Harvesting Events from Multiple Sources: Towards a Cross-Document Event Extraction Paradigm

0
Sign in to get full access
Overview
- This paper proposes a novel approach to event extraction that leverages information from multiple documents, known as "cross-document event extraction."
- The goal is to develop more robust and comprehensive event extraction systems by combining evidence from various sources, rather than relying on a single document.
- The paper explores challenges and potential solutions for effectively integrating event information across documents, with the aim of advancing the state-of-the-art in event extraction.
Plain English Explanation
When we read news articles or other documents, we often encounter descriptions of events, such as a political election, a natural disaster, or a business acquisition. Event extraction is the process of automatically identifying and extracting these event-related details from text.
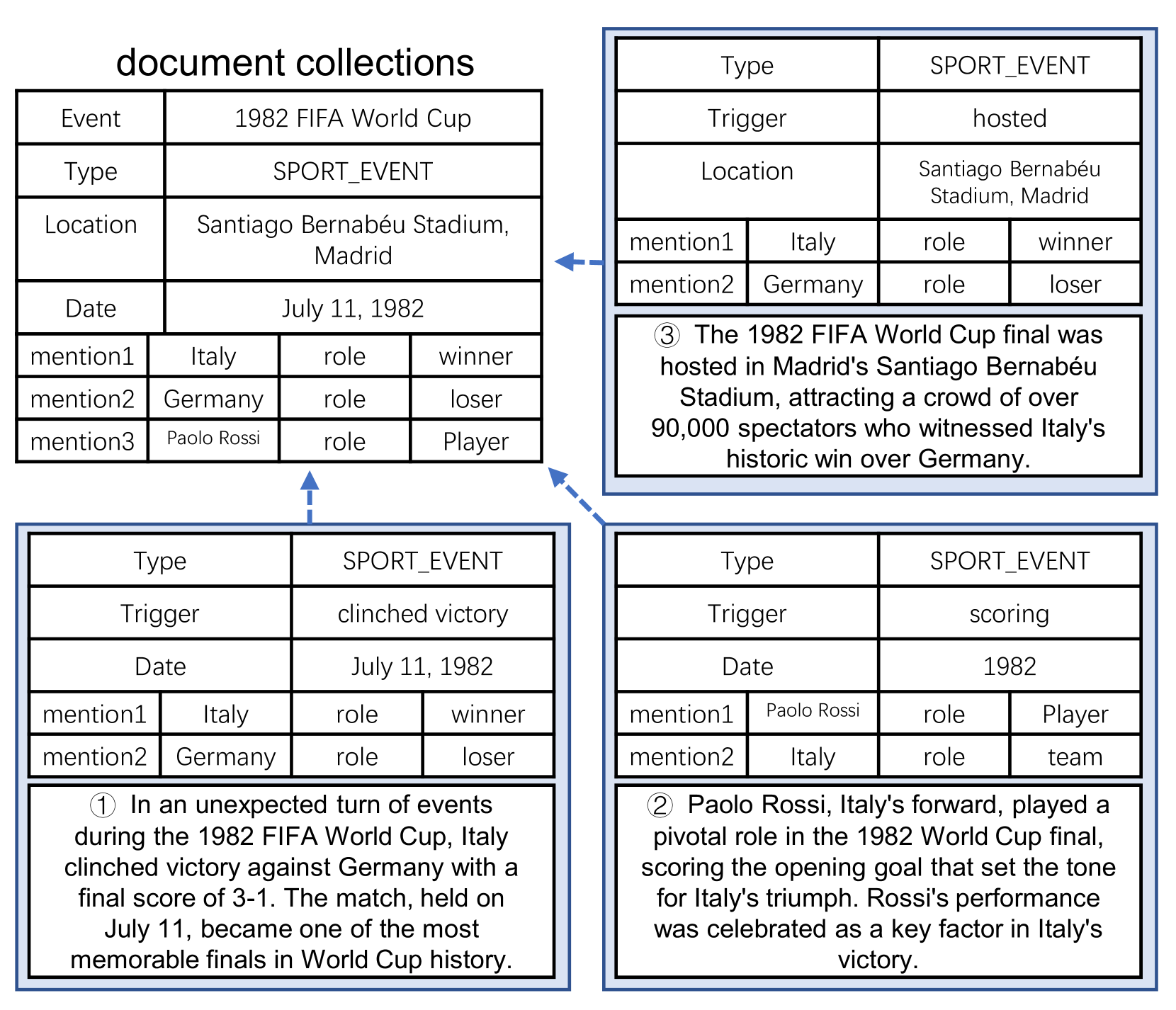
Traditionally, event extraction systems have focused on analyzing a single document in isolation. However, this approach has limitations, as important event-related information may be scattered across multiple documents. The authors of this paper propose a new paradigm called cross-document event extraction, where the goal is to combine evidence from various sources to build a more comprehensive understanding of events.
