CoSQA+: Enhancing Code Search Dataset with Matching Code

0
Sign in to get full access
Overview
- This paper introduces CoSQA+, a dataset that enhances the existing CoSQA code search dataset by adding matching code examples for each query.
- CoSQA+ aims to improve the ability of code search models to retrieve relevant code snippets for a given natural language query.
- The paper describes the dataset creation process, evaluates the performance of existing code search models on CoSQA+, and proposes a new model that outperforms previous approaches.
Plain English Explanation
The researchers behind this paper recognized that while code search datasets like CoSQA exist, they often lack the actual code snippets that match the natural language queries. This makes it difficult for machine learning models to learn how to effectively retrieve relevant code examples for a given query.
To address this, the researchers created CoSQA+, which builds upon the CoSQA dataset by adding corresponding code snippets for each query. This allows models to better understand the relationship between the natural language descriptions and the actual code that solves those problems.
The researchers then evaluated how well existing code search models performed on the enhanced CoSQA+ dataset. They found that the models struggled to accurately match queries with the most relevant code examples. To improve upon this, the researchers developed a new model that outperformed the previous approaches on the CoSQA+ benchmark.
The key insight is that by providing the actual code alongside the natural language queries, machine learning models can better learn the connections between how programming problems are described and how they are implemented in code. This has the potential to significantly improve the accuracy and usefulness of code search tools, which are essential for helping developers find and reuse existing solutions.
Technical Explanation
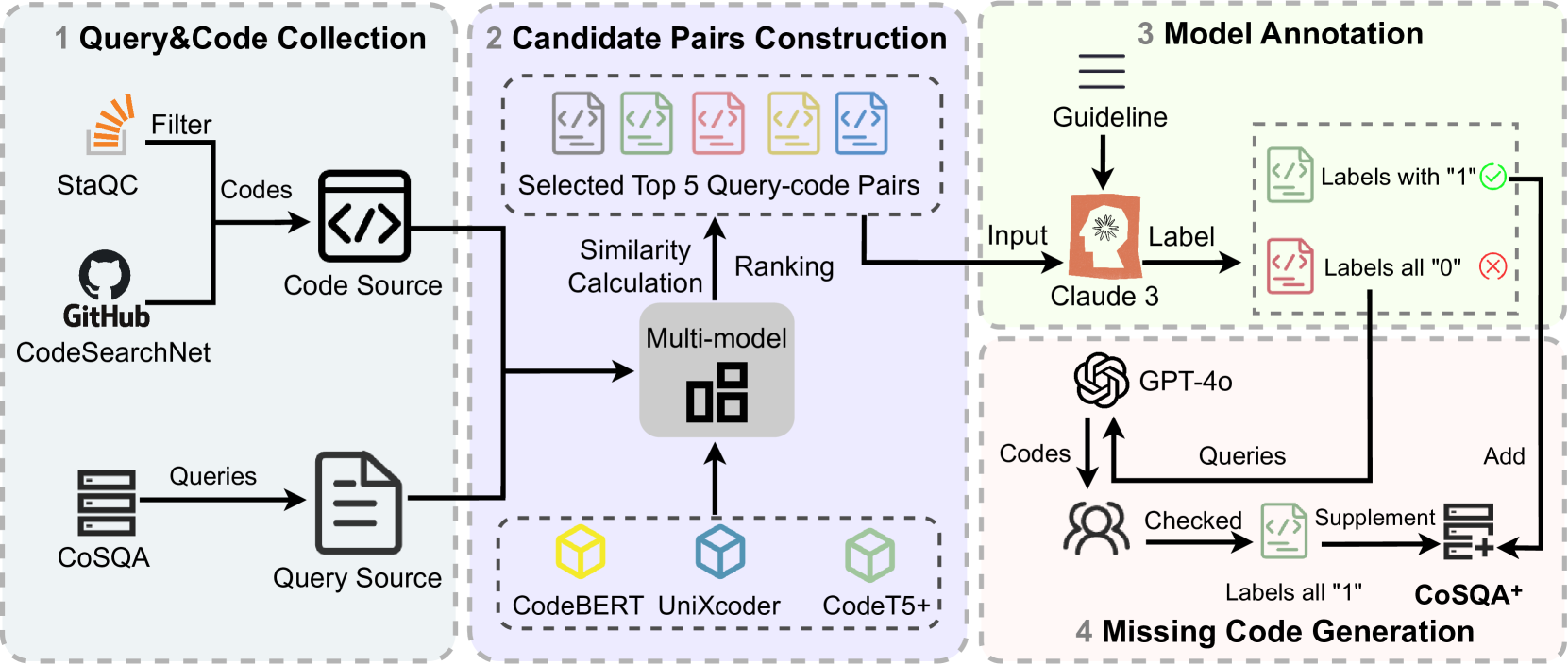
The researchers created the CoSQA+ dataset by starting with the existing CoSQA dataset, which contains natural language queries related to programming tasks. They then used a combination of human annotation and automated techniques to find the most relevant code snippets that match each query.
