CodeGRAG: Extracting Composed Syntax Graphs for Retrieval Augmented Cross-Lingual Code Generation
2405.02355
0
0
Abstract
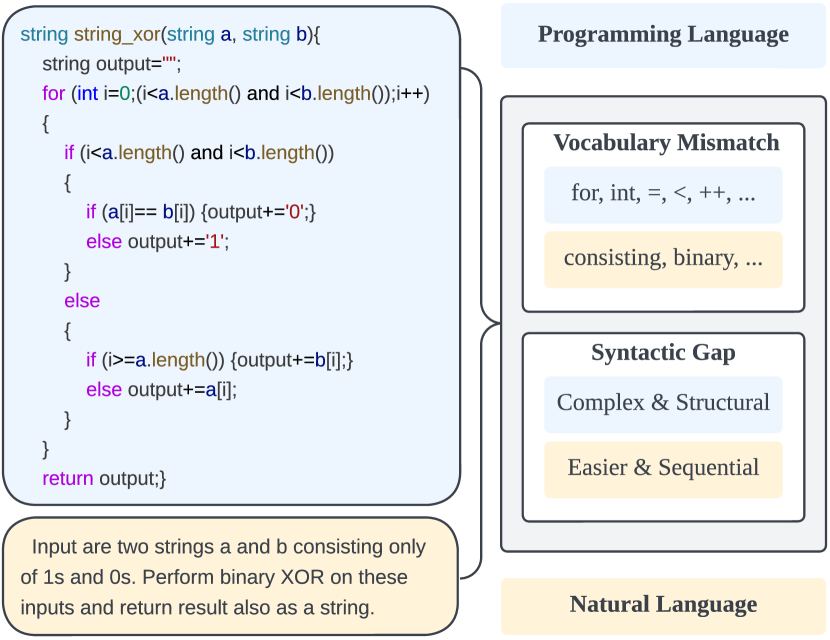
Utilizing large language models to generate codes has shown promising meaning in software development revolution. Despite the intelligence shown by the general large language models, their specificity in code generation can still be improved due to the syntactic gap and mismatched vocabulary existing among natural language and different programming languages. In addition, programming languages are inherently logical and complex, making them hard to be correctly generated. Existing methods rely on multiple prompts to the large language model to explore better solutions, which is expensive. In this paper, we propose Syntax Graph Retrieval Augmented Code Generation (CodeGRAG) to enhance the performance of LLMs in single-round code generation tasks. CodeGRAG extracts and summarizes the control flow and data flow of code blocks to fill the gap between programming languages and natural language. The extracted external structural knowledge models the inherent flows of code blocks, which can facilitate LLMs for better understanding of code syntax and serve as a bridge among different programming languages. CodeGRAG significantly improves the code generation ability of LLMs and can even offer performance gain for cross-lingual code generation, e.g., C++ for Python.
Create account to get full access
Overview
- The paper presents a new method called CodeGRAG (Code Generation Retrieval Augmented Graph) for cross-lingual code generation.
- It extracts "composed syntax graphs" from code to improve code retrieval and augment language models for better code generation.
- The approach aims to address challenges in cross-lingual code generation, where a model must generate code in a target language given a prompt in a different source language.
Plain English Explanation
CodeGRAG is a system that helps computers write code in one language based on instructions given in another language. This is a challenging task, as the computer needs to understand the meaning and structure of the code, even when the instructions are in a different language.
The key idea behind CodeGRAG is to extract a special type of graph representation from the code, called a "composed syntax graph." This graph captures the structure and relationships between different parts of the code. By using this graph representation, the system can better understand the code and generate new code that matches the intended meaning, even when the instructions are in a different language.
The graph-based approach used in CodeGRAG helps the computer understand the code more deeply, going beyond just the surface-level text. This allows the system to generate code that is more accurate and relevant to the given instructions, even in cross-lingual scenarios.
Overall, CodeGRAG represents an important step forward in the field of cross-lingual code generation, which has many practical applications, such as helping developers work with code in different languages or enabling better translation of code between programming languages.
