CoLoR-Filter: Conditional Loss Reduction Filtering for Targeted Language Model Pre-training
2406.10670
2
0

Abstract
Selecting high-quality data for pre-training is crucial in shaping the downstream task performance of language models. A major challenge lies in identifying this optimal subset, a problem generally considered intractable, thus necessitating scalable and effective heuristics. In this work, we propose a data selection method, CoLoR-Filter (Conditional Loss Reduction Filtering), which leverages an empirical Bayes-inspired approach to derive a simple and computationally efficient selection criterion based on the relative loss values of two auxiliary models. In addition to the modeling rationale, we evaluate CoLoR-Filter empirically on two language modeling tasks: (1) selecting data from C4 for domain adaptation to evaluation on Books and (2) selecting data from C4 for a suite of downstream multiple-choice question answering tasks. We demonstrate favorable scaling both as we subselect more aggressively and using small auxiliary models to select data for large target models. As one headline result, CoLoR-Filter data selected using a pair of 150m parameter auxiliary models can train a 1.2b parameter target model to match a 1.2b parameter model trained on 25b randomly selected tokens with 25x less data for Books and 11x less data for the downstream tasks. Code: https://github.com/davidbrandfonbrener/color-filter-olmo Filtered data: https://huggingface.co/datasets/davidbrandfonbrener/color-filtered-c4
Create account to get full access
Overview
- A new technique called CoLoR-Filter is introduced for targeted language model pre-training.
- CoLoR-Filter aims to selectively filter training data to focus on specific tasks or domains.
- The method relies on conditional loss reduction to identify the most informative training examples for a given objective.
Plain English Explanation
In the field of natural language processing, training large language models like GPT-3 requires massive amounts of text data. However, this data is often broad and general, which can make it challenging to fine-tune the models for specific tasks or domains.
The researchers behind CoLoR-Filter have developed a new technique to address this issue. Their approach, called "Conditional Loss Reduction Filtering" (CoLoR-Filter), allows for targeted pre-training of language models.
The key idea is to selectively filter the training data, focusing on the examples that are most informative for a particular objective. This is done by analyzing the conditional loss - the amount of error that a model makes on a given training example. By identifying the examples that contribute the most to reducing this loss, the researchers can create a more focused and effective pre-training dataset.
This targeted approach contrasts with traditional data selection methods, which often rely on heuristics or manually curated datasets. CoLoR-Filter's automatic and principled approach can help language models learn more efficiently and perform better on specific tasks, without the need for extensive human curation.
Technical Explanation
The CoLoR-Filter method builds on the idea of using large language models to guide document selection for targeted fine-tuning. However, instead of relying on the model's predictions alone, CoLoR-Filter leverages the model's conditional learning objective to identify the most informative training examples.
Specifically, the researchers propose to compute the conditional loss reduction - the decrease in a model's loss function when a particular training example is added. By ranking the training examples based on their conditional loss reduction, the researchers can then select the most informative subset for pre-training the language model.
The authors demonstrate the effectiveness of CoLoR-Filter through extensive experiments, comparing it to alternative data selection methods. Their results show that the targeted pre-training approach enabled by CoLoR-Filter can lead to significant performance gains on a variety of downstream tasks, while using a smaller and more efficient training dataset.
Critical Analysis
The CoLoR-Filter paper presents a novel and principled approach to data selection for language model pre-training. By leveraging the conditional learning objective, the method can identify the most informative training examples in an automatic and data-driven manner, reducing the need for manual curation.
However, the paper does not discuss some potential limitations of the approach. For instance, the conditional loss reduction metric may be susceptible to biases in the training data or model architecture. Additionally, the computational overhead of computing the conditional loss for each training example could be a bottleneck, especially for very large datasets.
Furthermore, the paper could have explored the robustness of CoLoR-Filter to different types of downstream tasks and datasets. It would be interesting to see how the method performs on a wider range of applications, including more specialized or domain-specific tasks.