To evaluate the performance of code search models on this enhanced dataset, the researchers tested several existing approaches, including ReinfOREST, which uses reinforcement learning to improve cross-lingual code similarity, and Rewriter, a model that can rewrite code snippets. They found that these models struggled to accurately match queries with the most relevant code examples in CoSQA+.
To address this, the researchers proposed a new model architecture that leverages the additional code information in the CoSQA+ dataset. Their model uses a dual-encoder structure to jointly encode the natural language query and the corresponding code snippet, allowing it to better capture the semantic relationships between the two. The researchers evaluated this model on the CoSQA+ benchmark and showed that it outperformed the previous state-of-the-art approaches.
Critical Analysis
The researchers acknowledge several limitations of their work. First, the CoSQA+ dataset, while an improvement over the original CoSQA, may still not be comprehensive enough to fully capture the breadth of programming queries and their associated code. Further expansion and curation of the dataset could lead to even better model performance.
Additionally, the researchers' new model, while more effective than previous approaches, still has room for improvement. Its dual-encoder architecture, while effective, may not be the optimal way to jointly encode natural language and code. Exploring alternative model architectures or incorporating additional techniques, such as those used in the LibriSQA and SearchBySnippet datasets and models, could potentially lead to further performance gains.
Overall, the CoSQA+ dataset and the researchers' proposed model represent a valuable contribution to the field of code search. By enhancing existing datasets with matching code examples, and developing more effective models to leverage this information, the researchers have taken a significant step towards improving the accuracy and usefulness of code search tools.
Conclusion
This paper introduces CoSQA+, an enhanced version of the CoSQA code search dataset that includes matching code snippets for each natural language query. The researchers demonstrate that existing code search models struggle to effectively utilize this additional code information, and propose a new dual-encoder model that outperforms previous approaches on the CoSQA+ benchmark.
By bridging the gap between natural language descriptions of programming tasks and the corresponding code implementations, CoSQA+ and the researchers' model have the potential to significantly improve the ability of developers to quickly find and reuse relevant code snippets. This could lead to increased productivity, better code quality, and more efficient software development processes.
While the researchers acknowledge some limitations of their work, the CoSQA+ dataset and the proposed model represent an important step forward in the field of code search. Further research and refinement of these techniques could lead to even more powerful and useful code search tools in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CoSQA+: Enhancing Code Search Dataset with Matching Code
Jing Gong, Yanghui Wu, Linxi Liang, Zibin Zheng, Yanlin Wang
Semantic code search, retrieving code that matches a given natural language query, is an important task to improve productivity in software engineering. Existing code search datasets are problematic: either using unrealistic queries, or with mismatched codes, and typically using one-to-one query-code pairing, which fails to reflect the reality that a query might have multiple valid code matches. This paper introduces CoSQA+, pairing high-quality queries (reused from CoSQA) with multiple suitable codes. We collect code candidates from diverse sources and form candidate pairs by pairing queries with these codes. Utilizing the power of large language models (LLMs), we automate pair annotation, filtering, and code generation for queries without suitable matches. Through extensive experiments, CoSQA+ has demonstrated superior quality over CoSQA. Models trained on CoSQA+ exhibit improved performance. Furthermore, we propose a new metric Mean Multi-choice Reciprocal Rank (MMRR), to assess one-to-N code search performance. We provide the code and data at https://github.com/DeepSoftwareAnalytics/CoSQA_Plus.
