CMNEE: A Large-Scale Document-Level Event Extraction Dataset based on Open-Source Chinese Military News

0
Sign in to get full access
Data Collection and Preprocessing
Overview:
- The researchers collected a large-scale dataset of Chinese military news articles from open-source online platforms.
- They preprocessed the data, including cleaning the text, extracting key metadata, and annotating the documents with event-related information.
Plain English Explanation: The researchers gathered a sizable dataset of Chinese military news articles from publicly available online sources. They then cleaned up the text, extracted important information like the date and source of each article, and annotated the documents to identify key events mentioned in the content. This process of collecting and preprocessing the data laid the foundation for the CMNEE dataset, which the researchers used for their event extraction research.
Technical Explanation: The researchers collected a corpus of Chinese military news articles from open-source online platforms. They preprocessed the data, including cleaning the text to remove noise and formatting issues, extracting relevant metadata like publication date and source, and annotating the documents with event-related information. This data collection and preprocessing laid the groundwork for the CMNEE dataset, which the researchers used in their nested event extraction, schema-based information extraction, and other event-centric natural language processing research.
Critical Analysis: The researchers provided a clear and comprehensive explanation of their data collection and preprocessing methodology. However, they did not provide detailed statistics on the size and composition of the final CMNEE dataset, which would be useful for understanding the scope and potential biases of the corpus. Additionally, the researchers could have discussed any challenges or limitations encountered during the data collection and annotation process, as well as steps taken to ensure the reliability and validity of the annotations.
Conclusion: The researchers established a robust data collection and preprocessing pipeline to create the CMNEE dataset, a large-scale corpus of Chinese military news articles annotated with event-related information. This dataset serves as a valuable resource for advancing research in event extraction, information retrieval, and other event-enhanced natural language processing applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CMNEE: A Large-Scale Document-Level Event Extraction Dataset based on Open-Source Chinese Military News
