Coeditor: Leveraging Contextual Changes for Multi-round Code Auto-editing

0
🛠️
Sign in to get full access
Overview
- Developers spend significant time maintaining and refactoring existing code, but most prior work on generative models for code focuses solely on creating new code, overlooking the distinctive needs of editing existing code.
- This paper explores a multi-round code auto-editing setting, aiming to predict edits to a code region based on recent changes within the same codebase.
- The model, Coeditor, is a fine-tuned language model specifically designed for code editing tasks.
- The authors collected a code editing dataset from the commit histories of 1650 open-source Python projects for training and evaluation.
Plain English Explanation
Developers often need to make changes to existing code, such as fixing bugs or improving functionality. However, most of the research on using AI models to generate code has focused on creating entirely new code from scratch, rather than editing existing code.
The researchers in this paper wanted to explore a more realistic scenario where an AI model could help developers by suggesting edits to their existing code. They developed a model called Coeditor that is specifically trained to understand the context of the existing code and propose relevant edits.
To train and test their model, the researchers collected a large dataset of code changes from 1,650 open-source Python projects. This allowed them to simulate the process of a developer making a series of edits to their code and see how well the model could predict the next edit.
The key idea is that by taking into account the history of changes to the code, the model can make more informed suggestions for further improvements, similar to how a human developer would learn from past edits.
Technical Explanation
The researchers developed Coeditor, a fine-tuned language model specifically designed for code editing tasks. They represent code changes using a line diff format and employ static analysis to form large customized model contexts, ensuring the availability of appropriate information for prediction.
In a simplified single-round, single-edit task, Coeditor significantly outperformed GPT-3.5 and state-of-the-art open-source code completion models, bringing exact-match accuracy from 34.7% up to 60.4%. This demonstrates the benefits of incorporating editing history for code completion.
In a more realistic multi-round, multi-edit setting, the researchers observed substantial gains by iteratively conditioning the model on additional user edits. This suggests that Coeditor can effectively leverage the context of previous edits to make better predictions for the next step in the editing process.
The researchers have open-sourced their code, data, and model weights to encourage future research in this area. They have also released a VSCode extension powered by their model for interactive IDE usage, allowing developers to experience the benefits of Coeditor firsthand.
Critical Analysis
The researchers acknowledge several limitations and areas for further research. For example, they note that their dataset is limited to Python projects, and it would be valuable to extend the approach to other programming languages. Additionally, the current model does not consider the semantics of the code, which could be an important factor in predicting relevant edits.
One potential issue is that the model may struggle with more complex, context-dependent edits that require a deeper understanding of the code's functionality. The researchers mention that incorporating more advanced static analysis techniques or even dynamic analysis could help address this limitation.
Furthermore, the researchers do not explore the potential biases or limitations of their training data, which could impact the model's performance on a broader range of code editing scenarios. Investigating these biases and ensuring the model's fairness and robustness would be an important area for future research.
Overall, the Coeditor model represents a promising step towards more intelligent and context-aware code editing tools. However, further research is needed to address the limitations and extend the capabilities of such models to better support the diverse needs of software developers.
Conclusion
This paper presents a novel approach to code editing using a fine-tuned language model called Coeditor. By incorporating the history of code changes, Coeditor can make more informed and accurate suggestions for editing existing code, outperforming general-purpose code completion models.
The open-sourcing of the code, data, and model weights, as well as the release of a VSCode extension, demonstrates the researchers' commitment to advancing the field of code editing and encouraging further exploration in this area. As Coeditor and similar models continue to evolve, they have the potential to significantly improve the efficiency and productivity of software development workflows.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
Coeditor: Leveraging Contextual Changes for Multi-round Code Auto-editing
Jiayi Wei, Greg Durrett, Isil Dillig
Developers often dedicate significant time to maintaining and refactoring existing code. However, most prior work on generative models for code focuses solely on creating new code, overlooking the distinctive needs of editing existing code. In this work, we explore a multi-round code auto-editing setting, aiming to predict edits to a code region based on recent changes within the same codebase. Our model, Coeditor, is a fine-tuned language model specifically designed for code editing tasks. We represent code changes using a line diff format and employ static analysis to form large customized model contexts, ensuring the availability of appropriate information for prediction. We collect a code editing dataset from the commit histories of 1650 open-source Python projects for training and evaluation. In a simplified single-round, single-edit task, Coeditor significantly outperforms GPT-3.5 and SOTA open-source code completion models (bringing exact-match accuracy from 34.7 up to 60.4), demonstrating the benefits of incorporating editing history for code completion. In a multi-round, multi-edit setting, we observe substantial gains by iteratively conditioning on additional user edits. We have open-sourced our code, data, and model weights to encourage future research and have released a VSCode extension powered by our model for interactive IDE usage.