Read more8/27/2024
🛸
0
Semantically Aligned Question and Code Generation for Automated Insight Generation
Ananya Singha, Bhavya Chopra, Anirudh Khatry, Sumit Gulwani, Austin Z. Henley, Vu Le, Chris Parnin, Mukul Singh, Gust Verbruggen
Automated insight generation is a common tactic for helping knowledge workers, such as data scientists, to quickly understand the potential value of new and unfamiliar data. Unfortunately, automated insights produced by large-language models can generate code that does not correctly correspond (or align) to the insight. In this paper, we leverage the semantic knowledge of large language models to generate targeted and insightful questions about data and the corresponding code to answer those questions. Then through an empirical study on data from Open-WikiTable, we show that embeddings can be effectively used for filtering out semantically unaligned pairs of question and code. Additionally, we found that generating questions and code together yields more diverse questions.
Read more5/6/2024
👁️
0
REINFOREST: Reinforcing Semantic Code Similarity for Cross-Lingual Code Search Models
Anthony Saieva, Saikat Chakraborty, Gail Kaiser
This paper introduces a novel code-to-code search technique that enhances the performance of Large Language Models (LLMs) by including both static and dynamic features as well as utilizing both similar and dissimilar examples during training. We present the first-ever code search method that encodes dynamic runtime information during training without the need to execute either the corpus under search or the search query at inference time and the first code search technique that trains on both positive and negative reference samples. To validate the efficacy of our approach, we perform a set of studies demonstrating the capability of enhanced LLMs to perform cross-language code-to-code search. Our evaluation demonstrates that the effectiveness of our approach is consistent across various model architectures and programming languages. We outperform the state-of-the-art cross-language search tool by up to 44.7%. Moreover, our ablation studies reveal that even a single positive and negative reference sample in the training process results in substantial performance improvements demonstrating both similar and dissimilar references are important parts of code search. Importantly, we show that enhanced well-crafted, fine-tuned models consistently outperform enhanced larger modern LLMs without fine tuning, even when enhancing the largest available LLMs highlighting the importance for open-sourced models. To ensure the reproducibility and extensibility of our research, we present an open-sourced implementation of our tool and training procedures called REINFOREST.
Read more4/17/2024
0
Rewriting the Code: A Simple Method for Large Language Model Augmented Code Search
Haochen Li, Xin Zhou, Zhiqi Shen
In code search, the Generation-Augmented Retrieval (GAR) framework, which generates exemplar code snippets to augment queries, has emerged as a promising strategy to address the principal challenge of modality misalignment between code snippets and natural language queries, particularly with the demonstrated code generation capabilities of Large Language Models (LLMs). Nevertheless, our preliminary investigations indicate that the improvements conferred by such an LLM-augmented framework are somewhat constrained. This limitation could potentially be ascribed to the fact that the generated codes, albeit functionally accurate, frequently display a pronounced stylistic deviation from the ground truth code in the codebase. In this paper, we extend the foundational GAR framework and propose a simple yet effective method that additionally Rewrites the Code (ReCo) within the codebase for style normalization. Experimental results demonstrate that ReCo significantly boosts retrieval accuracy across sparse (up to 35.7%), zero-shot dense (up to 27.6%), and fine-tuned dense (up to 23.6%) retrieval settings in diverse search scenarios. To further elucidate the advantages of ReCo and stimulate research in code style normalization, we introduce Code Style Similarity, the first metric tailored to quantify stylistic similarities in code. Notably, our empirical findings reveal the inadequacy of existing metrics in capturing stylistic nuances. The source code and data are available at url{https://github.com/Alex-HaochenLi/ReCo}.
Read more6/4/2024