Conclusion
The CoLoR-Filter technique introduced in this paper represents a significant advancement in the field of targeted language model pre-training. By prioritizing the most informative training examples, the method can lead to more efficient and effective model development, with potential benefits across a wide range of natural language processing applications.
While the paper does not address all potential limitations, the core ideas behind CoLoR-Filter are compelling and open up new avenues for further research in data selection and conditional learning. As the field of large language models continues to evolve, techniques like CoLoR-Filter will likely play an increasingly important role in ensuring that these powerful models are optimized for specific tasks and domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Get more for less: Principled Data Selection for Warming Up Fine-Tuning in LLMs
Feiyang Kang, Hoang Anh Just, Yifan Sun, Himanshu Jahagirdar, Yuanzhi Zhang, Rongxing Du, Anit Kumar Sahu, Ruoxi Jia
0
0
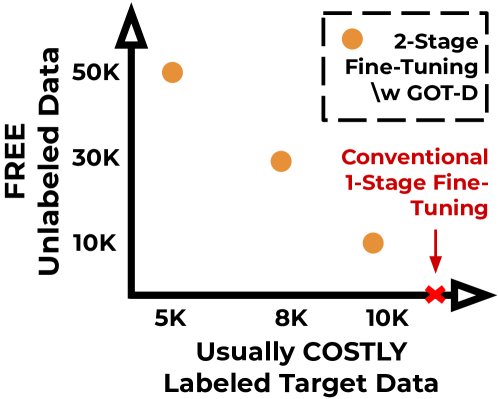
This work focuses on leveraging and selecting from vast, unlabeled, open data to pre-fine-tune a pre-trained language model. The goal is to minimize the need for costly domain-specific data for subsequent fine-tuning while achieving desired performance levels. While many data selection algorithms have been designed for small-scale applications, rendering them unsuitable for our context, some emerging methods do cater to language data scales. However, they often prioritize data that aligns with the target distribution. While this strategy may be effective when training a model from scratch, it can yield limited results when the model has already been pre-trained on a different distribution. Differing from prior work, our key idea is to select data that nudges the pre-training distribution closer to the target distribution. We show the optimality of this approach for fine-tuning tasks under certain conditions. We demonstrate the efficacy of our methodology across a diverse array of tasks (NLU, NLG, zero-shot) with models up to 2.7B, showing that it consistently surpasses other selection methods. Moreover, our proposed method is significantly faster than existing techniques, scaling to millions of samples within a single GPU hour. Our code is open-sourced (Code repository: https://anonymous.4open.science/r/DV4LLM-D761/ ). While fine-tuning offers significant potential for enhancing performance across diverse tasks, its associated costs often limit its widespread adoption; with this work, we hope to lay the groundwork for cost-effective fine-tuning, making its benefits more accessible.
