ML-Bench: Evaluating Large Language Models and Agents for Machine Learning Tasks on Repository-Level Code
2311.09835
0
0
💬
Abstract
Despite Large Language Models (LLMs) like GPT-4 achieving impressive results in function-level code generation, they struggle with repository-scale code understanding (e.g., coming up with the right arguments for calling routines), requiring a deeper comprehension of complex file interactions. Also, recently, people have developed LLM agents that attempt to interact with repository code (e.g., compiling and evaluating its execution), prompting the need to evaluate their performance. These gaps have motivated our development of ML-Bench, a benchmark rooted in real-world programming applications that leverage existing code repositories to perform tasks. Addressing the need for LLMs to interpret long code contexts and translate instructions into precise, executable scripts, ML-Bench encompasses annotated 9,641 examples across 18 GitHub repositories, challenging LLMs to accommodate user-specified arguments and documentation intricacies effectively. To evaluate both LLMs and AI agents, two setups are employed: ML-LLM-Bench for assessing LLMs' text-to-code conversion within a predefined deployment environment, and ML-Agent-Bench for testing autonomous agents in an end-to-end task execution within a Linux sandbox environment. Our findings indicate that while GPT-4o leads with a Pass@5 rate surpassing 50%, there remains significant scope for improvement, highlighted by issues such as hallucinated outputs and difficulties with bash script generation. Notably, in the more demanding ML-Agent-Bench, GPT-4o achieves a 76.47% success rate, reflecting the efficacy of iterative action and feedback in complex task resolution. Our code, dataset, and models are available at https://github.com/gersteinlab/ML-bench.
Create account to get full access
Overview
- The paper discusses the development of a benchmark called ML-Bench to evaluate the performance of large language models (LLMs) in code-related tasks.
- ML-Bench is designed to assess LLMs' ability to understand complex code repositories and translate instructions into executable scripts.
- The paper compares the performance of LLMs, including GPT-4o, on two setups: ML-LLM-Bench for text-to-code conversion and ML-Agent-Bench for end-to-end task execution.
Plain English Explanation
Large language models like GPT-4 have made impressive strides in generating functional code. However, they still struggle with understanding the full context of complex code repositories and translating high-level instructions into precise, executable scripts. To address this, the researchers developed a benchmark called ML-Bench, which uses real-world code repositories to test LLMs' capabilities.
ML-Bench consists of over 9,600 annotated examples across 18 GitHub repositories, challenging LLMs to handle user-specified arguments and documentation intricacies. The researchers used two setups to evaluate the models: ML-LLM-Bench, which assesses text-to-code conversion within a predefined environment, and ML-Agent-Bench, which tests autonomous agents in an end-to-end task execution within a Linux sandbox.
The results showed that while GPT-4o had a strong performance, with a Pass@5 rate surpassing 50% in the ML-LLM-Bench setup, there is still significant room for improvement. Issues like hallucinated outputs and difficulties with bash script generation were observed. Notably, in the more challenging ML-Agent-Bench setup, GPT-4o achieved a 76.47% success rate, suggesting that iterative action and feedback can be effective in resolving complex tasks.
Technical Explanation
The paper presents the development of ML-Bench, a benchmark designed to evaluate the performance of large language models (LLMs) in code-related tasks. The benchmark is rooted in real-world programming applications and leverages existing code repositories to challenge LLMs to accommodate user-specified arguments and documentation intricacies.
The authors recognize the need for LLMs to interpret long code contexts and translate instructions into precise, executable scripts. To address this, ML-Bench encompasses 9,641 annotated examples across 18 GitHub repositories, covering a variety of programming tasks and file interactions.
To evaluate both LLMs and AI agents, the researchers employ two setups:
- ML-LLM-Bench: This setup assesses LLMs' text-to-code conversion capabilities within a predefined deployment environment.
- ML-Agent-Bench: This setup tests autonomous agents in an end-to-end task execution within a Linux sandbox environment.
The authors report that while GPT-4o leads with a Pass@5 rate surpassing 50% in the ML-LLM-Bench setup, there are still significant challenges, such as hallucinated outputs and difficulties with bash script generation. Notably, in the more demanding ML-Agent-Bench setup, GPT-4o achieves a 76.47% success rate, suggesting the effectiveness of iterative action and feedback in complex task resolution.
The paper's findings highlight the need for further advancements in LLMs' understanding of code repositories and their ability to translate high-level instructions into executable scripts. The development of benchmarks like ML-Bench and the exploration of LLM agents and their code editing capabilities are important steps in advancing the field of class-level code generation from natural language.