Mengna Zhu, Zijie Xu, Kaisheng Zeng, Kaiming Xiao, Mao Wang, Wenjun Ke, Hongbin Huang
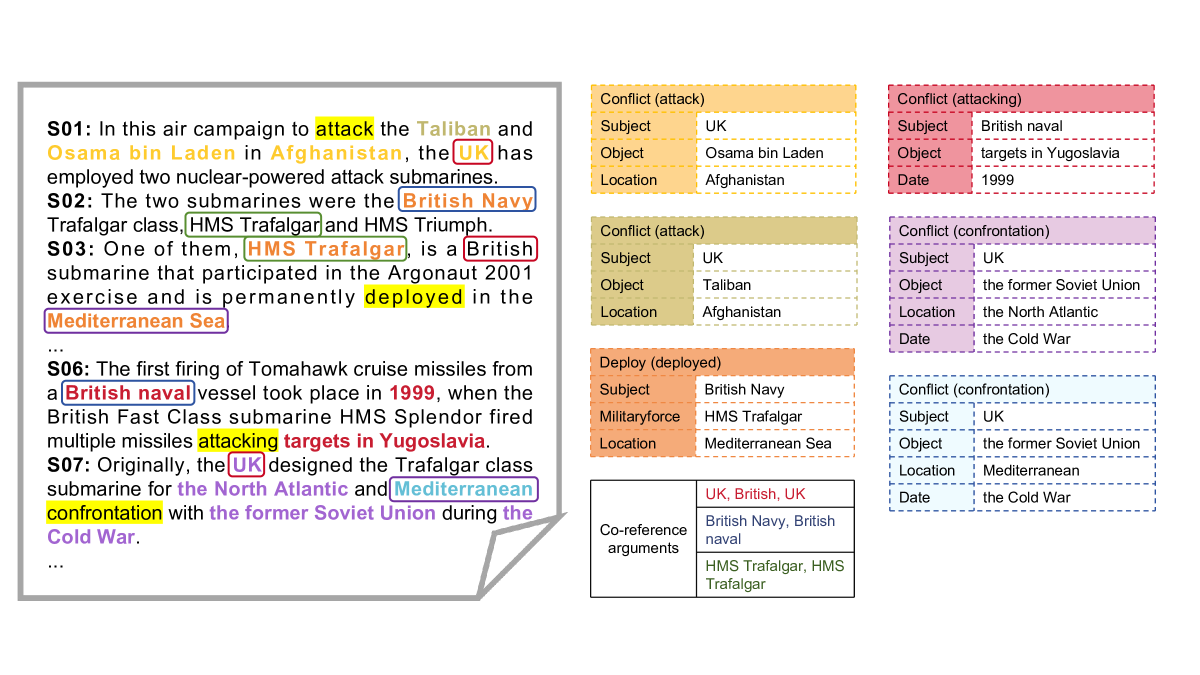
Extracting structured event knowledge, including event triggers and corresponding arguments, from military texts is fundamental to many applications, such as intelligence analysis and decision assistance. However, event extraction in the military field faces the data scarcity problem, which impedes the research of event extraction models in this domain. To alleviate this problem, we propose CMNEE, a large-scale, document-level open-source Chinese Military News Event Extraction dataset. It contains 17,000 documents and 29,223 events, which are all manually annotated based on a pre-defined schema for the military domain including 8 event types and 11 argument role types. We designed a two-stage, multi-turns annotation strategy to ensure the quality of CMNEE and reproduced several state-of-the-art event extraction models with a systematic evaluation. The experimental results on CMNEE fall shorter than those on other domain datasets obviously, which demonstrates that event extraction for military domain poses unique challenges and requires further research efforts. Our code and data can be obtained from https://github.com/Mzzzhu/CMNEE.
Read more4/19/2024
0
Harvesting Events from Multiple Sources: Towards a Cross-Document Event Extraction Paradigm
Qiang Gao, Zixiang Meng, Bobo Li, Jun Zhou, Fei Li, Chong Teng, Donghong Ji
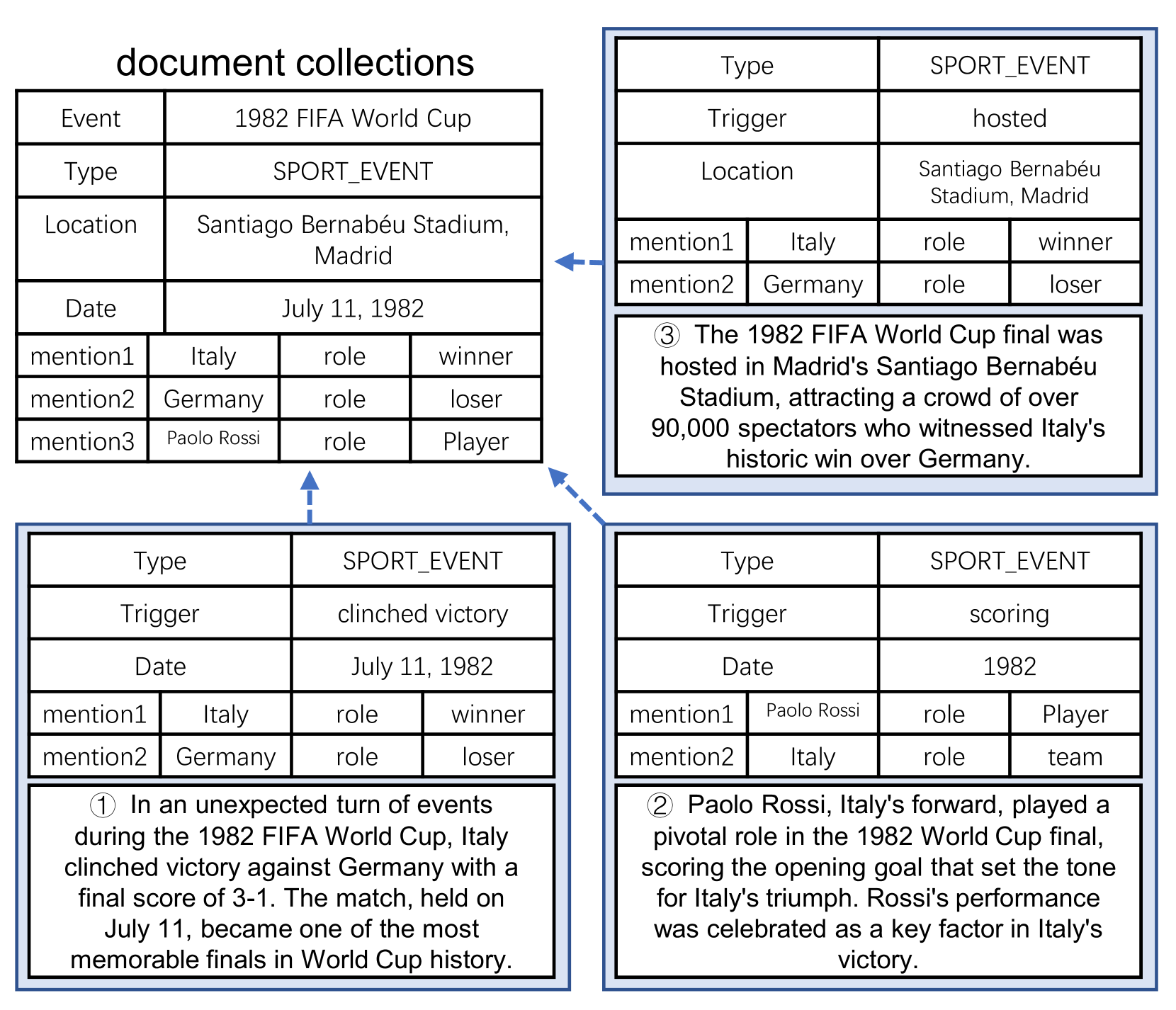
Document-level event extraction aims to extract structured event information from unstructured text. However, a single document often contains limited event information and the roles of different event arguments may be biased due to the influence of the information source. This paper addresses the limitations of traditional document-level event extraction by proposing the task of cross-document event extraction (CDEE) to integrate event information from multiple documents and provide a comprehensive perspective on events. We construct a novel cross-document event extraction dataset, namely CLES, which contains 20,059 documents and 37,688 mention-level events, where over 70% of them are cross-document. To build a benchmark, we propose a CDEE pipeline that includes 5 steps, namely event extraction, coreference resolution, entity normalization, role normalization and entity-role resolution. Our CDEE pipeline achieves about 72% F1 in end-to-end cross-document event extraction, suggesting the challenge of this task. Our work builds a new line of information extraction research and will attract new research attention.
