Conditional Language Learning with Context
2406.01976
0
0

Abstract
Language models can learn sophisticated language understanding skills from fitting raw text. They also unselectively learn useless corpus statistics and biases, especially during finetuning on domain-specific corpora. In this paper, we propose a simple modification to causal language modeling called conditional finetuning, which performs language modeling conditioned on a context. We show that a context can explain away certain corpus statistics and make the model avoid learning them. In this fashion, conditional finetuning achieves selective learning from a corpus, learning knowledge useful for downstream tasks while avoiding learning useless corpus statistics like topic biases. This selective learning effect leads to less forgetting and better stability-plasticity tradeoff in domain finetuning, potentially benefitting lifelong learning with language models.
Create account to get full access
Overview
- This paper introduces a novel approach called "Conditional Language Learning with Context" for training language models to better understand and generate text in context.
- The key idea is to condition the language model on additional contextual information beyond just the text itself, such as the task, domain, or the user's goals.
- The authors hypothesize that this can help the model learn more robust and generalizable representations, leading to improved performance on a variety of downstream tasks.
Plain English Explanation
The paper presents a new way to train language models, which are AI systems that can understand and generate human language. Typically, language models are trained on lots of text data, and they learn patterns in the language to become good at tasks like answering questions or summarizing articles.
However, the authors of this paper argue that this approach has limitations. Language often depends heavily on the context it's used in - the specific task, the domain of knowledge, the goals of the user, and so on. A model trained only on the text itself may struggle to fully capture these nuances.
To address this, the researchers propose "Conditional Language Learning with Context". The core idea is to train the language model not just on the text, but also on additional information about the context. For example, the model might be given information about the task the user is trying to accomplish, or the subject matter of the text.
The hypothesis is that by learning to understand language in context, the model will develop more robust and generalizable representations. This could lead to better performance on a wide range of language-related tasks, beyond just what the model was trained on.
The paper explores this idea through a series of experiments, comparing the conditional language learning approach to more traditional language model training. The results suggest that incorporating contextual information can indeed improve the model's capabilities, especially on tasks that require deeper understanding of the text's meaning and purpose.
Technical Explanation
The key innovation in this paper is the Conditional Language Learning with Context approach. Typically, language models are trained solely on the text data, learning to predict the next word or generate coherent sequences of text.
However, the authors argue that this ignores important contextual information that humans use to understand and use language. To address this, they propose conditioning the language model on additional context beyond just the text, such as the task, domain, or user goals. This is done by providing the model with this contextual information as an additional input, along with the text.
The authors hypothesize that this conditional learning approach will lead to more robust and generalizable representations, as the model learns to associate the text with the relevant contextual cues. This could translate to improved performance on a variety of downstream tasks that require understanding language in context.
To test this, the researchers conduct experiments on several benchmark datasets, comparing the conditional language learning approach to more traditional language model training. The results indicate that incorporating contextual information does indeed boost performance, especially on tasks that require deeper semantic understanding rather than just surface-level language modeling.
The authors also explore the generalization capabilities of the conditional models, showing that they can transfer better to new domains and tasks compared to their context-agnostic counterparts. However, they also note some limitations around the robustness of this context learning approach, suggesting areas for future research.
Critical Analysis
The key strength of this research is the intuition that language is fundamentally contextual, and that training language models to explicitly capture this context can lead to significant performance gains. The authors make a compelling case for why traditional language modeling approaches may be insufficient, and their conditional learning framework provides a principled way to incorporate relevant contextual information.
That said, the paper also acknowledges some limitations of this approach. While the conditional models demonstrate improved generalization to new domains and tasks, the authors note that this context learning does not always lead to fully robust and reliable performance. There are likely still challenges in ensuring the models can flexibly adapt to novel contexts beyond what they were trained on.
Additionally, the specific choice of contextual information to provide the model, and how to best represent and integrate it, remains an open challenge. The paper explores a few different options, but more research is needed to fully understand the optimal way to condition language models on relevant context.
Overall, this research represents an important step forward in enhancing the contextual understanding of language models. While there is more work to be done, the conditional learning approach proposed here offers a promising direction for developing more capable and versatile natural language AI systems.
Conclusion
This paper introduces a novel approach called "Conditional Language Learning with Context" for training more capable and contextually-aware language models. By conditioning the model not just on the text, but also on relevant contextual information like the task, domain, or user goals, the researchers demonstrate improved performance on a variety of language understanding and generation tasks.