5/7/2024
Filtered Corpus Training (FiCT) Shows that Language Models can Generalize from Indirect Evidence
Abhinav Patil, Jaap Jumelet, Yu Ying Chiu, Andy Lapastora, Peter Shen, Lexie Wang, Clevis Willrich, Shane Steinert-Threlkeld
0
0
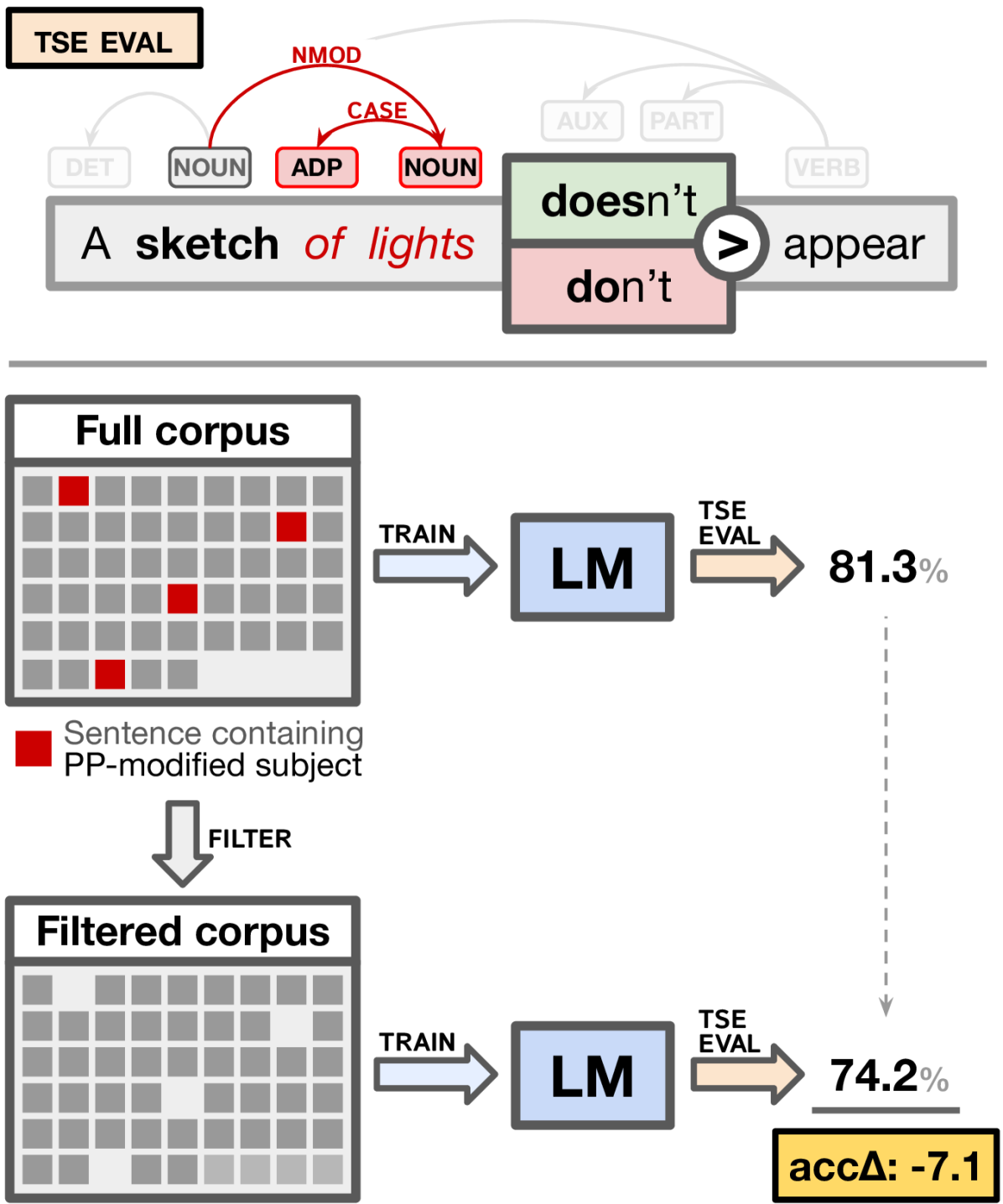
This paper introduces Filtered Corpus Training, a method that trains language models (LMs) on corpora with certain linguistic constructions filtered out from the training data, and uses it to measure the ability of LMs to perform linguistic generalization on the basis of indirect evidence. We apply the method to both LSTM and Transformer LMs (of roughly comparable size), developing filtered corpora that target a wide range of linguistic phenomena. Our results show that while transformers are better qua LMs (as measured by perplexity), both models perform equally and surprisingly well on linguistic generalization measures, suggesting that they are capable of generalizing from indirect evidence.
