CodexGraph: Bridging Large Language Models and Code Repositories via Code Graph Databases

0

Sign in to get full access
Overview
- Presents a framework called \framework that bridges large language models (LLMs) and code repositories through code graph databases
- Aims to enhance the ability of LLMs to understand and generate code by leveraging structured code representations
- Includes a technical explanation of the \framework architecture and a critical analysis of the research
Plain English Explanation
The provided paper introduces a new framework called \framework that aims to improve the ability of large language models (LLMs) to work with code. LLMs are powerful AI systems that can understand and generate human language, but they often struggle with tasks involving code and programming.
\framework addresses this challenge by connecting LLMs with code graph databases - structured representations of code that capture the relationships between different code elements. By integrating LLMs with these code graphs, \framework allows the language models to better comprehend the syntax, semantics, and structure of code, enabling them to perform tasks like code generation, debugging, and refactoring more effectively.
The key idea behind \framework is to leverage the strengths of both LLMs (natural language understanding) and code graph databases (structured code representation) to create a more powerful and versatile system for working with code. This could have significant implications for software development, programming education, and other fields where the ability to understand and manipulate code is crucial.
Technical Explanation
The \framework architecture consists of several key components:
- Code Graph Database: A graph-based representation of code that captures the relationships between different code elements, such as variables, functions, and data structures.
- LLM Integration: A module that integrates the LLM with the code graph database, allowing the language model to access and reason about the structured code representations.
- Code-Aware LLM Fine-Tuning: A process of fine-tuning the LLM on a large corpus of code-related data, enabling it to better understand and generate code.
- Code Generation and Manipulation: Capabilities that allow the LLM to generate new code, modify existing code, and perform other code-related tasks by leveraging the code graph database.
The authors evaluate \framework on a range of code-related tasks, such as code completion, code generation, and code summarization, demonstrating significant improvements over baseline LLM approaches that do not use structured code representations.
Critical Analysis
The paper presents a well-designed and promising approach to bridging LLMs and code repositories, but it also acknowledges several limitations and areas for further research:
- The performance of \framework is still dependent on the quality and coverage of the underlying code graph database, which may be challenging to build and maintain for large-scale code repositories.
- The paper does not address potential privacy and security concerns that may arise when integrating LLMs with sensitive code repositories.
- The authors note that further research is needed to fully understand the capabilities and limitations of \framework, especially in terms of its generalization to diverse programming languages and code domains.
Despite these caveats, the \framework approach represents a significant step forward in the quest to enhance the code-related capabilities of large language models, with potential implications for a wide range of applications in software engineering and beyond.
Conclusion
The \framework paper presents a novel framework that bridges large language models and code repositories through the use of structured code graph databases. By integrating LLMs with these code representations, \framework aims to improve the ability of language models to understand, generate, and manipulate code, which could have far-reaching implications for software development, programming education, and other fields where code is a critical component.
While the paper acknowledges some limitations and areas for further research, the \framework approach is a promising step forward in the quest to enhance the code-related capabilities of large language models, and it is likely to inspire further innovation and exploration in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CodexGraph: Bridging Large Language Models and Code Repositories via Code Graph Databases
Xiangyan Liu, Bo Lan, Zhiyuan Hu, Yang Liu, Zhicheng Zhang, Fei Wang, Michael Shieh, Wenmeng Zhou
Large Language Models (LLMs) excel in stand-alone code tasks like HumanEval and MBPP, but struggle with handling entire code repositories. This challenge has prompted research on enhancing LLM-codebase interaction at a repository scale. Current solutions rely on similarity-based retrieval or manual tools and APIs, each with notable drawbacks. Similarity-based retrieval often has low recall in complex tasks, while manual tools and APIs are typically task-specific and require expert knowledge, reducing their generalizability across diverse code tasks and real-world applications. To mitigate these limitations, we introduce CodexGraph, a system that integrates LLM agents with graph database interfaces extracted from code repositories. By leveraging the structural properties of graph databases and the flexibility of the graph query language, CodexGraph enables the LLM agent to construct and execute queries, allowing for precise, code structure-aware context retrieval and code navigation. We assess CodexGraph using three benchmarks: CrossCodeEval, SWE-bench, and EvoCodeBench. Additionally, we develop five real-world coding applications. With a unified graph database schema, CodexGraph demonstrates competitive performance and potential in both academic and real-world environments, showcasing its versatility and efficacy in software engineering. Our application demo: https://github.com/modelscope/modelscope-agent/tree/master/apps/codexgraph_agent.
Read more8/13/2024

