability to perform end-to-end data analytics, including formulating questions, interpreting answers, and generating a summary of insights and actionable steps. Third, we conducted comprehensive quality assurance to ensure that each dataset in the benchmark had clear goals and included relevant and meaningful questions and analysis. Furthermore, we implement a two-way evaluation mechanism using LLaMA-3-Eval as an effective, open-source evaluator method to assess agents' ability to extract insights. We also propose AgentPoirot, our baseline data analysis agent capable of performing end-to-end data analytics. Our evaluation on InsightBench shows that AgentPoirot outperforms existing approaches (such as Pandas Agent) that focus on resolving single queries. We also compare the performance of open- and closed-source LLMs and various evaluation strategies. Overall, this benchmark serves as a testbed to motivate further development in comprehensive data analytics and can be accessed here: https://github.com/ServiceNow/insight-bench.
Read more7/10/2024
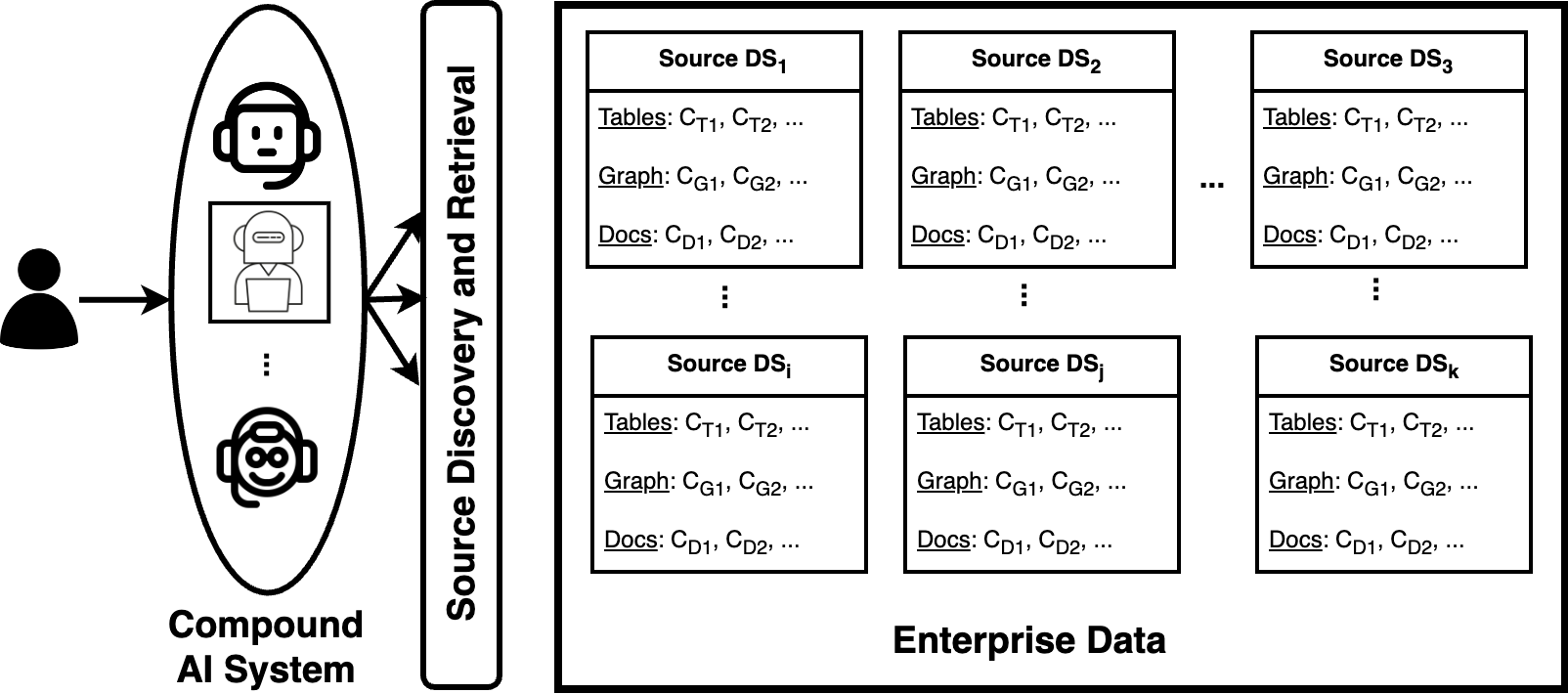
0
CMDBench: A Benchmark for Coarse-to-fine Multimodal Data Discovery in Compound AI Systems
Yanlin Feng, Sajjadur Rahman, Aaron Feng, Vincent Chen, Eser Kandogan
Compound AI systems (CASs) that employ LLMs as agents to accomplish knowledge-intensive tasks via interactions with tools and data retrievers have garnered significant interest within database and AI communities. While these systems have the potential to supplement typical analysis workflows of data analysts in enterprise data platforms, unfortunately, CASs are subject to the same data discovery challenges that analysts have encountered over the years -- silos of multimodal data sources, created across teams and departments within an organization, make it difficult to identify appropriate data sources for accomplishing the task at hand. Existing data discovery benchmarks do not model such multimodality and multiplicity of data sources. Moreover, benchmarks of CASs prioritize only evaluating end-to-end task performance. To catalyze research on evaluating the data discovery performance of multimodal data retrievers in CASs within a real-world setting, we propose CMDBench, a benchmark modeling the complexity of enterprise data platforms. We adapt existing datasets and benchmarks in open-domain -- from question answering and complex reasoning tasks to natural language querying over structured data -- to evaluate coarse- and fine-grained data discovery and task execution performance. Our experiments reveal the impact of data retriever design on downstream task performance -- a 46% drop in task accuracy on average -- across various modalities, data sources, and task difficulty. The results indicate the need to develop optimization strategies to identify appropriate LLM agents and retrievers for efficient execution of CASs over enterprise data.
Read more6/4/2024