REBUS: A Robust Evaluation Benchmark of Understanding Symbols

0

Sign in to get full access
Overview
- The paper introduces the REBUS benchmark, a new evaluation dataset for assessing the ability of language models to understand and reason about symbolic concepts.
- REBUS consists of a diverse set of questions that require models to identify, interpret, and manipulate various types of symbols, including mathematical expressions, chemical formulas, and programming code.
- The authors evaluate several state-of-the-art language models on the REBUS benchmark and find that while these models perform well on natural language tasks, they struggle with tasks that involve symbolic reasoning.
Plain English Explanation
The REBUS paper presents a new evaluation dataset called REBUS that is designed to test how well language models can understand and reason about symbolic concepts. These symbolic concepts can take many forms, such as mathematical equations, chemical formulas, or programming code.
The key idea behind REBUS is that while modern language models have become very good at processing and generating natural language, they may still struggle with tasks that require understanding and manipulating symbolic information. By creating a diverse set of questions that involve these types of symbols, the REBUS benchmark aims to identify the strengths and weaknesses of current language models when it comes to symbolic reasoning.
The authors evaluate several state-of-the-art language models on the REBUS benchmark and find that while these models perform well on typical language tasks, they have difficulty with the symbolic reasoning required by the REBUS questions. This suggests that there is still room for improvement in developing language models that can truly understand and reason about symbolic concepts, not just natural language.
Technical Explanation
The REBUS benchmark is designed to assess the ability of language models to understand and reason about symbolic concepts, which are a fundamental part of human intelligence and communication. The benchmark consists of a diverse set of questions that require models to identify, interpret, and manipulate various types of symbols, including mathematical expressions, chemical formulas, and programming code.
The authors evaluate several state-of-the-art language models, such as GPT-3, on the REBUS benchmark and find that while these models perform well on natural language tasks, they struggle with the symbolic reasoning required by the REBUS questions. This suggests that current language models, despite their impressive capabilities, still have significant limitations when it comes to understanding and reasoning about symbolic information.
The REBUS benchmark is inspired by related efforts, such as PuzzleVQA, M4U, RAR-B, and Puzzle Solving, which have also explored the limitations of language models in various domains. Similarly, the MMBench benchmark has focused on evaluating multimodal models, which combine language and other modalities like images or videos.
Critical Analysis
The REBUS benchmark provides a valuable contribution to the field by highlighting the need for language models to develop more robust symbolic reasoning capabilities. While current state-of-the-art models perform well on natural language tasks, the authors' findings suggest that these models still struggle with tasks that require a deeper understanding of symbolic concepts.
One potential limitation of the REBUS benchmark is the specific types of symbolic tasks it focuses on, such as mathematical expressions and programming code. It is possible that language models could perform better on other types of symbolic reasoning tasks, or that the benchmark could be expanded to include a wider range of symbolic concepts.
Additionally, the paper does not provide a detailed analysis of the specific challenges that language models face when dealing with symbolic reasoning. Further research could explore the underlying cognitive and architectural factors that contribute to these limitations, which could inform the development of more advanced language models capable of more robust symbolic understanding.
Conclusion
The REBUS paper introduces an important new benchmark for assessing the symbolic reasoning capabilities of language models. The authors' findings suggest that while current state-of-the-art language models are highly capable in natural language tasks, they still struggle with tasks that require a deeper understanding of symbolic concepts.
This work highlights the need for continued research and development in the field of language models, particularly in expanding their ability to reason about and manipulate symbolic information. By addressing these limitations, future language models could become even more powerful and versatile tools for a wide range of applications, from scientific and mathematical reasoning to programming and problem-solving.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
REBUS: A Robust Evaluation Benchmark of Understanding Symbols
Andrew Gritsevskiy, Arjun Panickssery, Aaron Kirtland, Derik Kauffman, Hans Gundlach, Irina Gritsevskaya, Joe Cavanagh, Jonathan Chiang, Lydia La Roux, Michelle Hung
We propose a new benchmark evaluating the performance of multimodal large language models on rebus puzzles. The dataset covers 333 original examples of image-based wordplay, cluing 13 categories such as movies, composers, major cities, and food. To achieve good performance on the benchmark of identifying the clued word or phrase, models must combine image recognition and string manipulation with hypothesis testing, multi-step reasoning, and an understanding of human cognition, making for a complex, multimodal evaluation of capabilities. We find that GPT-4o significantly outperforms all other models, followed by proprietary models outperforming all other evaluated models. However, even the best model has a final accuracy of only 42%, which goes down to just 7% on hard puzzles, highlighting the need for substantial improvements in reasoning. Further, models rarely understand all parts of a puzzle, and are almost always incapable of retroactively explaining the correct answer. Our benchmark can therefore be used to identify major shortcomings in the knowledge and reasoning of multimodal large language models.
Read more6/5/2024