Read more6/26/2024
⛏️
0
Beyond Single-Event Extraction: Towards Efficient Document-Level Multi-Event Argument Extraction
Wanlong Liu, Li Zhou, Dingyi Zeng, Yichen Xiao, Shaohuan Cheng, Chen Zhang, Grandee Lee, Malu Zhang, Wenyu Chen
Recent mainstream event argument extraction methods process each event in isolation, resulting in inefficient inference and ignoring the correlations among multiple events. To address these limitations, here we propose a multiple-event argument extraction model DEEIA (Dependency-guided Encoding and Event-specific Information Aggregation), capable of extracting arguments from all events within a document simultaneouslyThe proposed DEEIA model employs a multi-event prompt mechanism, comprising DE and EIA modules. The DE module is designed to improve the correlation between prompts and their corresponding event contexts, whereas the EIA module provides event-specific information to improve contextual understanding. Extensive experiments show that our method achieves new state-of-the-art performance on four public datasets (RAMS, WikiEvents, MLEE, and ACE05), while significantly saving the inference time compared to the baselines. Further analyses demonstrate the effectiveness of the proposed modules.
Read more6/18/2024

0
Document-Level Event Extraction with Definition-Driven ICL
Zhuoyuan Liu, Yilin Luo
In the field of Natural Language Processing (NLP), Large Language Models (LLMs) have shown great potential in document-level event extraction tasks, but existing methods face challenges in the design of prompts. To address this issue, we propose an optimization strategy called Definition-driven Document-level Event Extraction (DDEE). By adjusting the length of the prompt and enhancing the clarity of heuristics, we have significantly improved the event extraction performance of LLMs. We used data balancing techniques to solve the long-tail effect problem, enhancing the model's generalization ability for event types. At the same time, we refined the prompt to ensure it is both concise and comprehensive, adapting to the sensitivity of LLMs to the style of prompts. In addition, the introduction of structured heuristic methods and strict limiting conditions has improved the precision of event and argument role extraction. These strategies not only solve the prompt engineering problems of LLMs in document-level event extraction but also promote the development of event extraction technology, providing new research perspectives for other tasks in the NLP field.
Read more8/13/2024