COIN: Counterfactual inpainting for weakly supervised semantic segmentation for medical images

0

Sign in to get full access
Overview
- This paper introduces COIN, a method for weakly supervised semantic segmentation of medical images using counterfactual inpainting.
- The technique leverages generative adversarial networks (GANs) to generate counterfactual examples, which are then used to train a segmentation model in a weakly supervised manner.
- The authors demonstrate the effectiveness of COIN on the task of kidney tumor segmentation in CT scans, achieving strong performance with only limited ground truth annotations.
Plain English Explanation
The paper presents a new approach called COIN (Counterfactual Inpainting) for segmenting medical images, such as CT scans of the kidney, without needing a lot of detailed training data. Typically, training a computer vision model to accurately identify different structures in a medical image requires a large dataset of images where the relevant areas have been carefully labeled by experts. This can be time-consuming and expensive to obtain.
COIN gets around this by using a technique called counterfactual reasoning. The idea is to use a generative adversarial network (GAN) to create "counterfactual" versions of the input images - for example, an image that is identical except for having a tumor added or removed. These counterfactual images can then be used to train the segmentation model, along with just a few fully annotated examples.
The authors show that this COIN approach works well for the task of segmenting kidney tumors in CT scans, achieving strong performance even when only a small amount of fully labeled training data is available. This could be very useful in medical imaging, where obtaining detailed ground truth annotations can be challenging.
Technical Explanation
The key technical aspects of the COIN method are:
-
Weakly Supervised Setup: The authors assume access to a dataset of medical images (e.g., CT scans) with only partial annotations - i.e., some images have detailed segmentation masks, while others have no annotations at all.
-
Counterfactual Inpainting: A GAN-based model is trained to generate counterfactual versions of the input images. For example, it can add or remove a kidney tumor from an image, while keeping the rest of the image unchanged. These counterfactual images are then used as additional training data for the segmentation model.
-
Segmentation Model Architecture: The segmentation model has a standard encoder-decoder architecture, similar to a U-Net. It takes the original and counterfactual images as input and outputs segmentation masks for the target structures (e.g., kidney, tumor).
-
Training Procedure: The segmentation model is trained in a weakly supervised manner, using a combination of fully annotated images and the counterfactual examples generated by the GAN. This allows the model to learn robust segmentation capabilities with limited ground truth data.
The authors evaluate COIN on the task of kidney tumor segmentation in CT scans, and show that it outperforms other weakly supervised approaches, especially when the amount of fully annotated training data is limited. This demonstrates the power of counterfactual reasoning for leveraging partial supervision in medical image analysis.
Critical Analysis
The COIN method provides a compelling approach to addressing the challenge of limited annotation data in medical image segmentation. By generating counterfactual examples, the technique can effectively expand the training dataset and improve the model's generalization capabilities.
However, a potential limitation of the method is that the quality and diversity of the counterfactual examples generated by the GAN can have a significant impact on the final segmentation performance. If the GAN struggles to produce realistic and representative counterfactual images, the segmentation model may not learn the desired behavior.
Additionally, the authors do not provide a detailed analysis of the types of errors or failure modes of the COIN approach. It would be useful to understand the scenarios in which the method might struggle, such as handling rare or atypical medical conditions.
Future work could explore ways to further improve the robustness and reliability of the counterfactual generation process, potentially by incorporating additional constraints or using more advanced GAN architectures. Investigating the application of COIN to other medical imaging tasks beyond kidney tumor segmentation would also be an interesting direction for further research.
Conclusion
The COIN method presented in this paper offers a promising approach for tackling the challenge of limited annotation data in medical image segmentation. By leveraging counterfactual reasoning and generative adversarial networks, the technique can effectively expand the training dataset and achieve strong performance even with partial supervision.
The authors' demonstration of COIN's effectiveness on the task of kidney tumor segmentation in CT scans suggests that the method could have broad applicability in the medical imaging domain, where obtaining detailed ground truth annotations can be both time-consuming and expensive. As the field of machine learning continues to advance, techniques like COIN that can make effective use of partial supervision will become increasingly valuable for developing robust and practical solutions for real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
COIN: Counterfactual inpainting for weakly supervised semantic segmentation for medical images
Dmytro Shvetsov, Joonas Ariva, Marharyta Domnich, Raul Vicente, Dmytro Fishman
Deep learning is dramatically transforming the field of medical imaging and radiology, enabling the identification of pathologies in medical images, including computed tomography (CT) and X-ray scans. However, the performance of deep learning models, particularly in segmentation tasks, is often limited by the need for extensive annotated datasets. To address this challenge, the capabilities of weakly supervised semantic segmentation are explored through the lens of Explainable AI and the generation of counterfactual explanations. The scope of this research is development of a novel counterfactual inpainting approach (COIN) that flips the predicted classification label from abnormal to normal by using a generative model. For instance, if the classifier deems an input medical image X as abnormal, indicating the presence of a pathology, the generative model aims to inpaint the abnormal region, thus reversing the classifier's original prediction label. The approach enables us to produce precise segmentations for pathologies without depending on pre-existing segmentation masks. Crucially, image-level labels are utilized, which are substantially easier to acquire than creating detailed segmentation masks. The effectiveness of the method is demonstrated by segmenting synthetic targets and actual kidney tumors from CT images acquired from Tartu University Hospital in Estonia. The findings indicate that COIN greatly surpasses established attribution methods, such as RISE, ScoreCAM, and LayerCAM, as well as an alternative counterfactual explanation method introduced by Singla et al. This evidence suggests that COIN is a promising approach for semantic segmentation of tumors in CT images, and presents a step forward in making deep learning applications more accessible and effective in healthcare, where annotated data is scarce.