By leveraging information from multiple documents, the researchers aim to develop event extraction systems that are more robust and accurate. This could be particularly useful in scenarios where a single document may provide an incomplete or biased perspective on an event. By integrating evidence from different sources, the system can potentially fill in gaps, resolve discrepancies, and obtain a more holistic view of the event.
The paper explores the technical challenges and potential solutions for effectively combining event-related information across documents. This includes issues such as event coreference resolution, where the system needs to identify mentions of the same event across different documents, and document-level event extraction, which involves extracting event details from an entire document rather than just individual sentences.
By addressing these challenges, the researchers hope to advance the field of event extraction and enable more comprehensive and reliable understanding of events based on information from multiple sources.
Technical Explanation
The paper proposes a novel cross-document event extraction paradigm that aims to leverage information from multiple documents to build a more comprehensive understanding of events. This is in contrast to traditional event extraction systems, which have typically focused on analyzing a single document in isolation.
The authors argue that by combining evidence from various sources, event extraction systems can become more robust and accurate. They identify several technical challenges that need to be addressed to enable effective cross-document event extraction, including:
-
Event Coreference Resolution: The system needs to be able to identify mentions of the same event across different documents and link them together. This is a non-trivial task, as event descriptions may vary in their wording and level of detail.
-
Document-level Event Extraction: Rather than extracting events from individual sentences, the system needs to be able to extract event-related information from entire documents, which may involve complex reasoning and inference.
-
Efficient Integration of Cross-document Evidence: The system must effectively combine and reconcile the event-related information gathered from multiple documents, handling potential conflicts or discrepancies in the data.
To address these challenges, the authors propose several technical solutions and outline potential research directions. For example, they suggest leveraging cross-document event coreference resolution techniques to link event mentions across documents, and exploring document-level event extraction approaches that can extract event details from an entire document context.
The paper also highlights the potential benefits of this cross-document event extraction paradigm, such as its ability to provide a more comprehensive and reliable understanding of events by combining evidence from multiple sources. This could be particularly useful in scenarios where a single document may offer an incomplete or biased perspective on an event.
Critical Analysis
The paper presents a compelling vision for advancing the field of event extraction by moving beyond the traditional single-document approach and towards a cross-document paradigm. The authors clearly identify the limitations of existing event extraction systems and make a strong case for the potential benefits of their proposed approach.
One potential limitation of the paper is that it primarily focuses on the high-level challenges and ideas, without delving too deeply into the specific technical solutions. While the authors outline some potential research directions, more detailed discussion of the proposed methods and their evaluation would have been helpful for readers to fully assess the feasibility and merits of the approach.
Additionally, the paper does not address potential issues related to the availability and quality of the data needed to support cross-document event extraction. In real-world scenarios, the corpus of documents may be noisy, incomplete, or biased, which could pose significant challenges for effectively integrating evidence across sources.
Furthermore, the paper does not extensively discuss the potential ethical and societal implications of cross-document event extraction systems. As these systems become more powerful and influential in shaping our understanding of events, it will be crucial to consider issues such as data privacy, algorithmic bias, and the potential for misinformation or manipulation.
Overall, the paper presents a compelling and forward-looking vision for event extraction research. By encouraging the community to think beyond single-document approaches and explore the potential of cross-document integration, the authors have the opportunity to drive significant advancements in this important field of study.
Conclusion
This paper proposes a novel cross-document event extraction paradigm that aims to leverage information from multiple documents to build a more comprehensive understanding of events. The authors argue that by combining evidence from various sources, event extraction systems can become more robust and accurate, addressing the limitations of traditional single-document approaches.
The paper identifies several key technical challenges, such as event coreference resolution and document-level event extraction, and outlines potential research directions to address these challenges. While the paper focuses primarily on the high-level ideas and vision, it provides a solid foundation for future work in this area.
