CoIR: A Comprehensive Benchmark for Code Information Retrieval Models

0

Sign in to get full access
Overview
- This paper introduces CoIR, a comprehensive benchmark for evaluating code information retrieval (IR) models.
- The benchmark covers a diverse range of code-related tasks, including code search, code summarization, and code-to-text generation.
- The authors argue that existing benchmarks are limited in scope and fail to capture the full complexity of real-world code IR challenges.
Plain English Explanation
The paper presents a new benchmark called CoIR that is designed to better assess the capabilities of models for retrieving and understanding code-related information. Existing benchmarks tend to focus on specific tasks, like searching for relevant code snippets or generating summaries of code. However, in the real world, developers often need to perform a variety of code-related activities, such as finding relevant code examples, understanding the purpose of a piece of code, or generating natural language descriptions of code functionality.
The CoIR benchmark [https://aimodels.fyi/papers/arxiv/cosqa-enhancing-code-search-dataset-matching-code] aims to capture this broader range of code-related tasks. It includes datasets and evaluation metrics for tasks like code search, code summarization, and code-to-text generation. By providing a more comprehensive set of benchmarks, the authors hope to drive the development of more versatile and robust code IR models that can better assist developers in their day-to-day work.
Technical Explanation
The CoIR benchmark [https://aimodels.fyi/papers/arxiv/cocktail-comprehensive-information-retrieval-benchmark-llm-generated] consists of several datasets and evaluation tasks that cover different aspects of code information retrieval. These include:
- Code search: Retrieving relevant code snippets given a natural language query
- Code summarization: Generating natural language descriptions of code functionality
- Code-to-text generation: Translating code into natural language explanations
The authors argue that these tasks, when considered together, better reflect the real-world challenges faced by developers in understanding and working with code. They have curated datasets from various sources, including open-source repositories and programming Q&A forums, to create a diverse and representative benchmark.
The paper also discusses the evaluation metrics used for each task, such as semantic similarity, code correctness, and human evaluation. The authors emphasize the importance of using a comprehensive set of metrics to capture the multifaceted nature of code IR tasks.
Critical Analysis
The CoIR benchmark [https://aimodels.fyi/papers/arxiv/birco-benchmark-information-retrieval-tasks-complex-objectives] represents a significant step forward in the field of code information retrieval. By providing a more holistic assessment of model capabilities, the benchmark has the potential to drive the development of more versatile and effective code IR systems.
However, the authors acknowledge that the benchmark is not without its limitations. The datasets and tasks included may not fully capture the diversity of real-world code-related challenges, and the evaluation metrics may not always align with the specific needs of developers. Additionally, the authors note that the benchmark is primarily focused on English-language code, which may limit its applicability to other programming languages.
Further research is needed to explore the generalization of the CoIR benchmark to other programming languages and to investigate the trade-offs between the different tasks and their respective evaluation metrics. The authors also suggest that incorporating more contextual information, such as code provenance and developer expertise, could enhance the benchmark's ability to capture the nuances of code-related tasks.
Conclusion
The CoIR benchmark introduced in this paper represents a significant contribution to the field of code information retrieval. By providing a comprehensive set of datasets and tasks, the benchmark aims to drive the development of more versatile and effective code IR models that can better support developers in their day-to-day work.