Critical Analysis
The paper provides a comprehensive and well-designed evaluation of LLMs' performance in code-related tasks. The development of ML-Bench is a notable contribution, as it addresses the need for benchmarks that challenge LLMs to understand complex code repositories and translate high-level instructions into executable scripts.
However, the paper acknowledges that there is still significant room for improvement in LLMs' performance, particularly in areas like hallucinated outputs and bash script generation. The researchers also highlight the increased complexity of the ML-Agent-Bench setup, which tests autonomous agents in an end-to-end task execution environment.
One potential area for further research could be exploring the integration of additional feedback mechanisms or iterative learning approaches to help LLMs better handle the nuances and complexities of real-world code repositories. Additionally, the paper could have discussed the potential impact of advancements in this field on the broader software development ecosystem and the implications for the future of code generation and automation.
Conclusion
The development of ML-Bench represents an important step in evaluating the capabilities of large language models in code-related tasks. While the current state-of-the-art models, like GPT-4o, have shown impressive performance, the paper highlights the need for further advancements to address the challenges of understanding complex code repositories and translating high-level instructions into precise, executable scripts.
The insights gained from this research could contribute to the advancement of class-level code generation from natural language and the development of more capable LLM agents that can effectively handle code editing tasks. As the field of large language models continues to evolve, benchmarks like ML-Bench will play a crucial role in pushing the boundaries of what these models can achieve in the context of programming and software development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
MLAgentBench: Evaluating Language Agents on Machine Learning Experimentation
Qian Huang, Jian Vora, Percy Liang, Jure Leskovec
0
0
A central aspect of machine learning research is experimentation, the process of designing and running experiments, analyzing the results, and iterating towards some positive outcome (e.g., improving accuracy). Could agents driven by powerful language models perform machine learning experimentation effectively? To answer this question, we introduce MLAgentBench, a suite of 13 tasks ranging from improving model performance on CIFAR-10 to recent research problems like BabyLM. For each task, an agent can perform actions like reading/writing files, executing code, and inspecting outputs. We then construct an agent that can perform ML experimentation based on ReAct framework. We benchmark agents based on Claude v1.0, Claude v2.1, Claude v3 Opus, GPT-4, GPT-4-turbo, Gemini-Pro, and Mixtral and find that a Claude v3 Opus agent is the best in terms of success rate. It can build compelling ML models over many tasks in MLAgentBench with 37.5% average success rate. Our agents also display highly interpretable plans and actions. However, the success rates vary considerably; they span from 100% on well-established older datasets to as low as 0% on recent Kaggle challenges created potentially after the underlying LM was trained. Finally, we identify several key challenges for LM-based agents such as long-term planning and reducing hallucination. Our code is released at https://github.com/snap-stanford/MLAgentBench.