Technical Explanation
The key innovation in CodeGRAG is the extraction of "composed syntax graphs" from code snippets. These graphs capture the hierarchical structure and relationships between different elements of the code, such as functions, variables, and control flow.
By representing the code in this graph-based format, the system can better understand the underlying semantics and logic, rather than just the surface-level syntax. This allows the cross-lingual code generation model to generate more accurate and relevant code, even when the input instructions are in a different language.
The CodeGRAG approach involves several steps:
- Parsing the input code to extract the composed syntax graph.
- Encoding the graph structure using a graph neural network.
- Combining the graph representation with a text-based language model to generate the output code.
The graph-based augmentation helps the language model better understand the underlying code structure and logic, leading to improved cross-lingual code generation performance compared to text-only approaches.
Critical Analysis
The CodeGRAG paper presents a promising approach to address the challenges of cross-lingual code generation. The use of composed syntax graphs is a novel and well-justified technique, as it allows the system to better capture the semantic structure of the code.
One potential limitation of the approach is the reliance on accurate parsing of the input code to extract the graph representation. If the parsing step introduces errors, it could negatively impact the downstream code generation performance. The authors acknowledge this challenge and suggest further research into more robust parsing techniques.
Additionally, the evaluation of CodeGRAG is focused on a specific set of programming languages and tasks. It would be valuable to see how the approach generalizes to a wider range of languages and application domains, especially for less commonly used or more complex programming languages.
Overall, the CodeGRAG paper presents an interesting and promising direction for improving cross-lingual code generation, with the potential for further refinement and broader applicability.
Conclusion
The CodeGRAG system represents an important advancement in the field of cross-lingual code generation. By extracting and leveraging composed syntax graphs from the input code, the system is able to better understand the underlying structure and semantics, leading to more accurate and relevant code generation, even when the instructions are provided in a different language.