The key insight is that language is fundamentally shaped by its context, and that traditional language modeling approaches that ignore this context may be inherently limited. The conditional learning framework proposed here offers a principled way to incorporate this contextual awareness, leading to more robust and generalizable language representations.
While the research also highlights some limitations and areas for further exploration, the overall findings suggest that this direction of explicitly modeling language in context holds significant promise for advancing the state-of-the-art in natural language AI. As language models become increasingly ubiquitous, ensuring they can truly understand and adapt to the nuances of human communication will be crucial for unlocking their full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Language Models for Text Classification: Is In-Context Learning Enough?
Aleksandra Edwards, Jose Camacho-Collados
0
0
Recent foundational language models have shown state-of-the-art performance in many NLP tasks in zero- and few-shot settings. An advantage of these models over more standard approaches based on fine-tuning is the ability to understand instructions written in natural language (prompts), which helps them generalise better to different tasks and domains without the need for specific training data. This makes them suitable for addressing text classification problems for domains with limited amounts of annotated instances. However, existing research is limited in scale and lacks understanding of how text generation models combined with prompting techniques compare to more established methods for text classification such as fine-tuning masked language models. In this paper, we address this research gap by performing a large-scale evaluation study for 16 text classification datasets covering binary, multiclass, and multilabel problems. In particular, we compare zero- and few-shot approaches of large language models to fine-tuning smaller language models. We also analyse the results by prompt, classification type, domain, and number of labels. In general, the results show how fine-tuning smaller and more efficient language models can still outperform few-shot approaches of larger language models, which have room for improvement when it comes to text classification.
4/16/2024
Large Language Models for Constrained-Based Causal Discovery
Kai-Hendrik Cohrs, Gherardo Varando, Emiliano Diaz, Vasileios Sitokonstantinou, Gustau Camps-Valls
0
0
Causality is essential for understanding complex systems, such as the economy, the brain, and the climate. Constructing causal graphs often relies on either data-driven or expert-driven approaches, both fraught with challenges. The former methods, like the celebrated PC algorithm, face issues with data requirements and assumptions of causal sufficiency, while the latter demand substantial time and domain knowledge. This work explores the capabilities of Large Language Models (LLMs) as an alternative to domain experts for causal graph generation. We frame conditional independence queries as prompts to LLMs and employ the PC algorithm with the answers. The performance of the LLM-based conditional independence oracle on systems with known causal graphs shows a high degree of variability. We improve the performance through a proposed statistical-inspired voting schema that allows some control over false-positive and false-negative rates. Inspecting the chain-of-thought argumentation, we find causal reasoning to justify its answer to a probabilistic query. We show evidence that knowledge-based CIT could eventually become a complementary tool for data-driven causal discovery.