4/16/2024
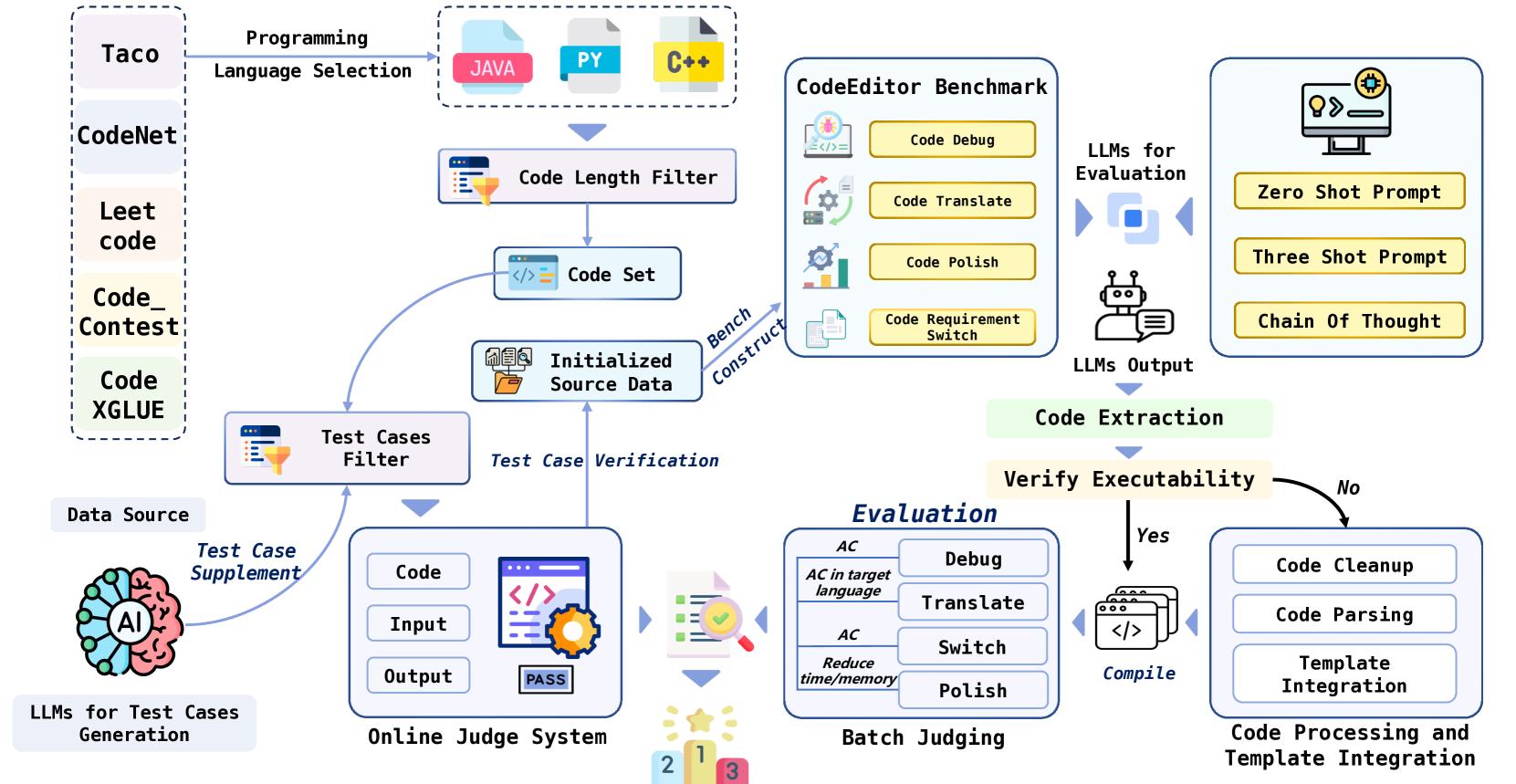
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Jiawei Guo, Ziming Li, Xueling Liu, Kaijing Ma, Tianyu Zheng, Zhouliang Yu, Ding Pan, Yizhi LI, Ruibo Liu, Yue Wang, Shuyue Guo, Xingwei Qu, Xiang Yue, Ge Zhang, Wenhu Chen, Jie Fu
0
0
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
4/9/2024
💬
Evaluation of the Programming Skills of Large Language Models
Luc Bryan Heitz, Joun Chamas, Christopher Scherb
0
0
The advent of Large Language Models (LLM) has revolutionized the efficiency and speed with which tasks are completed, marking a significant leap in productivity through technological innovation. As these chatbots tackle increasingly complex tasks, the challenge of assessing the quality of their outputs has become paramount. This paper critically examines the output quality of two leading LLMs, OpenAI's ChatGPT and Google's Gemini AI, by comparing the quality of programming code generated in both their free versions. Through the lens of a real-world example coupled with a systematic dataset, we investigate the code quality produced by these LLMs. Given their notable proficiency in code generation, this aspect of chatbot capability presents a particularly compelling area for analysis. Furthermore, the complexity of programming code often escalates to levels where its verification becomes a formidable task, underscoring the importance of our study. This research aims to shed light on the efficacy and reliability of LLMs in generating high-quality programming code, an endeavor that has significant implications for the field of software development and beyond.
5/24/2024

Large Language Models as Test Case Generators: Performance Evaluation and Enhancement
Kefan Li, Yuan Yuan
0
0
Code generation with Large Language Models (LLMs) has been extensively studied and achieved remarkable progress. As a complementary aspect to code generation, test case generation is of crucial importance in ensuring the quality and reliability of code. However, using LLMs as test case generators has been much less explored. Current research along this line primarily focuses on enhancing code generation with assistance from test cases generated by LLMs, while the performance of LLMs in test case generation alone has not been comprehensively examined. To bridge this gap, we conduct extensive experiments to study how well LLMs can generate high-quality test cases. We find that as the problem difficulty increases, state-of-the-art LLMs struggle to generate correct test cases, largely due to their inherent limitations in computation and reasoning. To mitigate this issue, we further propose a multi-agent framework called emph{TestChain} that decouples the generation of test inputs and test outputs. Notably, TestChain uses a ReAct format conversation chain for LLMs to interact with a Python interpreter in order to provide more accurate test outputs. Our results indicate that TestChain outperforms the baseline by a large margin. Particularly, in terms of the accuracy of test cases, TestChain using GPT-4 as the backbone achieves a 13.84% improvement over the baseline on the LeetCode-hard dataset.
4/23/2024