As the field of event extraction continues to evolve, the cross-document paradigm proposed in this paper has the potential to enable more reliable and holistic understanding of events, with far-reaching implications for a wide range of applications, from news reporting to intelligence analysis. By exploring this new direction, researchers can drive significant advancements in the state-of-the-art and contribute to the development of more robust and comprehensive event extraction systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Harvesting Events from Multiple Sources: Towards a Cross-Document Event Extraction Paradigm
Qiang Gao, Zixiang Meng, Bobo Li, Jun Zhou, Fei Li, Chong Teng, Donghong Ji
Document-level event extraction aims to extract structured event information from unstructured text. However, a single document often contains limited event information and the roles of different event arguments may be biased due to the influence of the information source. This paper addresses the limitations of traditional document-level event extraction by proposing the task of cross-document event extraction (CDEE) to integrate event information from multiple documents and provide a comprehensive perspective on events. We construct a novel cross-document event extraction dataset, namely CLES, which contains 20,059 documents and 37,688 mention-level events, where over 70% of them are cross-document. To build a benchmark, we propose a CDEE pipeline that includes 5 steps, namely event extraction, coreference resolution, entity normalization, role normalization and entity-role resolution. Our CDEE pipeline achieves about 72% F1 in end-to-end cross-document event extraction, suggesting the challenge of this task. Our work builds a new line of information extraction research and will attract new research attention.
Read more6/26/2024
⛏️
0
Beyond Single-Event Extraction: Towards Efficient Document-Level Multi-Event Argument Extraction
Wanlong Liu, Li Zhou, Dingyi Zeng, Yichen Xiao, Shaohuan Cheng, Chen Zhang, Grandee Lee, Malu Zhang, Wenyu Chen
Recent mainstream event argument extraction methods process each event in isolation, resulting in inefficient inference and ignoring the correlations among multiple events. To address these limitations, here we propose a multiple-event argument extraction model DEEIA (Dependency-guided Encoding and Event-specific Information Aggregation), capable of extracting arguments from all events within a document simultaneouslyThe proposed DEEIA model employs a multi-event prompt mechanism, comprising DE and EIA modules. The DE module is designed to improve the correlation between prompts and their corresponding event contexts, whereas the EIA module provides event-specific information to improve contextual understanding. Extensive experiments show that our method achieves new state-of-the-art performance on four public datasets (RAMS, WikiEvents, MLEE, and ACE05), while significantly saving the inference time compared to the baselines. Further analyses demonstrate the effectiveness of the proposed modules.
Read more6/18/2024

0
Document-Level Event Extraction with Definition-Driven ICL
Zhuoyuan Liu, Yilin Luo
In the field of Natural Language Processing (NLP), Large Language Models (LLMs) have shown great potential in document-level event extraction tasks, but existing methods face challenges in the design of prompts. To address this issue, we propose an optimization strategy called Definition-driven Document-level Event Extraction (DDEE). By adjusting the length of the prompt and enhancing the clarity of heuristics, we have significantly improved the event extraction performance of LLMs. We used data balancing techniques to solve the long-tail effect problem, enhancing the model's generalization ability for event types. At the same time, we refined the prompt to ensure it is both concise and comprehensive, adapting to the sensitivity of LLMs to the style of prompts. In addition, the introduction of structured heuristic methods and strict limiting conditions has improved the precision of event and argument role extraction. These strategies not only solve the prompt engineering problems of LLMs in document-level event extraction but also promote the development of event extraction technology, providing new research perspectives for other tasks in the NLP field.
Read more8/13/2024

0
Synergetic Event Understanding: A Collaborative Approach to Cross-Document Event Coreference Resolution with Large Language Models
Qingkai Min, Qipeng Guo, Xiangkun Hu, Songfang Huang, Zheng Zhang, Yue Zhang
Cross-document event coreference resolution (CDECR) involves clustering event mentions across multiple documents that refer to the same real-world events. Existing approaches utilize fine-tuning of small language models (SLMs) like BERT to address the compatibility among the contexts of event mentions. However, due to the complexity and diversity of contexts, these models are prone to learning simple co-occurrences. Recently, large language models (LLMs) like ChatGPT have demonstrated impressive contextual understanding, yet they encounter challenges in adapting to specific information extraction (IE) tasks. In this paper, we propose a collaborative approach for CDECR, leveraging the capabilities of both a universally capable LLM and a task-specific SLM. The collaborative strategy begins with the LLM accurately and comprehensively summarizing events through prompting. Then, the SLM refines its learning of event representations based on these insights during fine-tuning. Experimental results demonstrate that our approach surpasses the performance of both the large and small language models individually, forming a complementary advantage. Across various datasets, our approach achieves state-of-the-art performance, underscoring its effectiveness in diverse scenarios.
Read more6/5/2024