This graph-based approach has the potential to significantly improve the capabilities of language models in cross-lingual programming tasks, with applications ranging from code translation to automated programming assistance. As the research in this area continues to evolve, we can expect to see further improvements and expanded use cases for systems like CodeGRAG.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
GRAG: Graph Retrieval-Augmented Generation
Yuntong Hu, Zhihan Lei, Zheng Zhang, Bo Pan, Chen Ling, Liang Zhao
0
0
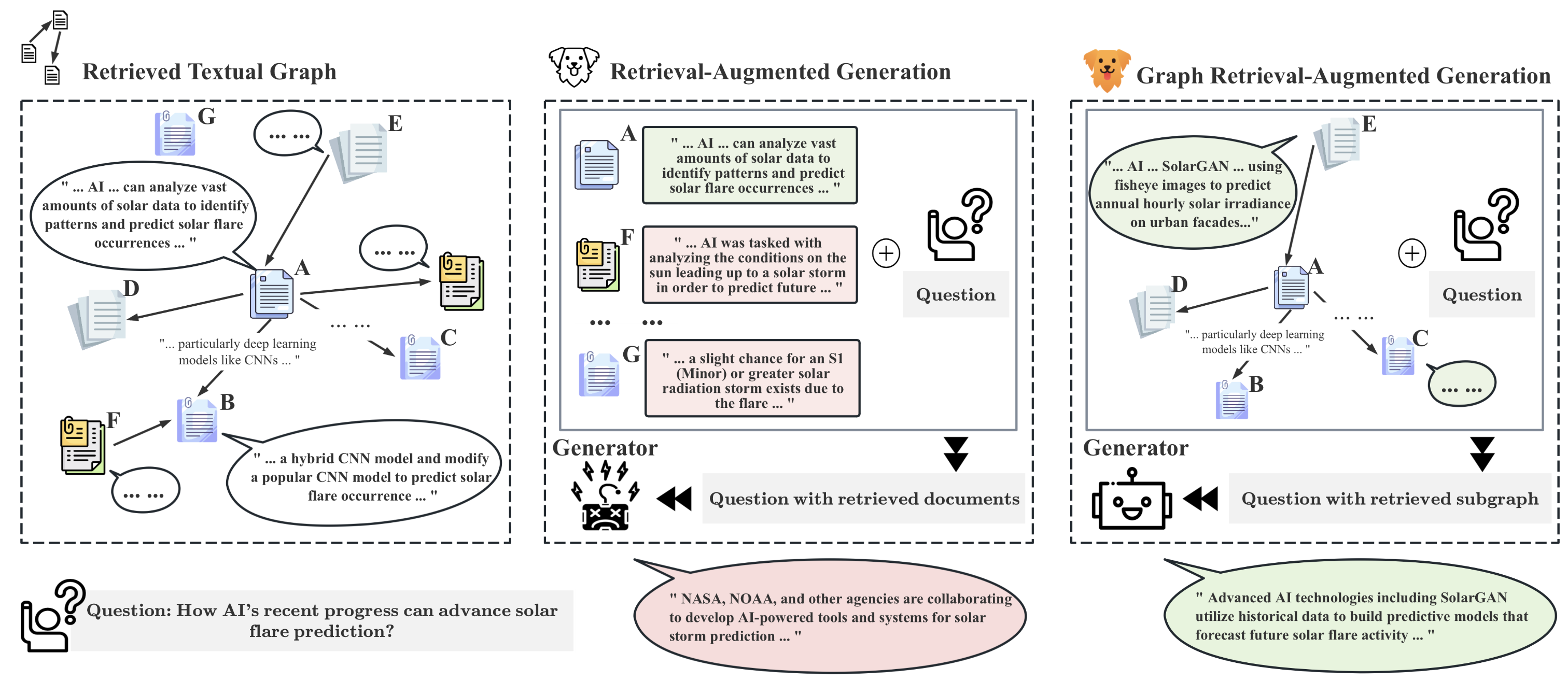
While Retrieval-Augmented Generation (RAG) enhances the accuracy and relevance of responses by generative language models, it falls short in graph-based contexts where both textual and topological information are important. Naive RAG approaches inherently neglect the structural intricacies of textual graphs, resulting in a critical gap in the generation process. To address this challenge, we introduce $textbf{Graph Retrieval-Augmented Generation (GRAG)}$, which significantly enhances both the retrieval and generation processes by emphasizing the importance of subgraph structures. Unlike RAG approaches that focus solely on text-based entity retrieval, GRAG maintains an acute awareness of graph topology, which is crucial for generating contextually and factually coherent responses. Our GRAG approach consists of four main stages: indexing of $k$-hop ego-graphs, graph retrieval, soft pruning to mitigate the impact of irrelevant entities, and generation with pruned textual subgraphs. GRAG's core workflow-retrieving textual subgraphs followed by soft pruning-efficiently identifies relevant subgraph structures while avoiding the computational infeasibility typical of exhaustive subgraph searches, which are NP-hard. Moreover, we propose a novel prompting strategy that achieves lossless conversion from textual subgraphs to hierarchical text descriptions. Extensive experiments on graph multi-hop reasoning benchmarks demonstrate that in scenarios requiring multi-hop reasoning on textual graphs, our GRAG approach significantly outperforms current state-of-the-art RAG methods while effectively mitigating hallucinations.
5/28/2024

CodeRAG-Bench: Can Retrieval Augment Code Generation?