6/12/2024
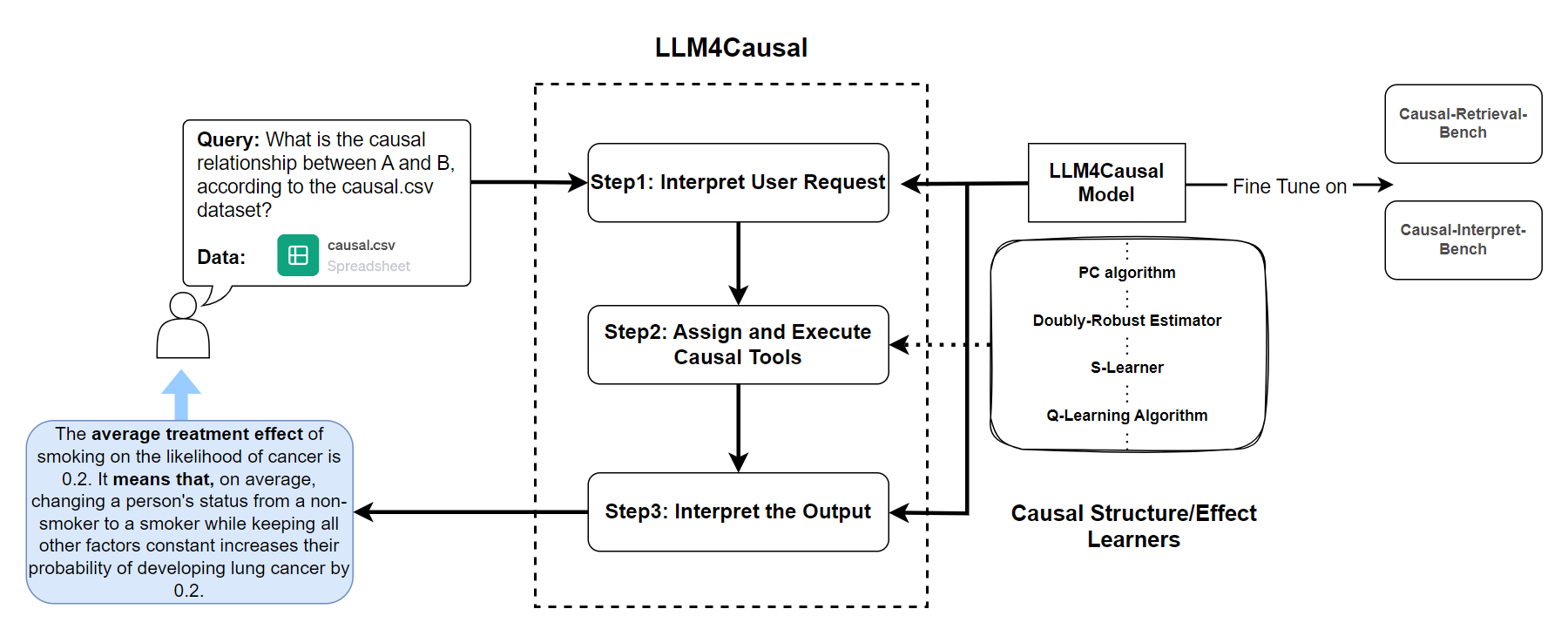
Large Language Model for Causal Decision Making
Haitao Jiang, Lin Ge, Yuhe Gao, Jianian Wang, Rui Song
0
0
Large Language Models (LLMs) have shown their success in language understanding and reasoning on general topics. However, their capability to perform inference based on user-specified structured data and knowledge in corpus-rare concepts, such as causal decision-making is still limited. In this work, we explore the possibility of fine-tuning an open-sourced LLM into LLM4Causal, which can identify the causal task, execute a corresponding function, and interpret its numerical results based on users' queries and the provided dataset. Meanwhile, we propose a data generation process for more controllable GPT prompting and present two instruction-tuning datasets: (1) Causal-Retrieval-Bench for causal problem identification and input parameter extraction for causal function calling and (2) Causal-Interpret-Bench for in-context causal interpretation. By conducting end-to-end evaluations and two ablation studies, we showed that LLM4Causal can deliver end-to-end solutions for causal problems and provide easy-to-understand answers, which significantly outperforms the baselines.
4/15/2024

Supervised Knowledge Makes Large Language Models Better In-context Learners
Linyi Yang, Shuibai Zhang, Zhuohao Yu, Guangsheng Bao, Yidong Wang, Jindong Wang, Ruochen Xu, Wei Ye, Xing Xie, Weizhu Chen, Yue Zhang
0
0
Large Language Models (LLMs) exhibit emerging in-context learning abilities through prompt engineering. The recent progress in large-scale generative models has further expanded their use in real-world language applications. However, the critical challenge of improving the generalizability and factuality of LLMs in natural language understanding and question answering remains under-explored. While previous in-context learning research has focused on enhancing models to adhere to users' specific instructions and quality expectations, and to avoid undesired outputs, little to no work has explored the use of task-Specific fine-tuned Language Models (SLMs) to improve LLMs' in-context learning during the inference stage. Our primary contribution is the establishment of a simple yet effective framework that enhances the reliability of LLMs as it: 1) generalizes out-of-distribution data, 2) elucidates how LLMs benefit from discriminative models, and 3) minimizes hallucinations in generative tasks. Using our proposed plug-in method, enhanced versions of Llama 2 and ChatGPT surpass their original versions regarding generalizability and factuality. We offer a comprehensive suite of resources, including 16 curated datasets, prompts, model checkpoints, and LLM outputs across 9 distinct tasks. The code and data are released at: https://github.com/YangLinyi/Supervised-Knowledge-Makes-Large-Language-Models-Better-In-context-Learners. Our empirical analysis sheds light on the advantages of incorporating discriminative models into LLMs and highlights the potential of our methodology in fostering more reliable LLMs.
4/12/2024