Convolutional Neural Networks and Vision Transformers for Fashion MNIST Classification: A Literature Review
2406.03478
0
0

Abstract
Our review explores the comparative analysis between Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) in the domain of image classification, with a particular focus on clothing classification within the e-commerce sector. Utilizing the Fashion MNIST dataset, we delve into the unique attributes of CNNs and ViTs. While CNNs have long been the cornerstone of image classification, ViTs introduce an innovative self-attention mechanism enabling nuanced weighting of different input data components. Historically, transformers have primarily been associated with Natural Language Processing (NLP) tasks. Through a comprehensive examination of existing literature, our aim is to unveil the distinctions between ViTs and CNNs in the context of image classification. Our analysis meticulously scrutinizes state-of-the-art methodologies employing both architectures, striving to identify the factors influencing their performance. These factors encompass dataset characteristics, image dimensions, the number of target classes, hardware infrastructure, and the specific architectures along with their respective top results. Our key goal is to determine the most appropriate architecture between ViT and CNN for classifying images in the Fashion MNIST dataset within the e-commerce industry, while taking into account specific conditions and needs. We highlight the importance of combining these two architectures with different forms to enhance overall performance. By uniting these architectures, we can take advantage of their unique strengths, which may lead to more precise and reliable models for e-commerce applications. CNNs are skilled at recognizing local patterns, while ViTs are effective at grasping overall context, making their combination a promising strategy for boosting image classification performance.
Create account to get full access
Overview
- This paper presents a literature review on the use of Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) for Fashion MNIST classification.
- It examines the performance of these two deep learning models in classifying fashion items like shirts, dresses, and shoes.
- The review covers the architectural differences between CNNs and ViTs, as well as their relative strengths and weaknesses for this specific task.
Plain English Explanation
In this paper, the researchers reviewed the existing literature on using two popular machine learning models, Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), to classify images of clothing items from the Fashion MNIST dataset. The Fashion MNIST dataset contains thousands of images of different clothing items, like shirts, dresses, and shoes, and the goal is to train a model to accurately identify what type of clothing is shown in each image.
CNNs are a type of neural network that are particularly good at processing and understanding visual information, like images. They work by breaking down an image into smaller parts and learning to recognize patterns in those parts. ViTs, on the other hand, are a newer type of model that use a technique called "self-attention" to understand the relationships between different parts of an image, without necessarily breaking it down into smaller pieces.
The researchers in this paper wanted to compare how well these two models perform on the Fashion MNIST classification task. They looked at studies that had used both CNNs and ViTs to tackle this problem, and examined the strengths and weaknesses of each approach. For example, they found that CNNs tend to be better at capturing low-level visual features, while ViTs may be better at understanding the higher-level relationships between different parts of the clothing items.
Overall, this review provides a comprehensive look at the state of the research on using deep learning models like CNNs and ViTs for clothing classification, and offers insights that could help guide future work in this area.
Technical Explanation
The paper examines the performance of Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) on the Fashion MNIST classification task. CNNs are a well-established type of deep learning model that excel at processing and understanding visual information, such as images. They work by breaking down an image into smaller, overlapping regions and learning to recognize patterns in those regions. In contrast, ViTs are a newer type of model that use a technique called "self-attention" to understand the relationships between different parts of an image, without necessarily breaking it down into smaller pieces.
The review covers several studies that have compared the performance of CNNs and ViTs on the Fashion MNIST dataset, which contains thousands of images of various clothing items like shirts, dresses, and shoes. The researchers found that both models generally perform well on this task, with some nuanced differences in their strengths and weaknesses. For example, link to "Comparative Study of CNN, ResNet, and Vision Transformers for Multi-Label Fashion Image Classification" suggests that CNNs tend to be better at capturing low-level visual features, while link to "A Timely Survey of Vision Transformer for DeepFake Detection" indicates that ViTs may be better at understanding the higher-level relationships between different parts of the clothing items.
The review also discusses the architectural differences between CNNs and ViTs, and how these differences may contribute to their relative strengths and weaknesses. For example, link to "Which Transformer to Favor? A Comparative Analysis of Efficiency and Performance" suggests that ViTs may be more computationally efficient than CNNs, while link to "Exploring Self-Supervised Vision Transformers for DeepFake Detection" highlights the potential of ViTs to learn more generalizable features from the data.
Critical Analysis
The paper provides a thorough and balanced review of the existing literature on the use of CNNs and ViTs for Fashion MNIST classification. However, it is worth noting that the review is limited to a specific task and dataset, and the insights may not necessarily generalize to other clothing classification problems or datasets.
Additionally, the review does not address some potential limitations or challenges of these models, such as their sensitivity to certain types of image transformations or their ability to handle real-world clothing data that may be more diverse and noisy than the Fashion MNIST dataset. link to "ViT-GAN: Training GANs with Vision Transformers" suggests that ViTs may struggle with generating realistic-looking clothing images, which could be a concern for certain applications.
Further research is needed to fully understand the strengths, weaknesses, and trade-offs of CNNs and ViTs for clothing classification tasks, particularly in more complex and diverse real-world scenarios. Incorporating additional datasets, benchmarks, and evaluation metrics could help provide a more comprehensive understanding of the performance and capabilities of these models.
Conclusion
This literature review provides a valuable overview of the current research on using Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) for Fashion MNIST classification. The paper highlights the key differences between these two deep learning models and their relative strengths and weaknesses for this specific task.
Overall, the review suggests that both CNNs and ViTs can achieve strong performance on the Fashion MNIST dataset, but with some nuanced differences in their approaches and capabilities. This information could be useful for researchers and practitioners working on clothing classification problems, as it can help guide the selection and development of appropriate deep learning models for their particular needs and applications.