Read more4/30/2024
0
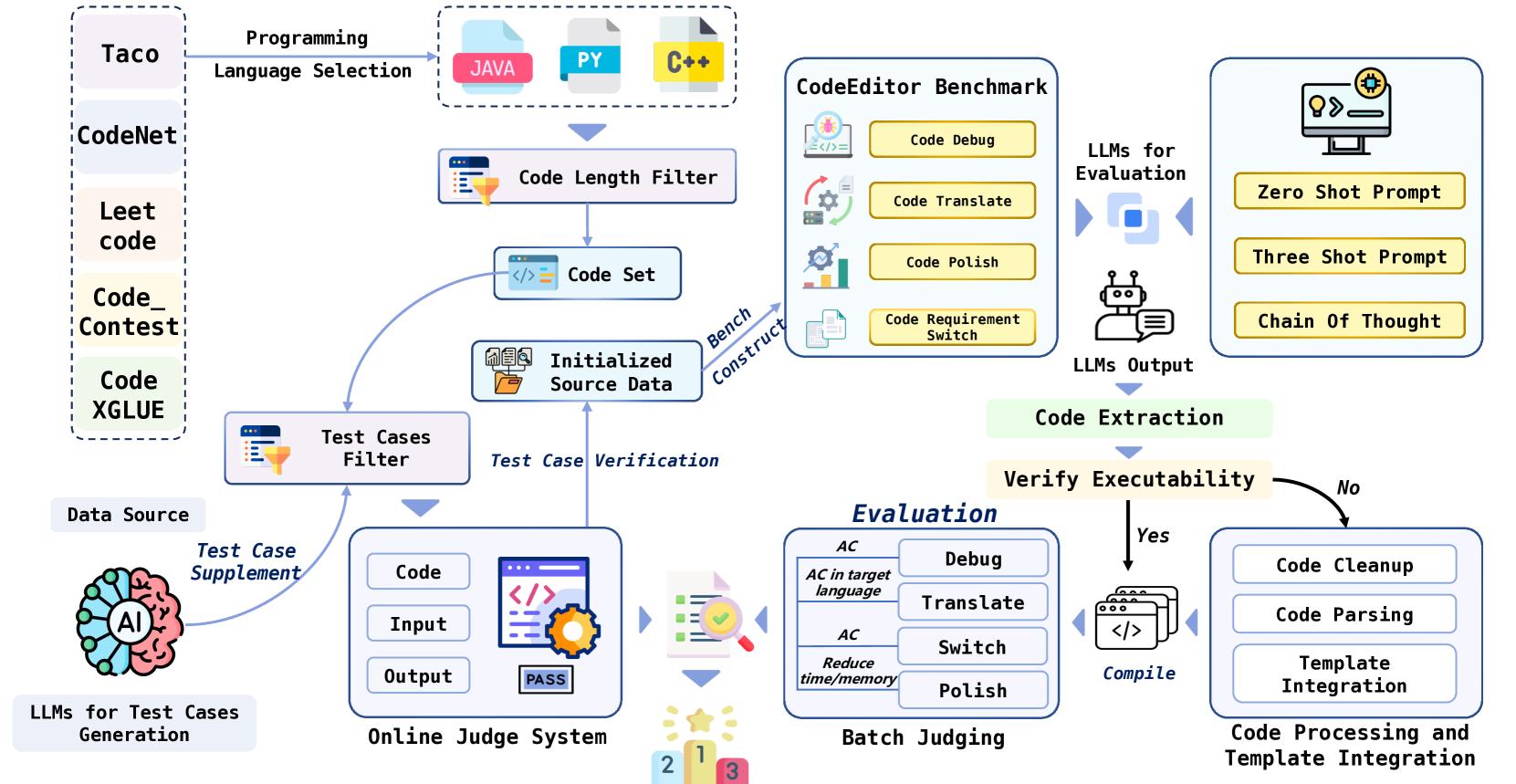
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Jiawei Guo, Ziming Li, Xueling Liu, Kaijing Ma, Tianyu Zheng, Zhouliang Yu, Ding Pan, Yizhi LI, Ruibo Liu, Yue Wang, Shuyue Guo, Xingwei Qu, Xiang Yue, Ge Zhang, Wenhu Chen, Jie Fu
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
Read more4/9/2024
💬
0
EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models
Peng Wang, Ningyu Zhang, Bozhong Tian, Zekun Xi, Yunzhi Yao, Ziwen Xu, Mengru Wang, Shengyu Mao, Xiaohan Wang, Siyuan Cheng, Kangwei Liu, Yuansheng Ni, Guozhou Zheng, Huajun Chen
Large Language Models (LLMs) usually suffer from knowledge cutoff or fallacy issues, which means they are unaware of unseen events or generate text with incorrect facts owing to outdated/noisy data. To this end, many knowledge editing approaches for LLMs have emerged -- aiming to subtly inject/edit updated knowledge or adjust undesired behavior while minimizing the impact on unrelated inputs. Nevertheless, due to significant differences among various knowledge editing methods and the variations in task setups, there is no standard implementation framework available for the community, which hinders practitioners from applying knowledge editing to applications. To address these issues, we propose EasyEdit, an easy-to-use knowledge editing framework for LLMs. It supports various cutting-edge knowledge editing approaches and can be readily applied to many well-known LLMs such as T5, GPT-J, LlaMA, etc. Empirically, we report the knowledge editing results on LlaMA-2 with EasyEdit, demonstrating that knowledge editing surpasses traditional fine-tuning in terms of reliability and generalization. We have released the source code on GitHub, along with Google Colab tutorials and comprehensive documentation for beginners to get started. Besides, we present an online system for real-time knowledge editing, and a demo video.
