Combined CNN and ViT features off-the-shelf: Another astounding baseline for recognition

0

Sign in to get full access
Overview
- This paper explores the use of combined features from Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) for improved recognition performance, especially in challenging tasks like periocular recognition.
- The authors demonstrate that off-the-shelf features from these models can serve as a strong baseline, outperforming specialized models designed for these tasks.
- The findings suggest that leveraging the complementary strengths of CNNs and ViTs can lead to significant improvements in various recognition tasks.
Plain English Explanation
The researchers in this study wanted to see if they could get better results in recognition tasks, like identifying people from the area around their eyes, by combining features from two different types of deep learning models: Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs).
CNNs are a type of neural network that are particularly good at processing and understanding visual information, like images. ViTs, on the other hand, use a different approach called "attention" to capture the relationships between different parts of an image.
The researchers found that by taking the features (the important information) learned by both of these models and combining them, they were able to get better results on recognition tasks than using either model on its own. This was true even when they just used the features "off-the-shelf" (without further training or fine-tuning the models).
The key insight is that the different strengths of CNNs and ViTs can complement each other, leading to improved performance on challenging recognition problems, like identifying people from the area around their eyes (called "periocular recognition"). This suggests that leveraging the combined power of these two types of models could be a powerful approach for a wide range of computer vision and recognition tasks.
Technical Explanation
The authors of this paper investigate the use of combined features from Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) as a strong baseline for various recognition tasks, particularly focusing on the challenging problem of periocular recognition.
The authors hypothesize that the complementary strengths of CNNs and ViTs can be leveraged to achieve improved recognition performance. CNNs are known for their ability to effectively capture local, spatially-correlated visual patterns, while ViTs excel at capturing long-range dependencies and global contextual information.
To test their hypothesis, the authors conduct extensive experiments on several periocular recognition datasets, including VISOB, IJB-C, and CASIA-Iris-Interval. They extract features from pre-trained CNN and ViT models (e.g., ResNet-50, ViT-B/16) and concatenate them to form a combined feature representation. This combined feature is then evaluated using a simple linear classifier for recognition tasks.
The results demonstrate that the proposed approach of using off-the-shelf combined CNN and ViT features outperforms specialized models designed for periocular recognition, as well as individual CNN or ViT features alone. The authors attribute this success to the complementary nature of the features learned by the two types of models, which capture different aspects of the visual information.
Furthermore, the authors investigate the performance of their approach in one-shot learning scenarios, where only a single training sample per class is available. Even in this challenging setting, the combined CNN and ViT features show impressive performance, highlighting their strong generalization capabilities.
The findings of this paper suggest that leveraging the combined strengths of CNNs and ViTs can lead to significant improvements in various recognition tasks, including those that are traditionally considered challenging, such as periocular recognition. The authors provide a simple yet effective baseline that can serve as a starting point for further research and development in this area.
Critical Analysis
The authors present a compelling approach that effectively leverages the complementary strengths of CNNs and ViTs for improved recognition performance. However, the paper could benefit from further discussion of potential limitations and areas for future research.
One aspect that could be explored is the generalizability of the findings to other recognition tasks beyond periocular recognition. While the authors demonstrate the effectiveness of their approach on several periocular datasets, it would be valuable to understand how the combined CNN and ViT features perform on a broader range of recognition problems, such as object recognition, medical image analysis, or change detection.
Additionally, the paper could delve deeper into the specific mechanisms by which the combined features from CNNs and ViTs lead to the observed performance improvements. Understanding the complementary roles of the two types of features and how they interact could provide valuable insights for future model design and optimization.
Furthermore, the authors could explore the impact of different CNN and ViT architectures on the recognition performance. Investigating the tradeoffs between model complexity, feature quality, and computational efficiency could help researchers and practitioners choose the most appropriate combination of models for their specific use cases.
Overall, the paper presents a promising approach that demonstrates the value of leveraging the strengths of both CNNs and ViTs for recognition tasks. By addressing the suggested areas for further exploration, the authors can further strengthen the impact and applicability of their findings.
Conclusion
This paper introduces a simple yet effective baseline for recognition tasks, particularly in the challenging domain of periocular recognition. By combining features from pre-trained Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), the authors show that off-the-shelf features can outperform specialized models designed for these tasks.