0
Non Verbis, Sed Rebus: Large Language Models are Weak Solvers of Italian Rebuses
Gabriele Sarti, Tommaso Caselli, Malvina Nissim, Arianna Bisazza
Rebuses are puzzles requiring constrained multi-step reasoning to identify a hidden phrase from a set of images and letters. In this work, we introduce a large collection of verbalized rebuses for the Italian language and use it to assess the rebus-solving capabilities of state-of-the-art large language models. While general-purpose systems such as LLaMA-3 and GPT-4o perform poorly on this task, ad-hoc fine-tuning seems to improve models' performance. However, we find that performance gains from training are largely motivated by memorization. Our results suggest that rebus solving remains a challenging test bed to evaluate large language models' linguistic proficiency and sequential instruction-following skills.
Read more8/2/2024

0
Creating a Lens of Chinese Culture: A Multimodal Dataset for Chinese Pun Rebus Art Understanding
Tuo Zhang, Tiantian Feng, Yibin Ni, Mengqin Cao, Ruying Liu, Katharine Butler, Yanjun Weng, Mi Zhang, Shrikanth S. Narayanan, Salman Avestimehr
Large vision-language models (VLMs) have demonstrated remarkable abilities in understanding everyday content. However, their performance in the domain of art, particularly culturally rich art forms, remains less explored. As a pearl of human wisdom and creativity, art encapsulates complex cultural narratives and symbolism. In this paper, we offer the Pun Rebus Art Dataset, a multimodal dataset for art understanding deeply rooted in traditional Chinese culture. We focus on three primary tasks: identifying salient visual elements, matching elements with their symbolic meanings, and explanations for the conveyed messages. Our evaluation reveals that state-of-the-art VLMs struggle with these tasks, often providing biased and hallucinated explanations and showing limited improvement through in-context learning. By releasing the Pun Rebus Art Dataset, we aim to facilitate the development of VLMs that can better understand and interpret culturally specific content, promoting greater inclusiveness beyond English-based corpora.
Read more6/18/2024
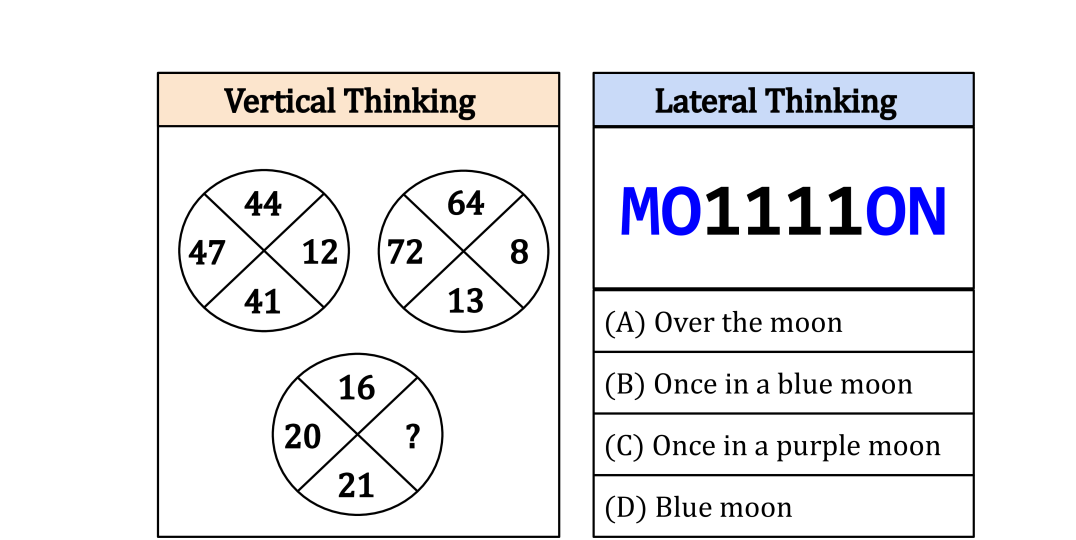
0
COLUMBUS: Evaluating COgnitive Lateral Understanding through Multiple-choice reBUSes
Koen Kraaijveld, Yifan Jiang, Kaixin Ma, Filip Ilievski
While visual question-answering (VQA) benchmarks have catalyzed the development of reasoning techniques, they have focused on vertical thinking. Effective problem-solving also necessitates lateral thinking, which remains understudied in AI and has not been used to test visual perception systems. To bridge this gap, we formulate visual lateral thinking as a multiple-choice question-answering task and describe a three-step taxonomy-driven methodology for instantiating task examples. Then, we develop COLUMBUS, a synthetic benchmark that applies the task pipeline to create QA sets with text and icon rebus puzzles based on publicly available collections of compounds and common phrases. COLUMBUS comprises over 1,000 puzzles, each with four answer candidates. While the SotA vision-language models (VLMs) achieve decent performance, our evaluation demonstrates a substantial gap between humans and models. VLMs benefit from human-curated descriptions but struggle to self-generate such representations at the right level of abstraction.
Read more9/11/2024