An Empirical Study on Self-correcting Large Language Models for Data Science Code Generation

0
Sign in to get full access
Overview
- Examines the ability of large language models (LLMs) to self-correct and generate high-quality code for data science tasks
- Explores the use of chain-of-thought prompting and external knowledge integration to improve code generation and debugging
- Evaluates the performance of LLMs in a continuous integration and deployment setting
Plain English Explanation
This research paper investigates how well large language models (LLMs) can generate data science code and then self-correct any errors in that code. LLMs are AI systems that have been trained on vast amounts of text data, allowing them to understand and generate human-like language. The researchers wanted to see if these LLMs could apply that language understanding to the task of writing useful computer code.
The key approach the researchers used was chain-of-thought prompting. This means they asked the LLMs to not just generate code, but to also explain their reasoning step-by-step. This extra information helps the LLMs better understand the intent behind the code and identify any potential issues. The researchers also had the LLMs integrate external knowledge from online sources to further improve their code generation and debugging abilities.
The researchers evaluated the LLMs' performance in a simulated continuous integration and deployment setting, where the code needs to be automatically tested and deployed on an ongoing basis. This allowed them to see how well the LLMs could independently generate, test, and refine code without human intervention.
Technical Explanation
The researchers conducted a series of experiments to evaluate the ability of LLMs to self-correct their code generation for data science tasks. They used a chain-of-thought prompting approach, where the LLMs were asked to not only generate code, but also provide step-by-step explanations of their reasoning. This additional information allowed the LLMs to better understand the intent behind the code and identify potential issues.
The researchers also explored the use of external knowledge integration, where the LLMs could access online resources to supplement their understanding and improve their code generation. This was done to simulate a real-world continuous integration and deployment setting, where the LLMs would need to independently generate, test, and refine code without direct human oversight.
The experiments involved evaluating the LLMs' performance on a range of data science tasks, including statistical analysis, machine learning model development, and data visualization. The researchers measured the quality of the generated code, the accuracy of the step-by-step explanations, and the LLMs' ability to self-correct any errors.
Critical Analysis
The research paper presents a compelling exploration of the potential for LLMs to autonomously generate and maintain high-quality code for data science tasks. The use of chain-of-thought prompting and external knowledge integration appears to be a promising approach for improving the self-correction capabilities of these models.
However, the paper does not fully address the potential limitations and challenges of this approach. For example, the researchers do not discuss the scalability of their approach, or how it might perform on more complex or domain-specific coding tasks. Additionally, the paper does not explore the potential security and reliability concerns that could arise from having LLMs autonomously generating and deploying code in a continuous integration and deployment setting.
Further research would be needed to fully understand the broader implications and real-world applicability of this approach. Nonetheless, the findings presented in this paper suggest that the self-correction capabilities of LLMs could be a valuable tool for improving the efficiency and reliability of software development workflows, particularly in data-intensive fields.
Conclusion
This research paper provides an empirical evaluation of the ability of large language models (LLMs) to self-correct their code generation for data science tasks. The key findings suggest that the use of chain-of-thought prompting and external knowledge integration can significantly improve the LLMs' performance in generating high-quality, self-correcting code.
The researchers' experiments in a simulated continuous integration and deployment setting highlight the potential for LLMs to autonomously generate, test, and refine code without direct human oversight. This could have important implications for improving the efficiency and reliability of software development workflows, particularly in data-intensive fields.