Read more6/26/2024
0
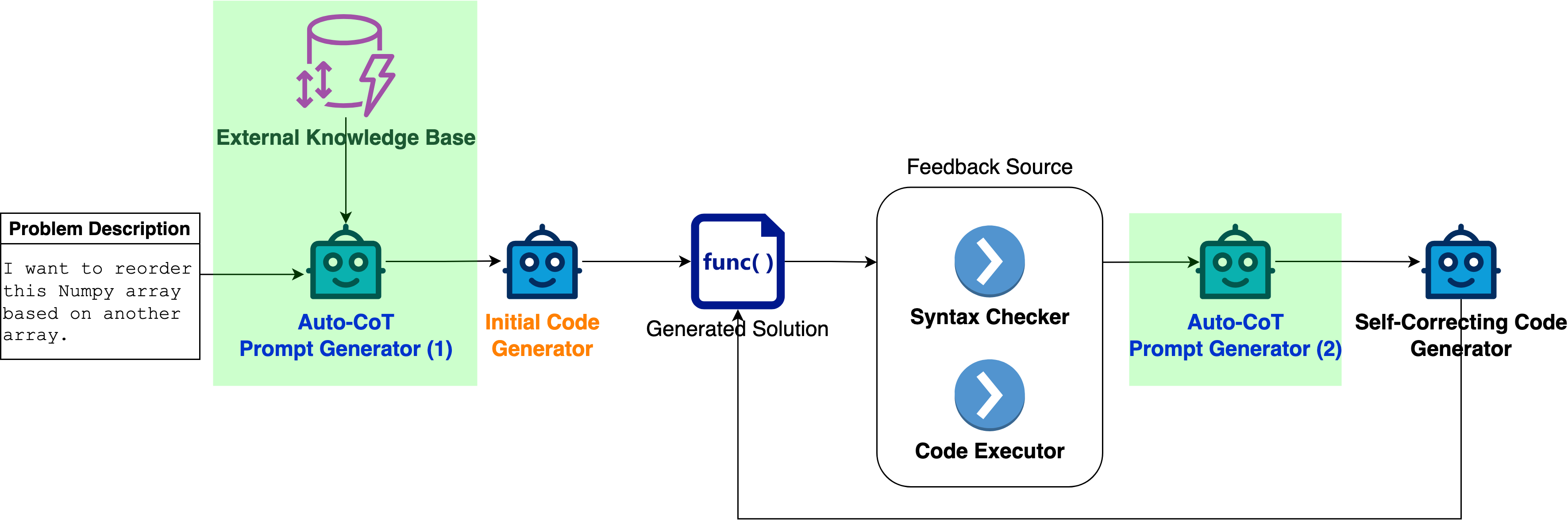
An Empirical Study on Self-correcting Large Language Models for Data Science Code Generation
Thai Tang Quoc, Duc Ha Minh, Tho Quan Thanh, Anh Nguyen-Duc
Large Language Models (LLMs) have recently advanced many applications on software engineering tasks, particularly the potential for code generation. Among contemporary challenges, code generated by LLMs often suffers from inaccuracies and hallucinations, requiring external inputs to correct. One recent strategy to fix these issues is to refine the code generated from LLMs using the input from the model itself (self-augmented). In this work, we proposed a novel method, namely CoT-SelfEvolve. CoT-SelfEvolve iteratively and automatically refines code through a self-correcting process, guided by a chain of thought constructed from real-world programming problem feedback. Focusing on data science code, including Python libraries such as NumPy and Pandas, our evaluations on the DS-1000 dataset demonstrate that CoT-SelfEvolve significantly outperforms existing models in solving complex problems. The framework shows substantial improvements in both initial code generation and subsequent iterations, with the model's accuracy increasing significantly with each additional iteration. This highlights the effectiveness of using chain-of-thought prompting to address complexities revealed by program executor traceback error messages. We also discuss how CoT-SelfEvolve can be integrated into continuous software engineering environments, providing a practical solution for improving LLM-based code generation.
Read more8/29/2024