Zora Zhiruo Wang, Akari Asai, Xinyan Velocity Yu, Frank F. Xu, Yiqing Xie, Graham Neubig, Daniel Fried
0
0
While language models (LMs) have proven remarkably adept at generating code, many programs are challenging for LMs to generate using their parametric knowledge alone. Providing external contexts such as library documentation can facilitate generating accurate and functional code. Despite the success of retrieval-augmented generation (RAG) in various text-oriented tasks, its potential for improving code generation remains under-explored. In this work, we conduct a systematic, large-scale analysis by asking: in what scenarios can retrieval benefit code generation models? and what challenges remain? We first curate a comprehensive evaluation benchmark, CodeRAG-Bench, encompassing three categories of code generation tasks, including basic programming, open-domain, and repository-level problems. We aggregate documents from five sources for models to retrieve contexts: competition solutions, online tutorials, library documentation, StackOverflow posts, and GitHub repositories. We examine top-performing models on CodeRAG-Bench by providing contexts retrieved from one or multiple sources. While notable gains are made in final code generation by retrieving high-quality contexts across various settings, our analysis reveals room for improvement -- current retrievers still struggle to fetch useful contexts especially with limited lexical overlap, and generators fail to improve with limited context lengths or abilities to integrate additional contexts. We hope CodeRAG-Bench serves as an effective testbed to encourage further development of advanced code-oriented RAG methods.
6/21/2024

Empowering Large Language Models to Set up a Knowledge Retrieval Indexer via Self-Learning
Xun Liang, Simin Niu, Zhiyu li, Sensen Zhang, Shichao Song, Hanyu Wang, Jiawei Yang, Feiyu Xiong, Bo Tang, Chenyang Xi
0
0
Retrieval-Augmented Generation (RAG) offers a cost-effective approach to injecting real-time knowledge into large language models (LLMs). Nevertheless, constructing and validating high-quality knowledge repositories require considerable effort. We propose a pre-retrieval framework named Pseudo-Graph Retrieval-Augmented Generation (PG-RAG), which conceptualizes LLMs as students by providing them with abundant raw reading materials and encouraging them to engage in autonomous reading to record factual information in their own words. The resulting concise, well-organized mental indices are interconnected through common topics or complementary facts to form a pseudo-graph database. During the retrieval phase, PG-RAG