The key insight is that the complementary strengths of CNNs and ViTs can be effectively leveraged to capture a more comprehensive representation of the visual information, leading to improved recognition performance. This approach demonstrates the power of combining different deep learning architectures to tackle complex recognition problems.
The findings of this paper have significant implications for the broader computer vision and biometrics communities. The proposed baseline can serve as a strong starting point for further research and development, and the insights gained can inform the design of more sophisticated recognition systems that harness the synergies between different deep learning models.
Overall, this work highlights the potential of combining CNN and ViT features to achieve astounding baseline results, paving the way for further advancements in recognition tasks and potentially influencing the trajectory of the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Combined CNN and ViT features off-the-shelf: Another astounding baseline for recognition
Fernando Alonso-Fernandez, Kevin Hernandez-Diaz, Prayag Tiwari, Josef Bigun
We apply pre-trained architectures, originally developed for the ImageNet Large Scale Visual Recognition Challenge, for periocular recognition. These architectures have demonstrated significant success in various computer vision tasks beyond the ones for which they were designed. This work builds on our previous study using off-the-shelf Convolutional Neural Network (CNN) and extends it to include the more recently proposed Vision Transformers (ViT). Despite being trained for generic object classification, middle-layer features from CNNs and ViTs are a suitable way to recognize individuals based on periocular images. We also demonstrate that CNNs and ViTs are highly complementary since their combination results in boosted accuracy. In addition, we show that a small portion of these pre-trained models can achieve good accuracy, resulting in thinner models with fewer parameters, suitable for resource-limited environments such as mobiles. This efficiency improves if traditional handcrafted features are added as well.
Read more7/30/2024

0
Convolutional Neural Networks and Vision Transformers for Fashion MNIST Classification: A Literature Review
Sonia Bbouzidi, Ghazala Hcini, Imen Jdey, Fadoua Drira
Our review explores the comparative analysis between Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) in the domain of image classification, with a particular focus on clothing classification within the e-commerce sector. Utilizing the Fashion MNIST dataset, we delve into the unique attributes of CNNs and ViTs. While CNNs have long been the cornerstone of image classification, ViTs introduce an innovative self-attention mechanism enabling nuanced weighting of different input data components. Historically, transformers have primarily been associated with Natural Language Processing (NLP) tasks. Through a comprehensive examination of existing literature, our aim is to unveil the distinctions between ViTs and CNNs in the context of image classification. Our analysis meticulously scrutinizes state-of-the-art methodologies employing both architectures, striving to identify the factors influencing their performance. These factors encompass dataset characteristics, image dimensions, the number of target classes, hardware infrastructure, and the specific architectures along with their respective top results. Our key goal is to determine the most appropriate architecture between ViT and CNN for classifying images in the Fashion MNIST dataset within the e-commerce industry, while taking into account specific conditions and needs. We highlight the importance of combining these two architectures with different forms to enhance overall performance. By uniting these architectures, we can take advantage of their unique strengths, which may lead to more precise and reliable models for e-commerce applications. CNNs are skilled at recognizing local patterns, while ViTs are effective at grasping overall context, making their combination a promising strategy for boosting image classification performance.