The authors' emphasis on capturing the multifaceted nature of code-related tasks, such as code search, summarization, and generation, is a crucial step forward in the field. While the benchmark has limitations, it serves as a valuable tool for researchers and practitioners to evaluate and improve their code IR models, ultimately leading to more efficient and user-friendly tools for code-related tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CoIR: A Comprehensive Benchmark for Code Information Retrieval Models
Xiangyang Li, Kuicai Dong, Yi Quan Lee, Wei Xia, Yichun Yin, Hao Zhang, Yong Liu, Yasheng Wang, Ruiming Tang
Despite the substantial success of Information Retrieval (IR) in various NLP tasks, most IR systems predominantly handle queries and corpora in natural language, neglecting the domain of code retrieval. Code retrieval is critically important yet remains under-explored, with existing methods and benchmarks inadequately representing the diversity of code in various domains and tasks. Addressing this gap, we present textbf{name} (textbf{Co}de textbf{I}nformation textbf{R}etrieval Benchmark), a robust and comprehensive benchmark specifically designed to assess code retrieval capabilities. name comprises textbf{ten} meticulously curated code datasets, spanning textbf{eight} distinctive retrieval tasks across textbf{seven} diverse domains. We first discuss the construction of name and its diverse dataset composition. Further, we evaluate nine widely used retrieval models using name, uncovering significant difficulties in performing code retrieval tasks even with state-of-the-art systems. To facilitate easy adoption and integration within existing research workflows, name has been developed as a user-friendly Python framework, readily installable via pip. It shares same data schema as other popular benchmarks like MTEB and BEIR, enabling seamless cross-benchmark evaluations. Through name, we aim to invigorate research in the code retrieval domain, providing a versatile benchmarking tool that encourages further development and exploration of code retrieval systemsfootnote{url{ https://github.com/CoIR-team/coir}}.
Read more7/4/2024

0
BIRCO: A Benchmark of Information Retrieval Tasks with Complex Objectives
Xiaoyue Wang, Jianyou Wang, Weili Cao, Kaicheng Wang, Ramamohan Paturi, Leon Bergen
We present the Benchmark of Information Retrieval (IR) tasks with Complex Objectives (BIRCO). BIRCO evaluates the ability of IR systems to retrieve documents given multi-faceted user objectives. The benchmark's complexity and compact size make it suitable for evaluating large language model (LLM)-based information retrieval systems. We present a modular framework for investigating factors that may influence LLM performance on retrieval tasks, and identify a simple baseline model which matches or outperforms existing approaches and more complex alternatives. No approach achieves satisfactory performance on all benchmark tasks, suggesting that stronger models and new retrieval protocols are necessary to address complex user needs.