While the paper does not fully address the potential limitations and challenges of this approach, the results presented are nonetheless promising and suggest that further research in this area could lead to valuable advancements in the field of automated software development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Empirical Study on Self-correcting Large Language Models for Data Science Code Generation
Thai Tang Quoc, Duc Ha Minh, Tho Quan Thanh, Anh Nguyen-Duc
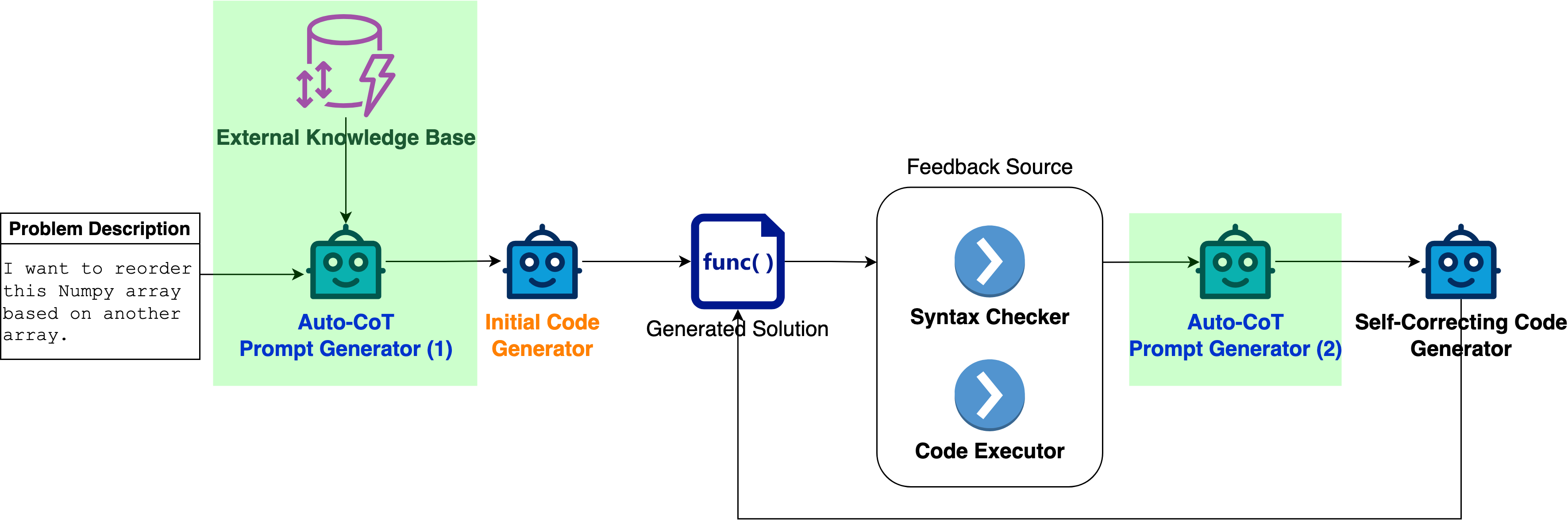
Large Language Models (LLMs) have recently advanced many applications on software engineering tasks, particularly the potential for code generation. Among contemporary challenges, code generated by LLMs often suffers from inaccuracies and hallucinations, requiring external inputs to correct. One recent strategy to fix these issues is to refine the code generated from LLMs using the input from the model itself (self-augmented). In this work, we proposed a novel method, namely CoT-SelfEvolve. CoT-SelfEvolve iteratively and automatically refines code through a self-correcting process, guided by a chain of thought constructed from real-world programming problem feedback. Focusing on data science code, including Python libraries such as NumPy and Pandas, our evaluations on the DS-1000 dataset demonstrate that CoT-SelfEvolve significantly outperforms existing models in solving complex problems. The framework shows substantial improvements in both initial code generation and subsequent iterations, with the model's accuracy increasing significantly with each additional iteration. This highlights the effectiveness of using chain-of-thought prompting to address complexities revealed by program executor traceback error messages. We also discuss how CoT-SelfEvolve can be integrated into continuous software engineering environments, providing a practical solution for improving LLM-based code generation.
Read more8/29/2024
0
A Survey on Self-Evolution of Large Language Models
Zhengwei Tao, Ting-En Lin, Xiancai Chen, Hangyu Li, Yuchuan Wu, Yongbin Li, Zhi Jin, Fei Huang, Dacheng Tao, Jingren Zhou
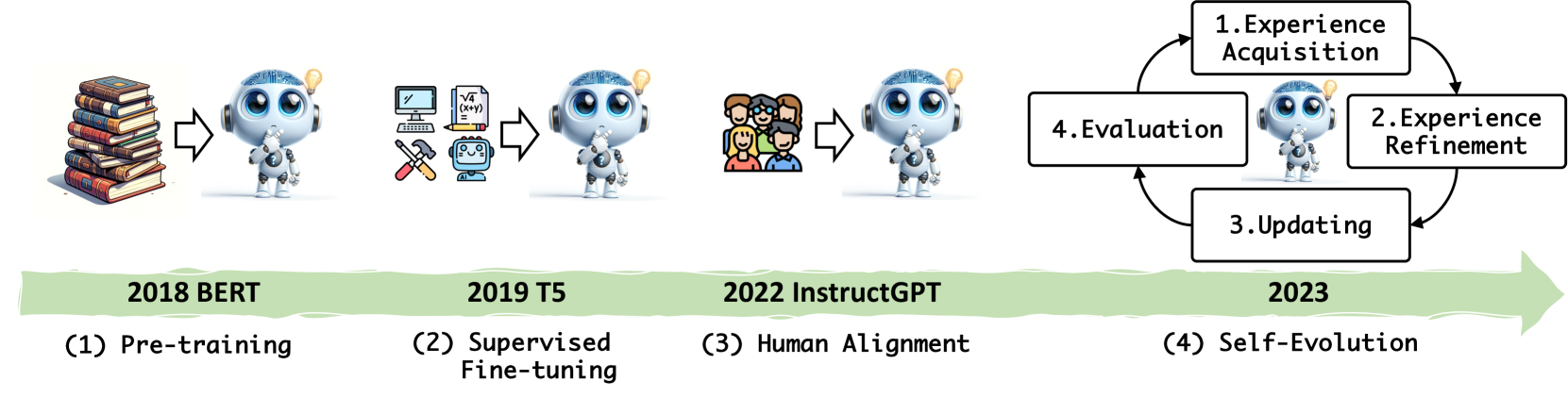
Large language models (LLMs) have significantly advanced in various fields and intelligent agent applications. However, current LLMs that learn from human or external model supervision are costly and may face performance ceilings as task complexity and diversity increase. To address this issue, self-evolution approaches that enable LLM to autonomously acquire, refine, and learn from experiences generated by the model itself are rapidly growing. This new training paradigm inspired by the human experiential learning process offers the potential to scale LLMs towards superintelligence. In this work, we present a comprehensive survey of self-evolution approaches in LLMs. We first propose a conceptual framework for self-evolution and outline the evolving process as iterative cycles composed of four phases: experience acquisition, experience refinement, updating, and evaluation. Second, we categorize the evolution objectives of LLMs and LLM-based agents; then, we summarize the literature and provide taxonomy and insights for each module. Lastly, we pinpoint existing challenges and propose future directions to improve self-evolution frameworks, equipping researchers with critical insights to fast-track the development of self-evolving LLMs. Our corresponding GitHub repository is available at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/Awesome-Self-Evolution-of-LLM