Read more7/26/2024
0
Reinforcing Pre-trained Models Using Counterfactual Images
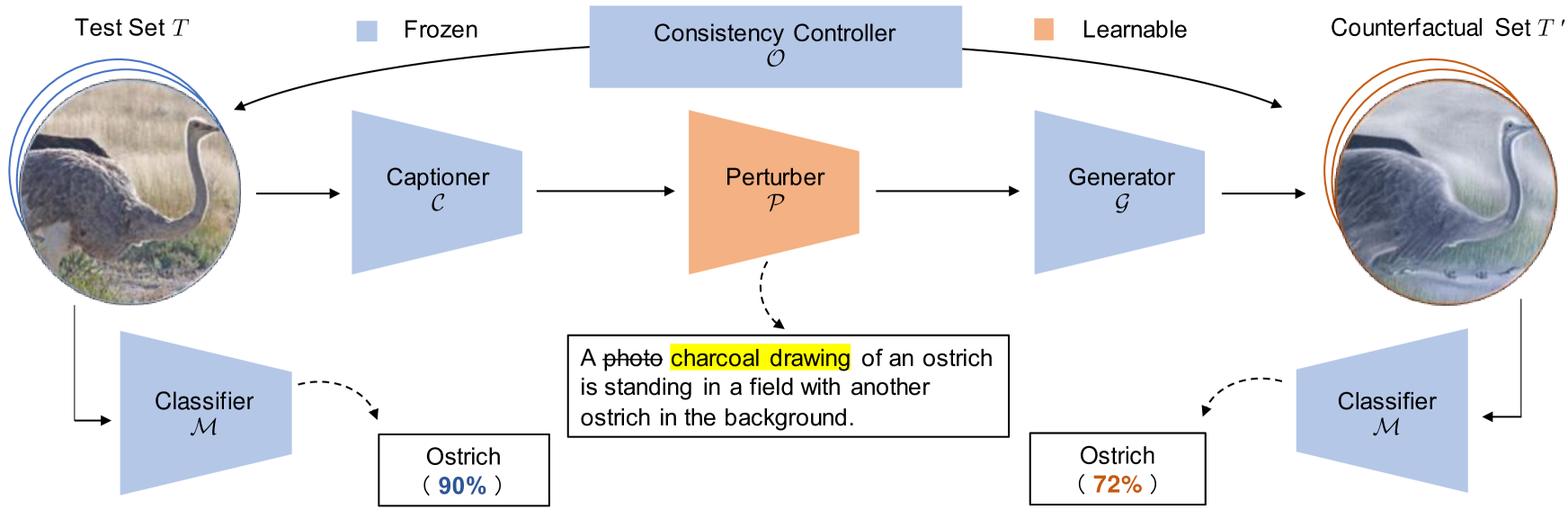
Xiang Li, Ren Togo, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama
This paper proposes a novel framework to reinforce classification models using language-guided generated counterfactual images. Deep learning classification models are often trained using datasets that mirror real-world scenarios. In this training process, because learning is based solely on correlations with labels, there is a risk that models may learn spurious relationships, such as an overreliance on features not central to the subject, like background elements in images. However, due to the black-box nature of the decision-making process in deep learning models, identifying and addressing these vulnerabilities has been particularly challenging. We introduce a novel framework for reinforcing the classification models, which consists of a two-stage process. First, we identify model weaknesses by testing the model using the counterfactual image dataset, which is generated by perturbed image captions. Subsequently, we employ the counterfactual images as an augmented dataset to fine-tune and reinforce the classification model. Through extensive experiments on several classification models across various datasets, we revealed that fine-tuning with a small set of counterfactual images effectively strengthens the model.