Read more4/5/2024
0
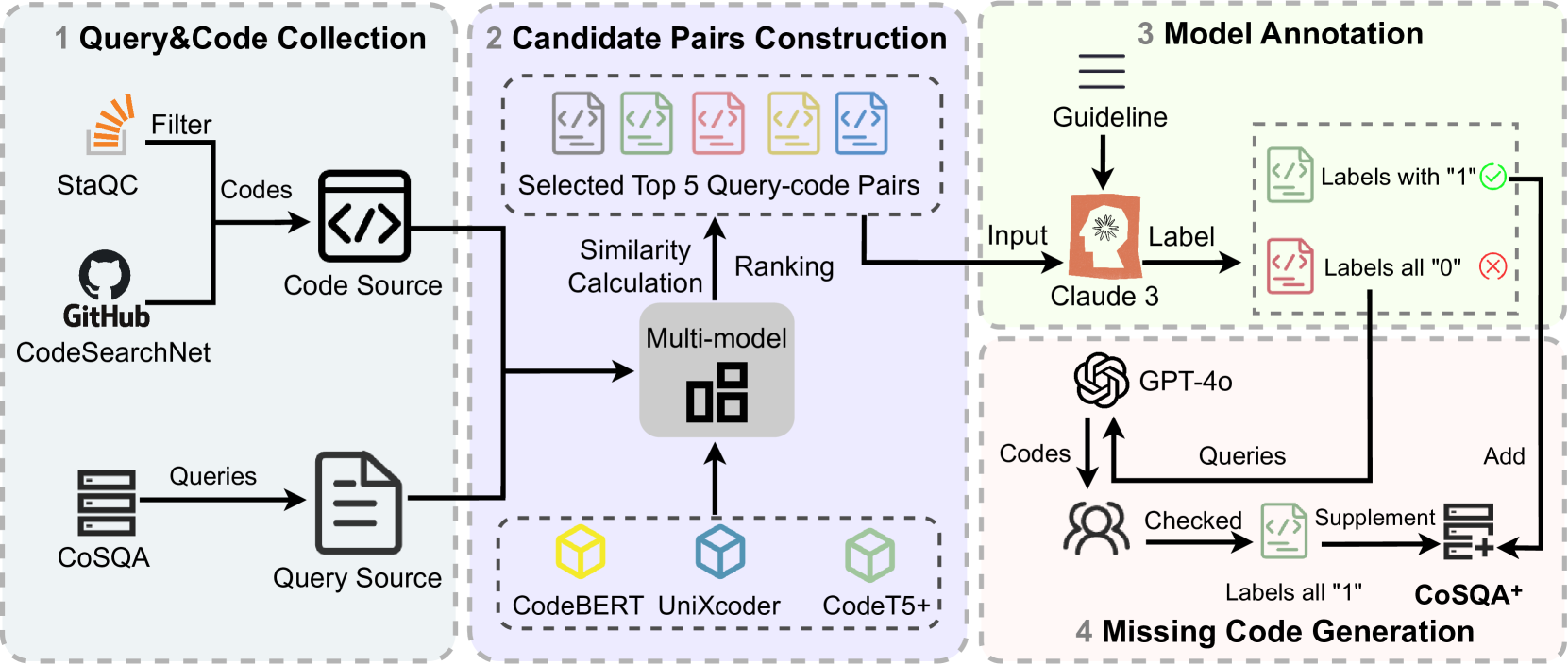
CoSQA+: Enhancing Code Search Dataset with Matching Code
Jing Gong, Yanghui Wu, Linxi Liang, Zibin Zheng, Yanlin Wang
Semantic code search, retrieving code that matches a given natural language query, is an important task to improve productivity in software engineering. Existing code search datasets are problematic: either using unrealistic queries, or with mismatched codes, and typically using one-to-one query-code pairing, which fails to reflect the reality that a query might have multiple valid code matches. This paper introduces CoSQA+, pairing high-quality queries (reused from CoSQA) with multiple suitable codes. We collect code candidates from diverse sources and form candidate pairs by pairing queries with these codes. Utilizing the power of large language models (LLMs), we automate pair annotation, filtering, and code generation for queries without suitable matches. Through extensive experiments, CoSQA+ has demonstrated superior quality over CoSQA. Models trained on CoSQA+ exhibit improved performance. Furthermore, we propose a new metric Mean Multi-choice Reciprocal Rank (MMRR), to assess one-to-N code search performance. We provide the code and data at https://github.com/DeepSoftwareAnalytics/CoSQA_Plus.
Read more8/27/2024
0
CFIR: Fast and Effective Long-Text To Image Retrieval for Large Corpora
Zijun Long, Xuri Ge, Richard Mccreadie, Joemon Jose
Text-to-image retrieval aims to find the relevant images based on a text query, which is important in various use-cases, such as digital libraries, e-commerce, and multimedia databases. Although Multimodal Large Language Models (MLLMs) demonstrate state-of-the-art performance, they exhibit limitations in handling large-scale, diverse, and ambiguous real-world needs of retrieval, due to the computation cost and the injective embeddings they produce. This paper presents a two-stage Coarse-to-Fine Index-shared Retrieval (CFIR) framework, designed for fast and effective large-scale long-text to image retrieval. The first stage, Entity-based Ranking (ER), adapts to long-text query ambiguity by employing a multiple-queries-to-multiple-targets paradigm, facilitating candidate filtering for the next stage. The second stage, Summary-based Re-ranking (SR), refines these rankings using summarized queries. We also propose a specialized Decoupling-BEiT-3 encoder, optimized for handling ambiguous user needs and both stages, which also enhances computational efficiency through vector-based similarity inference. Evaluation on the AToMiC dataset reveals that CFIR surpasses existing MLLMs by up to 11.06% in Recall@1000, while reducing training and retrieval times by 68.75% and 99.79%, respectively. We will release our code to facilitate future research at https://github.com/longkukuhi/CFIR.
Read more4/4/2024