Read more6/4/2024
💬
0
Learning to Check: Unleashing Potentials for Self-Correction in Large Language Models
Che Zhang, Zhenyang Xiao, Chengcheng Han, Yixin Lian, Yuejian Fang
Self-correction has achieved impressive results in enhancing the style and security of the generated output from large language models (LLMs). However, recent studies suggest that self-correction might be limited or even counterproductive in reasoning tasks due to LLMs' difficulties in identifying logical mistakes. In this paper, we aim to enhance the self-checking capabilities of LLMs by constructing training data for checking tasks. Specifically, we apply the Chain of Thought (CoT) methodology to self-checking tasks, utilizing fine-grained step-level analyses and explanations to assess the correctness of reasoning paths. We propose a specialized checking format called Step CoT Check. Following this format, we construct a checking-correction dataset that includes detailed step-by-step analysis and checking. Then we fine-tune LLMs to enhance their error detection and correction abilities. Our experiments demonstrate that fine-tuning with the Step CoT Check format significantly improves the self-checking and self-correction abilities of LLMs across multiple benchmarks. This approach outperforms other formats, especially in locating the incorrect position, with greater benefits observed in larger models. For reproducibility, all the datasets and code are provided in https://github.com/bammt/Learn-to-check.
Read more6/18/2024

0
SIaM: Self-Improving Code-Assisted Mathematical Reasoning of Large Language Models
Dian Yu, Baolin Peng, Ye Tian, Linfeng Song, Haitao Mi, Dong Yu
There is a growing trend of teaching large language models (LLMs) to solve mathematical problems through coding. Existing studies primarily focus on prompting powerful, closed-source models to generate seed training data followed by in-domain data augmentation, equipping LLMs with considerable capabilities for code-aided mathematical reasoning. However, continually training these models on augmented data derived from a few datasets such as GSM8K may impair their generalization abilities and restrict their effectiveness to a narrow range of question types. Conversely, the potential of improving such LLMs by leveraging large-scale, expert-written, diverse math question-answer pairs remains unexplored. To utilize these resources and tackle unique challenges such as code response assessment, we propose a novel paradigm that uses a code-based critic model to guide steps including question-code data construction, quality control, and complementary evaluation. We also explore different alignment algorithms with self-generated instruction/preference data to foster continuous improvement. Experiments across both in-domain (up to +5.7%) and out-of-domain (+4.4%) benchmarks in English and Chinese demonstrate the effectiveness of the proposed paradigm.
Read more8/29/2024