COLUMBUS: Evaluating COgnitive Lateral Understanding through Multiple-choice reBUSes

0
Sign in to get full access
Overview
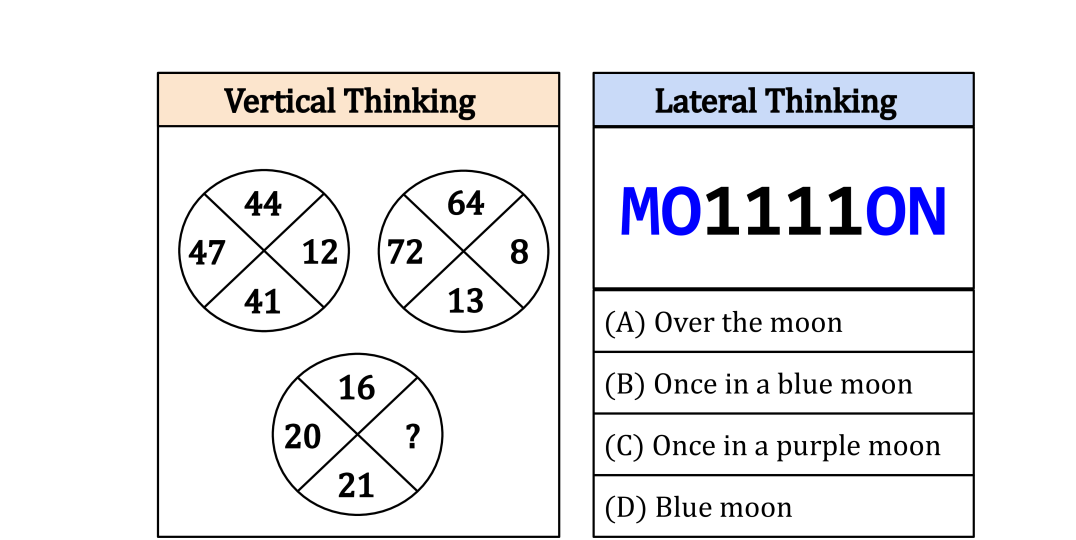
- The paper presents COLUMBUS, a multiple-choice task for evaluating the cognitive lateral understanding of AI models.
- COLUMBUS aims to assess an AI's ability to reason about concepts and make associations beyond just surface-level understanding.
- The task involves solving "reBUSes" - visual puzzles that require lateral thinking and abstraction to decode.
Plain English Explanation
The researchers developed a new way to test how well AI models can understand concepts and make connections beyond just memorizing facts. They call this "cognitive lateral understanding."
The test, called COLUMBUS, presents the AI with visual puzzles called "reBUSes." To solve these puzzles, the model needs to go beyond literal interpretations and make abstract associations. This taps into a deeper level of reasoning and understanding, rather than just recognizing surface-level patterns.
By having the AI try to decode these reBUSes, the researchers can evaluate how well it can grasp concepts, think laterally, and make unexpected connections - skills that are important for true cognitive reasoning.
Technical Explanation
The COLUMBUS task presents the AI model with a multiple-choice reBUS, where the goal is to select the correct solution from several options. The reBUS consists of a visual puzzle made up of symbols, shapes, and text. Solving the reBUS requires the model to understand the underlying concepts and make lateral associations, rather than just recognizing individual elements.
The researchers evaluated several state-of-the-art vision-language models on the COLUMBUS task. The results showed that while these models performed well on more literal, surface-level tasks, they struggled to demonstrate the cognitive lateral understanding needed to solve the reBUSes. This highlights an important gap between current AI capabilities and the depth of reasoning and abstraction that humans can readily perform.
Critical Analysis
The COLUMBUS task provides a novel and valuable benchmark for assessing the cognitive reasoning abilities of AI models. By focusing on lateral thinking and conceptual understanding, rather than just pattern recognition, it pushes models to demonstrate more human-like intelligence.
However, the paper acknowledges that reBUSes may favor certain types of reasoning and abstraction over others. There may be other forms of cognitive lateral understanding that are not well-captured by this particular task. Further research is needed to develop a more comprehensive suite of benchmarks that can fully evaluate the breadth of human-level cognitive capabilities.
Additionally, the study only tested a limited set of state-of-the-art vision-language models. It would be informative to see how a wider range of AI architectures and approaches perform on the COLUMBUS task, as well as how human performance compares.
Conclusion
The COLUMBUS benchmark represents an important step forward in evaluating the cognitive capabilities of AI systems. By focusing on lateral thinking and conceptual understanding, rather than just surface-level pattern recognition, it highlights crucial gaps between current AI and human-level intelligence.
While more work is needed to develop a comprehensive set of cognitive evaluation tools, the COLUMBUS task provides a valuable new way to push the boundaries of AI reasoning and abstraction. As the field continues to advance, such benchmarks will be crucial for driving progress towards artificial general intelligence that can match the depth and flexibility of human cognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
COLUMBUS: Evaluating COgnitive Lateral Understanding through Multiple-choice reBUSes
Koen Kraaijveld, Yifan Jiang, Kaixin Ma, Filip Ilievski
While visual question-answering (VQA) benchmarks have catalyzed the development of reasoning techniques, they have focused on vertical thinking. Effective problem-solving also necessitates lateral thinking, which remains understudied in AI and has not been used to test visual perception systems. To bridge this gap, we formulate visual lateral thinking as a multiple-choice question-answering task and describe a three-step taxonomy-driven methodology for instantiating task examples. Then, we develop COLUMBUS, a synthetic benchmark that applies the task pipeline to create QA sets with text and icon rebus puzzles based on publicly available collections of compounds and common phrases. COLUMBUS comprises over 1,000 puzzles, each with four answer candidates. While the SotA vision-language models (VLMs) achieve decent performance, our evaluation demonstrates a substantial gap between humans and models. VLMs benefit from human-curated descriptions but struggle to self-generate such representations at the right level of abstraction.
Read more9/11/2024