Read more6/21/2024
0
DiffExplainer: Unveiling Black Box Models Via Counterfactual Generation
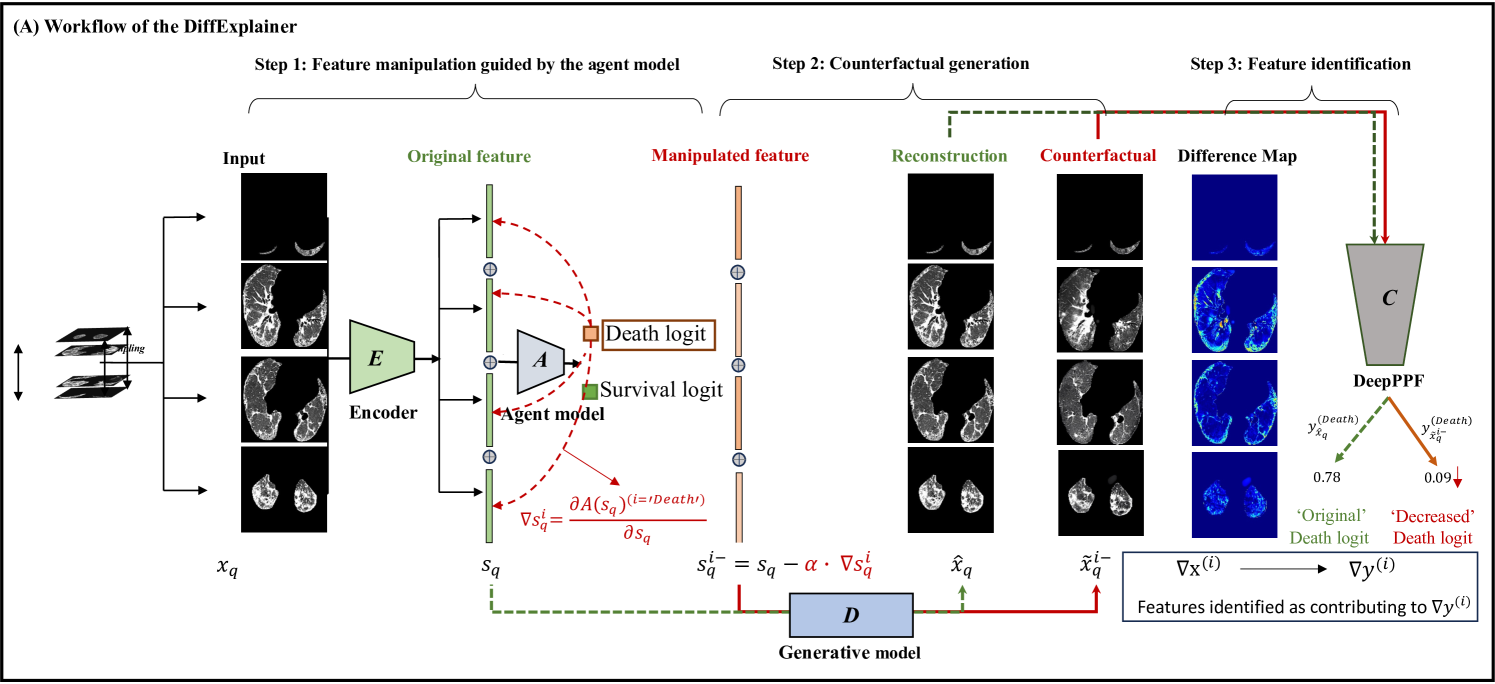
Yingying Fang, Shuang Wu, Zihao Jin, Caiwen Xu, Shiyi Wang, Simon Walsh, Guang Yang
In the field of medical imaging, particularly in tasks related to early disease detection and prognosis, understanding the reasoning behind AI model predictions is imperative for assessing their reliability. Conventional explanation methods encounter challenges in identifying decisive features in medical image classifications, especially when discriminative features are subtle or not immediately evident. To address this limitation, we propose an agent model capable of generating counterfactual images that prompt different decisions when plugged into a black box model. By employing this agent model, we can uncover influential image patterns that impact the black model's final predictions. Through our methodology, we efficiently identify features that influence decisions of the deep black box. We validated our approach in the rigorous domain of medical prognosis tasks, showcasing its efficacy and potential to enhance the reliability of deep learning models in medical image classification compared to existing interpretation methods. The code will be publicly available at https://github.com/ayanglab/DiffExplainer.
Read more6/28/2024
0
Robust image representations with counterfactual contrastive learning
M'elanie Roschewitz, Fabio De Sousa Ribeiro, Tian Xia, Galvin Khara, Ben Glocker
Contrastive pretraining can substantially increase model generalisation and downstream performance. However, the quality of the learned representations is highly dependent on the data augmentation strategy applied to generate positive pairs. Positive contrastive pairs should preserve semantic meaning while discarding unwanted variations related to the data acquisition domain. Traditional contrastive pipelines attempt to simulate domain shifts through pre-defined generic image transformations. However, these do not always mimic realistic and relevant domain variations for medical imaging such as scanner differences. To tackle this issue, we herein introduce counterfactual contrastive learning, a novel framework leveraging recent advances in causal image synthesis to create contrastive positive pairs that faithfully capture relevant domain variations. Our method, evaluated across five datasets encompassing both chest radiography and mammography data, for two established contrastive objectives (SimCLR and DINO-v2), outperforms standard contrastive learning in terms of robustness to acquisition shift. Notably, counterfactual contrastive learning achieves superior downstream performance on both in-distribution and on external datasets, especially for images acquired with scanners under-represented in the training set. Further experiments show that the proposed framework extends beyond acquisition shifts, with models trained with counterfactual contrastive learning substantially improving subgroup performance across biological sex.
Read more9/17/2024