5/27/2024
Large Language Model-guided Document Selection
Xiang Kong, Tom Gunter, Ruoming Pang
0
0
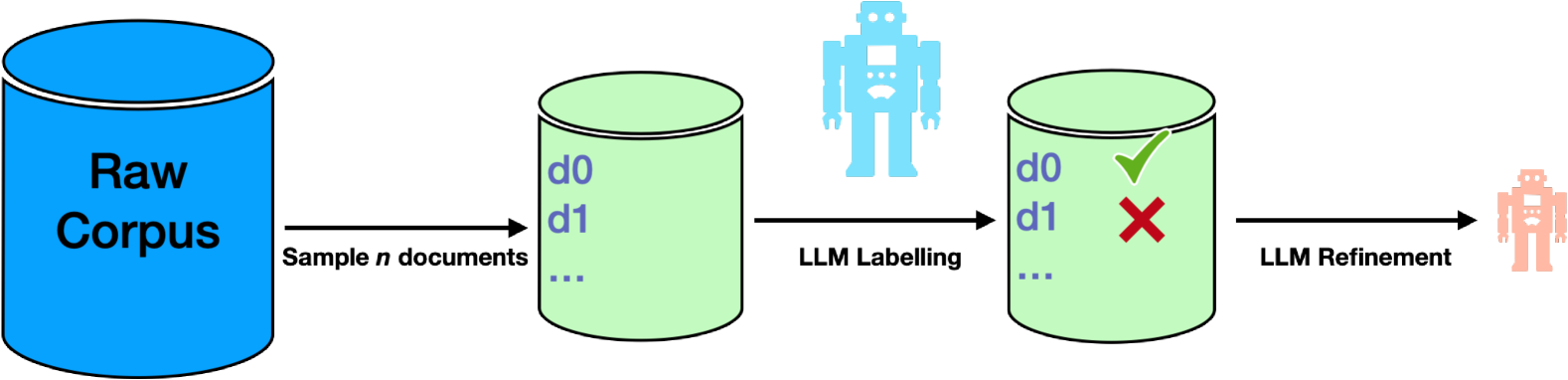
Large Language Model (LLM) pre-training exhausts an ever growing compute budget, yet recent research has demonstrated that careful document selection enables comparable model quality with only a fraction of the FLOPs. Inspired by efforts suggesting that domain-specific training document selection is in fact an interpretable process [Gunasekar et al., 2023], as well as research showing that instruction-finetuned LLMs are adept zero-shot data labelers [Gilardi et al.,2023], we explore a promising direction for scalable general-domain document selection; employing a prompted LLM as a document grader, we distill quality labels into a classifier model, which is applied at scale to a large, and already heavily-filtered, web-crawl-derived corpus autonomously. Following the guidance of this classifier, we drop 75% of the corpus and train LLMs on the remaining data. Results across multiple benchmarks show that: 1. Filtering allows us to quality-match a model trained on the full corpus across diverse benchmarks with at most 70% of the FLOPs, 2. More capable LLM labelers and classifier models lead to better results that are less sensitive to the labeler's prompt, 3. In-context learning helps to boost the performance of less-capable labeling models. In all cases we use open-source datasets, models, recipes, and evaluation frameworks, so that results can be reproduced by the community.
6/10/2024

Conditional Language Learning with Context
Xiao Zhang, Miao Li, Ji Wu
0
0
Language models can learn sophisticated language understanding skills from fitting raw text. They also unselectively learn useless corpus statistics and biases, especially during finetuning on domain-specific corpora. In this paper, we propose a simple modification to causal language modeling called conditional finetuning, which performs language modeling conditioned on a context. We show that a context can explain away certain corpus statistics and make the model avoid learning them. In this fashion, conditional finetuning achieves selective learning from a corpus, learning knowledge useful for downstream tasks while avoiding learning useless corpus statistics like topic biases. This selective learning effect leads to less forgetting and better stability-plasticity tradeoff in domain finetuning, potentially benefitting lifelong learning with language models.
6/5/2024