Cohort Squeeze: Beyond a Single Communication Round per Cohort in Cross-Device Federated Learning

0

Sign in to get full access
Overview
- This paper introduces a new approach called "Cohort Squeeze" to improve the communication efficiency in cross-device federated learning, going beyond the typical single communication round per cohort.
- Federated learning is a machine learning technique where a shared model is trained across multiple devices without directly sharing the data, addressing privacy concerns.
- Cross-device federated learning involves training on data from a large number of devices, which can be challenging due to limited communication bandwidth and device availability.
- The Cohort Squeeze method aims to reduce the number of communication rounds required, while still maintaining model performance.
Plain English Explanation
The paper describes a way to make federated learning more efficient, especially when working with a large number of devices, as is the case in cross-device federated learning.
Federated learning is a technique where multiple devices, like smartphones or laptops, work together to train a shared machine learning model without directly sharing the data on each device. This is useful for protecting privacy, as the sensitive data never leaves the device.
The challenge is that cross-device federated learning, where you have a huge number of devices participating, can be limited by the available communication bandwidth and device availability. The Cohort Squeeze method proposed in this paper aims to reduce the number of times the devices need to communicate with the central server, while still maintaining the performance of the trained model.
The key idea is to have the devices run multiple training rounds within each "cohort" (group of devices) before sending their updates to the server. This reduces the overall communication required, making the federated learning process more efficient, especially for scenarios with many participating devices and limited connectivity.
Technical Explanation
The Cohort Squeeze method builds upon previous work on communication-efficient model aggregation and dimension-free communication in federated learning.
The key technical contributions of the Cohort Squeeze approach include:
- Cohort Formation: Devices are divided into smaller "cohorts" or groups, rather than all devices communicating directly with the server in each round.
- Intra-Cohort Training: Devices within each cohort perform multiple local training rounds before sending their updates to the server, rather than a single round.
- Cohort-Level Aggregation: The server aggregates the updates from each cohort, rather than individual devices, reducing the overall communication required.
- Cohort Scheduling: The server dynamically schedules the cohorts to participate in the training process, based on factors like device availability and resource constraints.
Through these innovations, the Cohort Squeeze method is able to achieve a significant reduction in the number of communication rounds required, while still maintaining model performance comparable to traditional federated learning approaches. This is particularly beneficial for large-scale pre-training scenarios where communication efficiency is critical.
Critical Analysis
The paper provides a solid technical foundation for the Cohort Squeeze approach and presents compelling experimental results demonstrating its advantages over standard federated learning. However, a few potential limitations and areas for further research are worth considering:
-
Heterogeneous Device Capabilities: The paper assumes homogeneous device capabilities within each cohort, but in real-world scenarios, device performance can vary significantly. Accounting for this heterogeneity may require more sophisticated cohort formation and scheduling strategies.
-
Convergence Guarantees: While the experiments show that Cohort Squeeze can match the performance of traditional federated learning, the paper does not provide theoretical guarantees on the convergence rate or model quality compared to the centralized training baseline.
-
Robustness to Device Dropout: The paper does not address how the Cohort Squeeze method would handle devices dropping out or becoming unavailable during the training process, which can be a common occurrence in cross-device federated learning.
-
Privacy Considerations: The paper focuses primarily on communication efficiency, but the implications of the Cohort Squeeze approach on the privacy guarantees of federated learning should be further explored.
Overall, the Cohort Squeeze method represents a promising step forward in improving the scalability and practicality of cross-device federated learning, but additional research is needed to address these potential limitations and ensure the approach is robust and secure in real-world deployments.
Conclusion
The Cohort Squeeze method introduced in this paper offers a novel way to enhance the communication efficiency of cross-device federated learning, which is crucial for enabling large-scale machine learning applications while preserving user privacy. By allowing devices to perform multiple local training rounds within cohorts before communicating with the central server, the approach significantly reduces the overall communication burden without sacrificing model performance.