0
CodeGraph: Enhancing Graph Reasoning of LLMs with Code
Qiaolong Cai, Zhaowei Wang, Shizhe Diao, James Kwok, Yangqiu Song
With the increasing popularity of large language models (LLMs), reasoning on basic graph algorithm problems is an essential intermediate step in assessing their abilities to process and infer complex graph reasoning tasks. Existing methods usually convert graph-structured data to textual descriptions and then use LLMs for reasoning and computation. However, LLMs often produce computation errors on arithmetic parts in basic graph algorithm problems, such as counting number of edges. In addition, they struggle to control or understand the output of the reasoning process, raising concerns about whether LLMs are simply guessing. In this paper, we introduce CodeGraph, a method that encodes graph problem solutions as code. The methods solve new graph problems by learning from exemplars, generating programs, and executing them via a program interpreter. Using the few-shot setting, we evaluate CodeGraph with the base LLM being GPT-3.5 Turbo, Llama3-70B Instruct, Mixtral-8x22B Instruct, and Mixtral-8x7B Instruct. Experimental results on six tasks with six graph encoding methods in the GraphQA dataset demonstrate that CodeGraph can boost performance on graph reasoning tasks inside LLMs by 1.3% to 58.6%, depending on the task. Compared to the existing methods, CodeGraph demonstrates strong performance on arithmetic problems in graph tasks and offers a more controllable and interpretable approach to the reasoning process.
Read more8/27/2024
0
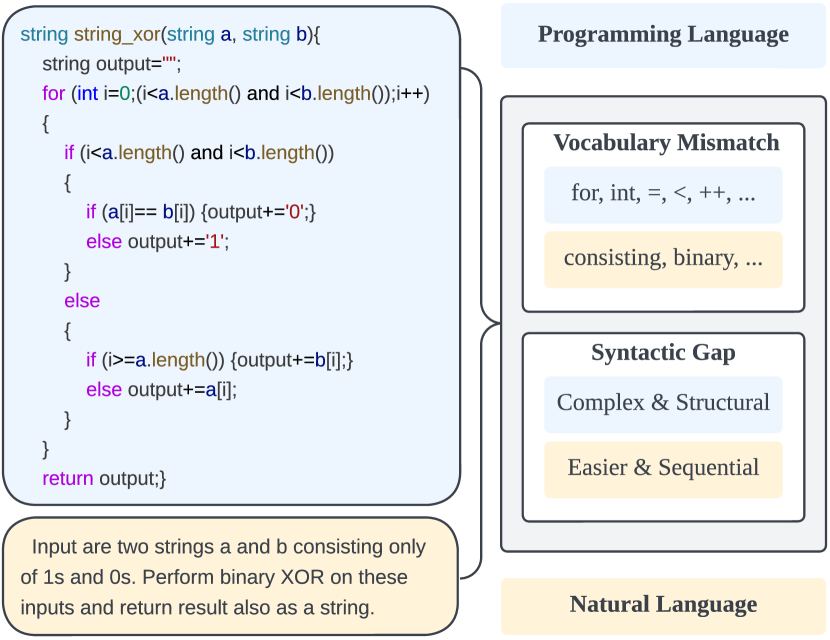
CodeGRAG: Extracting Composed Syntax Graphs for Retrieval Augmented Cross-Lingual Code Generation
Kounianhua Du, Renting Rui, Huacan Chai, Lingyue Fu, Wei Xia, Yasheng Wang, Ruiming Tang, Yong Yu, Weinan Zhang
Utilizing large language models to generate codes has shown promising meaning in software development revolution. Despite the intelligence shown by the general large language models, their specificity in code generation can still be improved due to the syntactic gap and mismatched vocabulary existing among natural language and different programming languages. In addition, programming languages are inherently logical and complex, making them hard to be correctly generated. Existing methods rely on multiple prompts to the large language model to explore better solutions, which is expensive. In this paper, we propose Syntax Graph Retrieval Augmented Code Generation (CodeGRAG) to enhance the performance of LLMs in single-round code generation tasks. CodeGRAG extracts and summarizes the control flow and data flow of code blocks to fill the gap between programming languages and natural language. The extracted external structural knowledge models the inherent flows of code blocks, which can facilitate LLMs for better understanding of code syntax and serve as a bridge among different programming languages. CodeGRAG significantly improves the code generation ability of LLMs and can even offer performance gain for cross-lingual code generation, e.g., C++ for Python.
Read more5/7/2024
💬
0
ML-Bench: Evaluating Large Language Models and Agents for Machine Learning Tasks on Repository-Level Code
Xiangru Tang, Yuliang Liu, Zefan Cai, Yanjun Shao, Junjie Lu, Yichi Zhang, Zexuan Deng, Helan Hu, Kaikai An, Ruijun Huang, Shuzheng Si, Sheng Chen, Haozhe Zhao, Liang Chen, Yan Wang, Tianyu Liu, Zhiwei Jiang, Baobao Chang, Yin Fang, Yujia Qin, Wangchunshu Zhou, Yilun Zhao, Arman Cohan, Mark Gerstein
Despite Large Language Models (LLMs) like GPT-4 achieving impressive results in function-level code generation, they struggle with repository-scale code understanding (e.g., coming up with the right arguments for calling routines), requiring a deeper comprehension of complex file interactions. Also, recently, people have developed LLM agents that attempt to interact with repository code (e.g., compiling and evaluating its execution), prompting the need to evaluate their performance. These gaps have motivated our development of ML-Bench, a benchmark rooted in real-world programming applications that leverage existing code repositories to perform tasks. Addressing the need for LLMs to interpret long code contexts and translate instructions into precise, executable scripts, ML-Bench encompasses annotated 9,641 examples across 18 GitHub repositories, challenging LLMs to accommodate user-specified arguments and documentation intricacies effectively. To evaluate both LLMs and AI agents, two setups are employed: ML-LLM-Bench for assessing LLMs' text-to-code conversion within a predefined deployment environment, and ML-Agent-Bench for testing autonomous agents in an end-to-end task execution within a Linux sandbox environment. Our findings indicate that while GPT-4o leads with a Pass@5 rate surpassing 50%, there remains significant scope for improvement, highlighted by issues such as hallucinated outputs and difficulties with bash script generation. Notably, in the more demanding ML-Agent-Bench, GPT-4o achieves a 76.47% success rate, reflecting the efficacy of iterative action and feedback in complex task resolution. Our code, dataset, and models are available at https://github.com/gersteinlab/ML-bench.
Read more8/22/2024