Read more6/6/2024
0
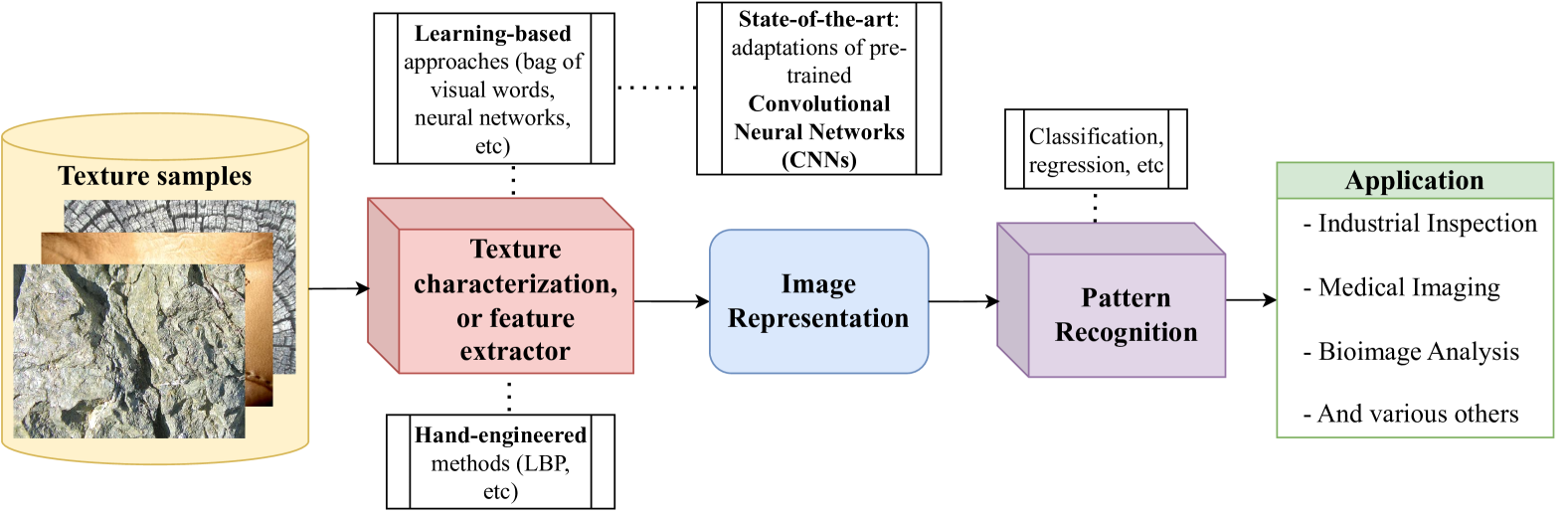
A Comparative Survey of Vision Transformers for Feature Extraction in Texture Analysis
Leonardo Scabini, Andre Sacilotti, Kallil M. Zielinski, Lucas C. Ribas, Bernard De Baets, Odemir M. Bruno
Texture, a significant visual attribute in images, has been extensively investigated across various image recognition applications. Convolutional Neural Networks (CNNs), which have been successful in many computer vision tasks, are currently among the best texture analysis approaches. On the other hand, Vision Transformers (ViTs) have been surpassing the performance of CNNs on tasks such as object recognition, causing a paradigm shift in the field. However, ViTs have so far not been scrutinized for texture recognition, hindering a proper appreciation of their potential in this specific setting. For this reason, this work explores various pre-trained ViT architectures when transferred to tasks that rely on textures. We review 21 different ViT variants and perform an extensive evaluation and comparison with CNNs and hand-engineered models on several tasks, such as assessing robustness to changes in texture rotation, scale, and illumination, and distinguishing color textures, material textures, and texture attributes. The goal is to understand the potential and differences among these models when directly applied to texture recognition, using pre-trained ViTs primarily for feature extraction and employing linear classifiers for evaluation. We also evaluate their efficiency, which is one of the main drawbacks in contrast to other methods. Our results show that ViTs generally outperform both CNNs and hand-engineered models, especially when using stronger pre-training and tasks involving in-the-wild textures (images from the internet). We highlight the following promising models: ViT-B with DINO pre-training, BeiTv2, and the Swin architecture, as well as the EfficientFormer as a low-cost alternative. In terms of efficiency, although having a higher number of GFLOPs and parameters, ViT-B and BeiT(v2) can achieve a lower feature extraction time on GPUs compared to ResNet50.