This work builds on and extends previous research in the area of communication-efficient federated learning, taking a significant step towards making cross-device federated learning a more practical and scalable solution for a wide range of applications. As the field of federated learning continues to evolve, the insights and techniques presented in this paper will likely serve as an important foundation for future advancements in this important area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cohort Squeeze: Beyond a Single Communication Round per Cohort in Cross-Device Federated Learning
Kai Yi, Timur Kharisov, Igor Sokolov, Peter Richt'arik
Virtually all federated learning (FL) methods, including FedAvg, operate in the following manner: i) an orchestrating server sends the current model parameters to a cohort of clients selected via certain rule, ii) these clients then independently perform a local training procedure (e.g., via SGD or Adam) using their own training data, and iii) the resulting models are shipped to the server for aggregation. This process is repeated until a model of suitable quality is found. A notable feature of these methods is that each cohort is involved in a single communication round with the server only. In this work we challenge this algorithmic design primitive and investigate whether it is possible to ``squeeze more juice out of each cohort than what is possible in a single communication round. Surprisingly, we find that this is indeed the case, and our approach leads to up to 74% reduction in the total communication cost needed to train a FL model in the cross-device setting. Our method is based on a novel variant of the stochastic proximal point method (SPPM-AS) which supports a large collection of client sampling procedures some of which lead to further gains when compared to classical client selection approaches.
Read more6/4/2024
0
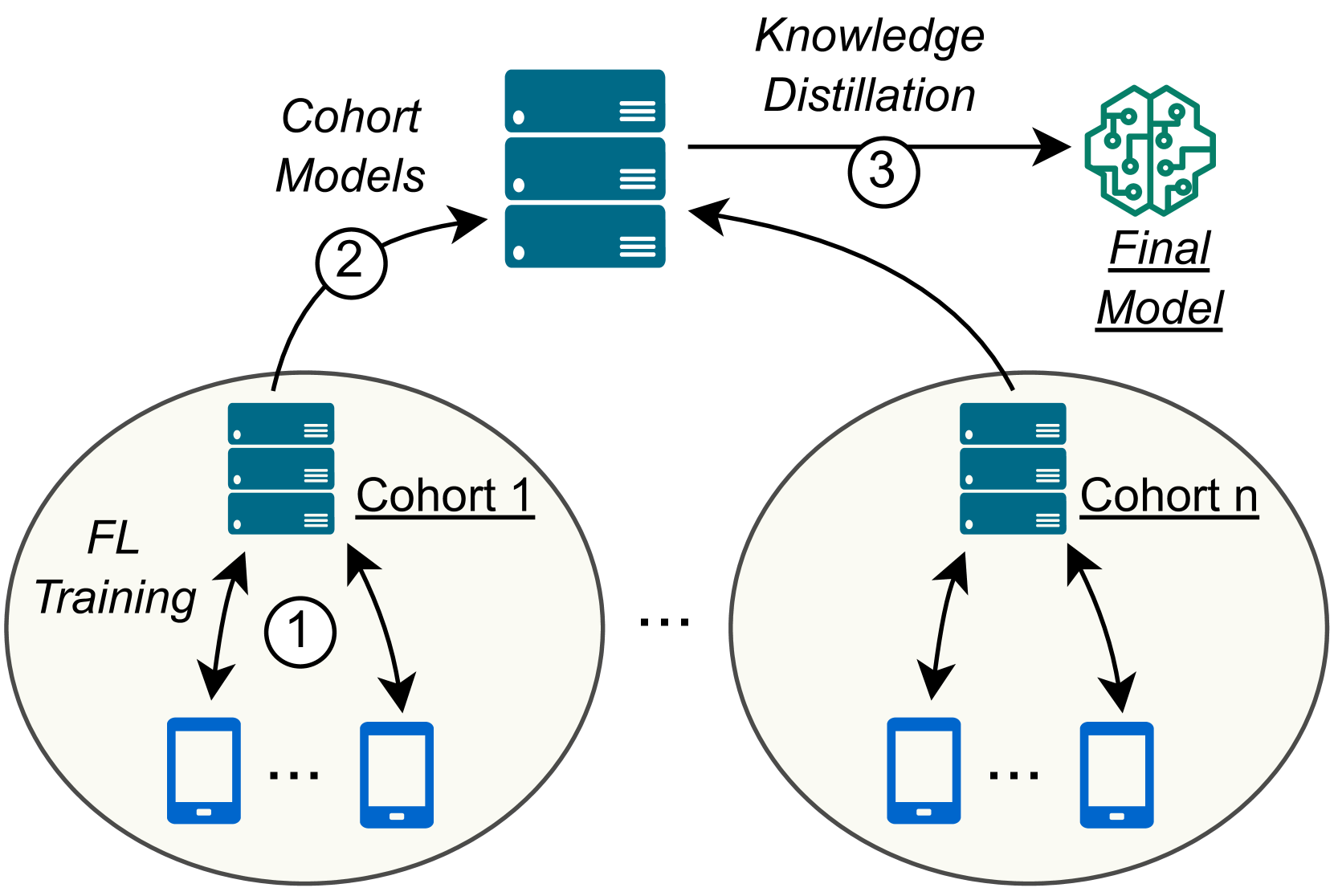
Harnessing Increased Client Participation with Cohort-Parallel Federated Learning
Akash Dhasade, Anne-Marie Kermarrec, Tuan-Anh Nguyen, Rafael Pires, Martijn de Vos
Federated Learning (FL) is a machine learning approach where nodes collaboratively train a global model. As more nodes participate in a round of FL, the effectiveness of individual model updates by nodes also diminishes. In this study, we increase the effectiveness of client updates by dividing the network into smaller partitions, or cohorts. We introduce Cohort-Parallel Federated Learning (CPFL): a novel learning approach where each cohort independently trains a global model using FL, until convergence, and the produced models by each cohort are then unified using one-shot Knowledge Distillation (KD) and a cross-domain, unlabeled dataset. The insight behind CPFL is that smaller, isolated networks converge quicker than in a one-network setting where all nodes participate. Through exhaustive experiments involving realistic traces and non-IID data distributions on the CIFAR-10 and FEMNIST image classification tasks, we investigate the balance between the number of cohorts, model accuracy, training time, and compute and communication resources. Compared to traditional FL, CPFL with four cohorts, non-IID data distribution, and CIFAR-10 yields a 1.9$times$ reduction in train time and a 1.3$times$ reduction in resource usage, with a minimal drop in test accuracy.