0
NTSEBENCH: Cognitive Reasoning Benchmark for Vision Language Models
Pranshu Pandya, Agney S Talwarr, Vatsal Gupta, Tushar Kataria, Vivek Gupta, Dan Roth
Cognitive textual and visual reasoning tasks, such as puzzles, series, and analogies, demand the ability to quickly reason, decipher, and evaluate patterns both textually and spatially. While LLMs and VLMs, through extensive training on large amounts of human-curated data, have attained a high level of pseudo-human intelligence in some common sense reasoning tasks, they still struggle with more complex reasoning tasks that require cognitive understanding. In this work, we introduce a new dataset, NTSEBench, designed to evaluate the cognitive multi-modal reasoning and problem-solving skills of large models. The dataset comprises 2,728 multiple-choice questions comprising of a total of 4,642 images across 26 categories sampled from the NTSE examination conducted nationwide in India, featuring both visual and textual general aptitude questions that do not rely on rote learning. We establish baselines on the dataset using state-of-the-art LLMs and VLMs. To facilitate a comparison between open source and propriety models, we propose four distinct modeling strategies to handle different modalities (text and images) in the dataset instances.
Read more7/16/2024

0
REBUS: A Robust Evaluation Benchmark of Understanding Symbols
Andrew Gritsevskiy, Arjun Panickssery, Aaron Kirtland, Derik Kauffman, Hans Gundlach, Irina Gritsevskaya, Joe Cavanagh, Jonathan Chiang, Lydia La Roux, Michelle Hung
We propose a new benchmark evaluating the performance of multimodal large language models on rebus puzzles. The dataset covers 333 original examples of image-based wordplay, cluing 13 categories such as movies, composers, major cities, and food. To achieve good performance on the benchmark of identifying the clued word or phrase, models must combine image recognition and string manipulation with hypothesis testing, multi-step reasoning, and an understanding of human cognition, making for a complex, multimodal evaluation of capabilities. We find that GPT-4o significantly outperforms all other models, followed by proprietary models outperforming all other evaluated models. However, even the best model has a final accuracy of only 42%, which goes down to just 7% on hard puzzles, highlighting the need for substantial improvements in reasoning. Further, models rarely understand all parts of a puzzle, and are almost always incapable of retroactively explaining the correct answer. Our benchmark can therefore be used to identify major shortcomings in the knowledge and reasoning of multimodal large language models.
Read more6/5/2024
0
What is the Visual Cognition Gap between Humans and Multimodal LLMs?
Xu Cao, Bolin Lai, Wenqian Ye, Yunsheng Ma, Joerg Heintz, Jintai Chen, Jianguo Cao, James M. Rehg
Recently, Multimodal Large Language Models (MLLMs) have shown great promise in language-guided perceptual tasks such as recognition, segmentation, and object detection. However, their effectiveness in addressing visual cognition problems that require high-level reasoning is not well-established. One such challenge is abstract visual reasoning (AVR) -- the cognitive ability to discern relationships among patterns in a set of images and extrapolate to predict subsequent patterns. This skill is crucial during the early neurodevelopmental stages of children. Inspired by the AVR tasks in Raven's Progressive Matrices (RPM) and Wechsler Intelligence Scale for Children (WISC), we propose a new dataset MaRs-VQA and a new benchmark VCog-Bench containing three datasets to evaluate the zero-shot AVR capability of MLLMs and compare their performance with existing human intelligent investigation. Our comparative experiments with different open-source and closed-source MLLMs on the VCog-Bench revealed a gap between MLLMs and human intelligence, highlighting the visual cognitive limitations of current MLLMs. We believe that the public release of VCog-Bench, consisting of MaRs-VQA, and the inference pipeline will drive progress toward the next generation of MLLMs with human-like visual cognition abilities.
Read more6/18/2024