Read more6/11/2024
0
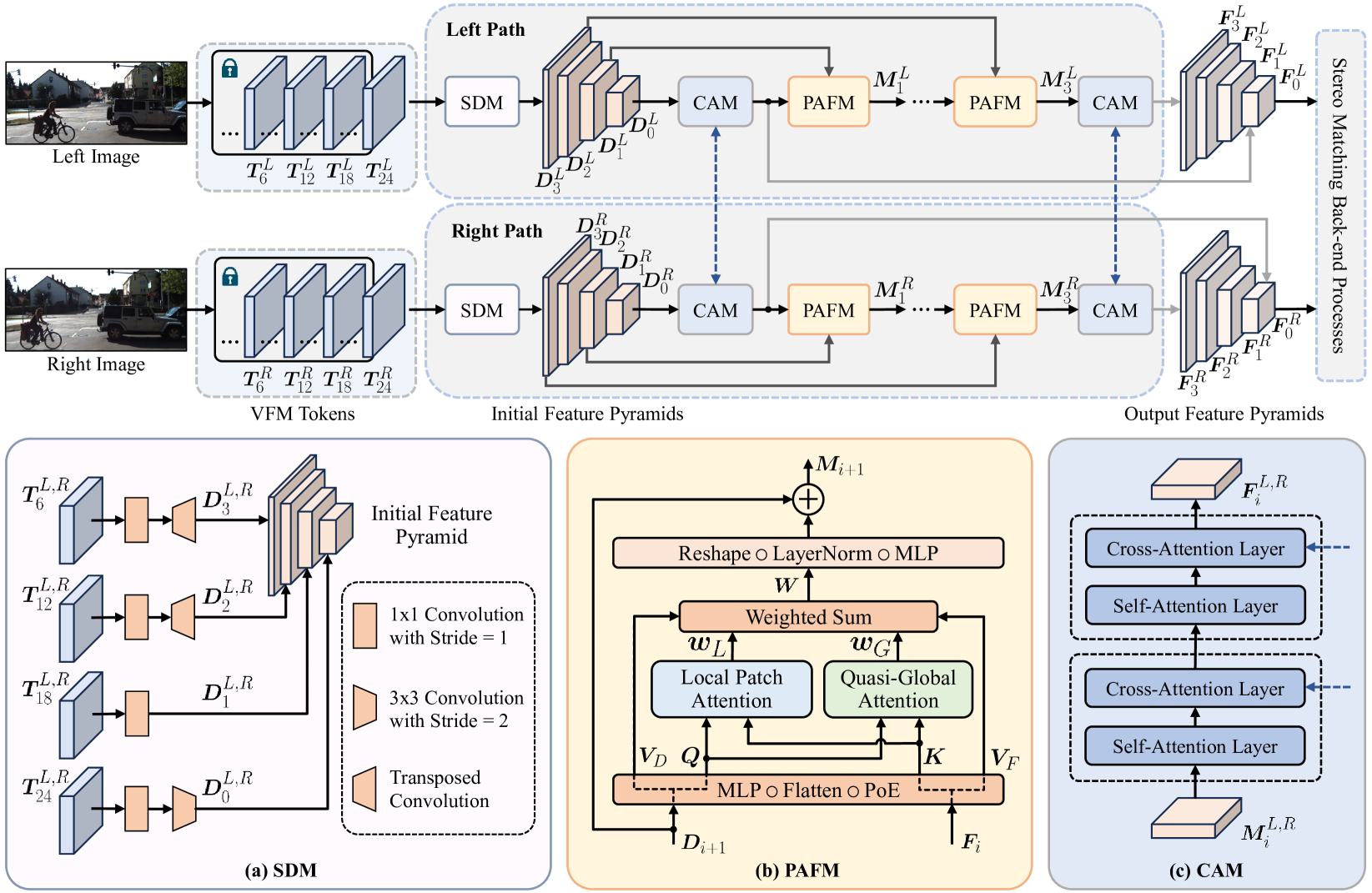
Playing to Vision Foundation Model's Strengths in Stereo Matching
Chuang-Wei Liu, Qijun Chen, Rui Fan
Stereo matching has become a key technique for 3D environment perception in intelligent vehicles. For a considerable time, convolutional neural networks (CNNs) have remained the mainstream choice for feature extraction in this domain. Nonetheless, there is a growing consensus that the existing paradigm should evolve towards vision foundation models (VFM), particularly those developed based on vision Transformers (ViTs) and pre-trained through self-supervision on extensive, unlabeled datasets. While VFMs are adept at extracting informative, general-purpose visual features, specifically for dense prediction tasks, their performance often lacks in geometric vision tasks. This study serves as the first exploration of a viable approach for adapting VFMs to stereo matching. Our ViT adapter, referred to as ViTAS, is constructed upon three types of modules: spatial differentiation, patch attention fusion, and cross-attention. The first module initializes feature pyramids, while the latter two aggregate stereo and multi-scale contextual information into fine-grained features, respectively. ViTAStereo, which combines ViTAS with cost volume-based stereo matching back-end processes, achieves the top rank on the KITTI Stereo 2012 dataset and outperforms the second-best network StereoBase by approximately 7.9% in terms of the percentage of error pixels, with a tolerance of 3 pixels. Additional experiments across diverse scenarios further demonstrate its superior generalizability compared to all other state-of-the-art approaches. We believe this new paradigm will pave the way for the next generation of stereo matching networks.
Read more4/10/2024