Read more5/27/2024
💬
0
CELLM: An Efficient Communication in Large Language Models Training for Federated Learning
Raja Vavekanand, Kira Sam
Federated Learning (FL) is a recent model training paradigm in which client devices collaboratively train a model without ever aggregating their data. Crucially, this scheme offers users potential privacy and security benefits by only ever communicating updates to the model weights to a central server as opposed to traditional machine learning (ML) training which directly communicates and aggregates data. However, FL training suffers from statistical heterogeneity as clients may have differing local data distributions. Large language models (LLMs) offer a potential solution to this issue of heterogeneity given that they have consistently been shown to be able to learn on vast amounts of noisy data. While LLMs are a promising development for resolving the consistent issue of non-I.I.D. Clients in federated settings exacerbate two other bottlenecks in FL: limited local computing and expensive communication. This thesis aims to develop efficient training methods for LLMs in FL. To this end, we employ two critical techniques in enabling efficient training. First, we use low-rank adaptation (LoRA) to reduce the computational load of local model training. Second, we communicate sparse updates throughout training to significantly cut down on communication costs. Taken together, our method reduces communication costs by up to 10x over vanilla LoRA and up to 5x over more complex sparse LoRA baselines while achieving greater utility. We emphasize the importance of carefully applying sparsity and picking effective rank and sparsity configurations for federated LLM training.
Read more8/21/2024

0
DynamicFL: Federated Learning with Dynamic Communication Resource Allocation
Qi Le, Enmao Diao, Xinran Wang, Vahid Tarokh, Jie Ding, Ali Anwar
Federated Learning (FL) is a collaborative machine learning framework that allows multiple users to train models utilizing their local data in a distributed manner. However, considerable statistical heterogeneity in local data across devices often leads to suboptimal model performance compared with independently and identically distributed (IID) data scenarios. In this paper, we introduce DynamicFL, a new FL framework that investigates the trade-offs between global model performance and communication costs for two widely adopted FL methods: Federated Stochastic Gradient Descent (FedSGD) and Federated Averaging (FedAvg). Our approach allocates diverse communication resources to clients based on their data statistical heterogeneity, considering communication resource constraints, and attains substantial performance enhancements compared to uniform communication resource allocation. Notably, our method bridges the gap between FedSGD and FedAvg, providing a flexible framework leveraging communication heterogeneity to address statistical heterogeneity in FL. Through extensive experiments, we demonstrate that DynamicFL surpasses current state-of-the-art methods with up to a 10% increase in model accuracy, demonstrating its adaptability and effectiveness in tackling data statistical heterogeneity challenges.
Read more9/10/2024