mimics the human behavior in flipping through notes, identifying fact paths and subsequently exploring the related contexts. Adhering to the principle of the path taken by many is the best, it integrates highly corroborated fact paths to provide a structured and refined sub-graph assisting LLMs. We validated PG-RAG on three specialized question-answering datasets. In single-document tasks, PG-RAG significantly outperformed the current best baseline, KGP-LLaMA, across all key evaluation metrics, with an average overall performance improvement of 11.6%. Specifically, its BLEU score increased by approximately 14.3%, and the QE-F1 metric improved by 23.7%. In multi-document scenarios, the average metrics of PG-RAG were at least 2.35% higher than the best baseline. Notably, the BLEU score and QE-F1 metric showed stable improvements of around 7.55% and 12.75%, respectively. Our code: https://github.com/IAAR-Shanghai/PGRAG.
5/28/2024
Rewriting the Code: A Simple Method for Large Language Model Augmented Code Search
Haochen Li, Xin Zhou, Zhiqi Shen
0
0
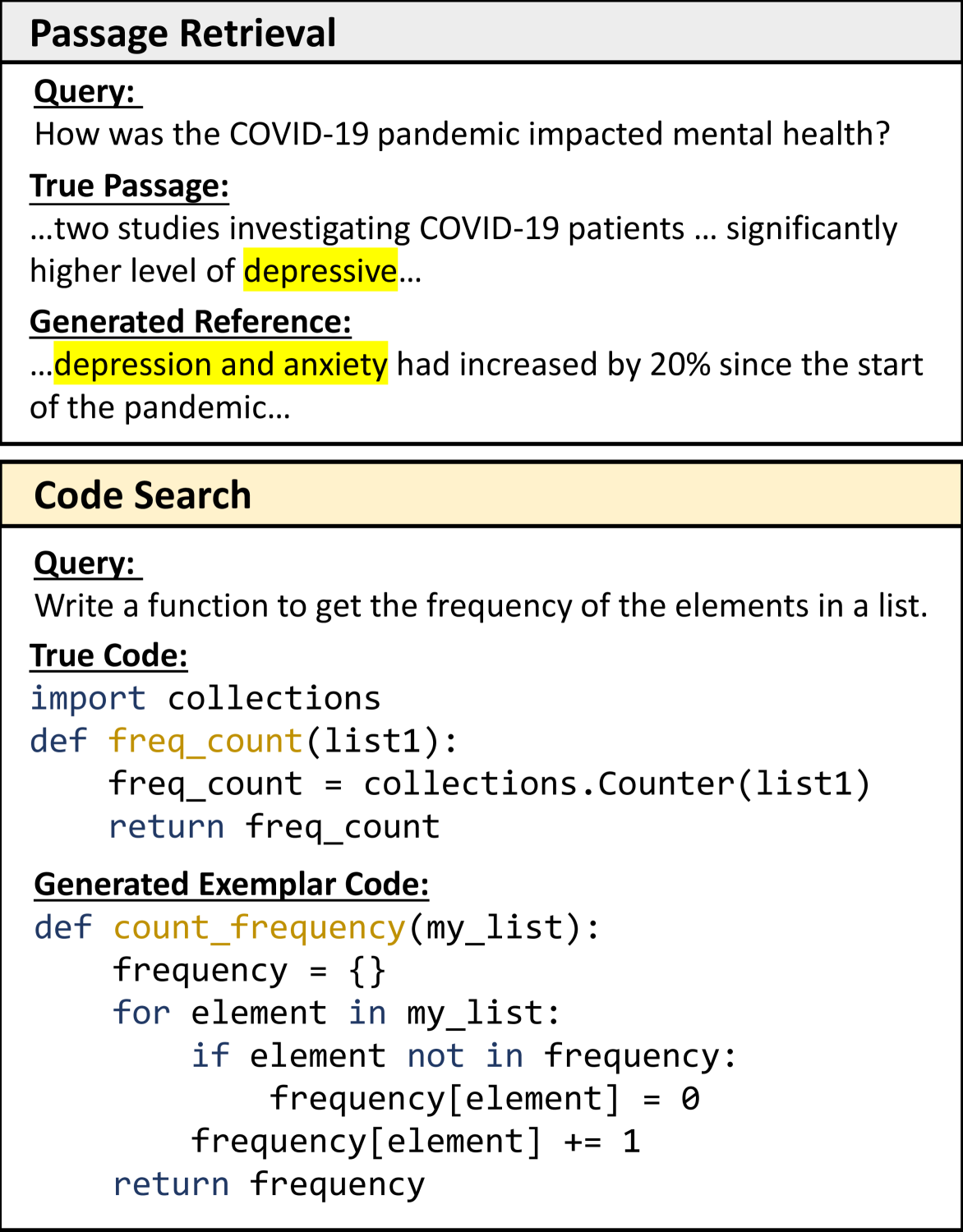
In code search, the Generation-Augmented Retrieval (GAR) framework, which generates exemplar code snippets to augment queries, has emerged as a promising strategy to address the principal challenge of modality misalignment between code snippets and natural language queries, particularly with the demonstrated code generation capabilities of Large Language Models (LLMs). Nevertheless, our preliminary investigations indicate that the improvements conferred by such an LLM-augmented framework are somewhat constrained. This limitation could potentially be ascribed to the fact that the generated codes, albeit functionally accurate, frequently display a pronounced stylistic deviation from the ground truth code in the codebase. In this paper, we extend the foundational GAR framework and propose a simple yet effective method that additionally Rewrites the Code (ReCo) within the codebase for style normalization. Experimental results demonstrate that ReCo significantly boosts retrieval accuracy across sparse (up to 35.7%), zero-shot dense (up to 27.6%), and fine-tuned dense (up to 23.6%) retrieval settings in diverse search scenarios. To further elucidate the advantages of ReCo and stimulate research in code style normalization, we introduce Code Style Similarity, the first metric tailored to quantify stylistic similarities in code. Notably, our empirical findings reveal the inadequacy of existing metrics in capturing stylistic nuances. The source code and data are available at url{https://github.com/Alex-HaochenLi/ReCo}.
6/4/2024