While the review is limited to the Fashion MNIST dataset, the insights gained from this research can potentially inform the use of CNNs and ViTs for other clothing classification tasks and datasets, and contribute to the ongoing advancement of deep learning in the fashion and apparel industry.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
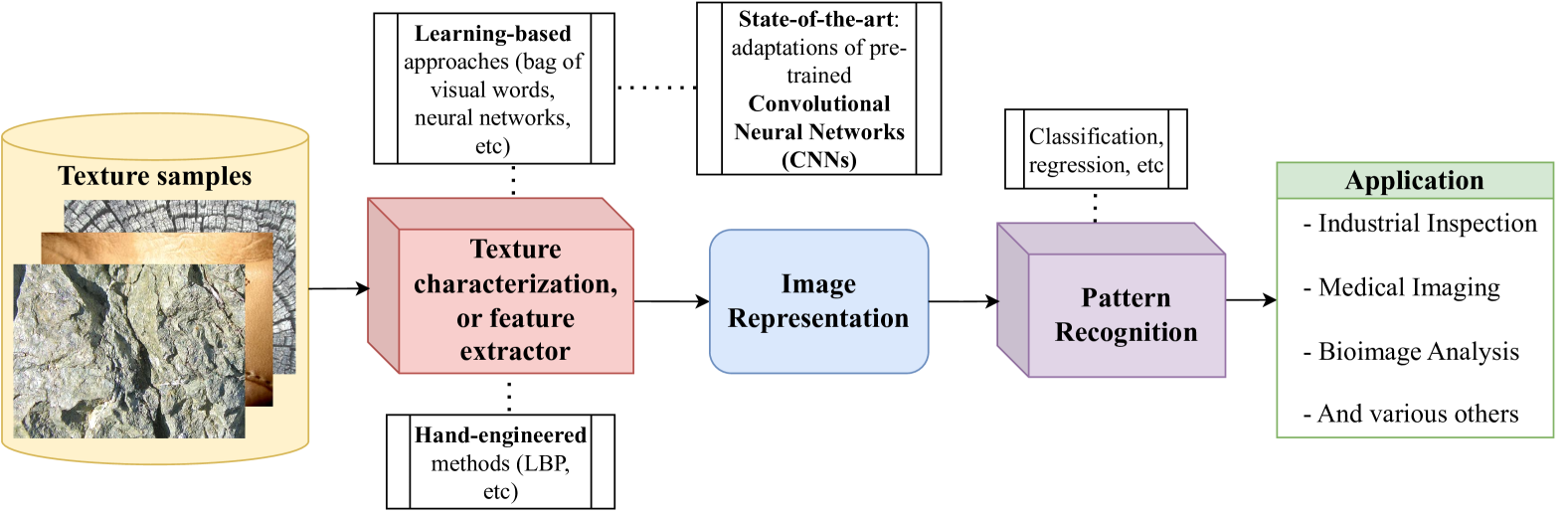
A Comparative Survey of Vision Transformers for Feature Extraction in Texture Analysis
Leonardo Scabini, Andre Sacilotti, Kallil M. Zielinski, Lucas C. Ribas, Bernard De Baets, Odemir M. Bruno
0
0
Texture, a significant visual attribute in images, has been extensively investigated across various image recognition applications. Convolutional Neural Networks (CNNs), which have been successful in many computer vision tasks, are currently among the best texture analysis approaches. On the other hand, Vision Transformers (ViTs) have been surpassing the performance of CNNs on tasks such as object recognition, causing a paradigm shift in the field. However, ViTs have so far not been scrutinized for texture recognition, hindering a proper appreciation of their potential in this specific setting. For this reason, this work explores various pre-trained ViT architectures when transferred to tasks that rely on textures. We review 21 different ViT variants and perform an extensive evaluation and comparison with CNNs and hand-engineered models on several tasks, such as assessing robustness to changes in texture rotation, scale, and illumination, and distinguishing color textures, material textures, and texture attributes. The goal is to understand the potential and differences among these models when directly applied to texture recognition, using pre-trained ViTs primarily for feature extraction and employing linear classifiers for evaluation. We also evaluate their efficiency, which is one of the main drawbacks in contrast to other methods. Our results show that ViTs generally outperform both CNNs and hand-engineered models, especially when using stronger pre-training and tasks involving in-the-wild textures (images from the internet). We highlight the following promising models: ViT-B with DINO pre-training, BeiTv2, and the Swin architecture, as well as the EfficientFormer as a low-cost alternative. In terms of efficiency, although having a higher number of GFLOPs and parameters, ViT-B and BeiT(v2) can achieve a lower feature extraction time on GPUs compared to ResNet50.
6/11/2024
🏋️
ViTGAN: Training GANs with Vision Transformers
Kwonjoon Lee, Huiwen Chang, Lu Jiang, Han Zhang, Zhuowen Tu, Ce Liu
0
0
Recently, Vision Transformers (ViTs) have shown competitive performance on image recognition while requiring less vision-specific inductive biases. In this paper, we investigate if such performance can be extended to image generation. To this end, we integrate the ViT architecture into generative adversarial networks (GANs). For ViT discriminators, we observe that existing regularization methods for GANs interact poorly with self-attention, causing serious instability during training. To resolve this issue, we introduce several novel regularization techniques for training GANs with ViTs. For ViT generators, we examine architectural choices for latent and pixel mapping layers to facilitate convergence. Empirically, our approach, named ViTGAN, achieves comparable performance to the leading CNN-based GAN models on three datasets: CIFAR-10, CelebA, and LSUN bedroom.
5/30/2024

A Comparative Study of CNN, ResNet, and Vision Transformers for Multi-Classification of Chest Diseases
Ananya Jain, Aviral Bhardwaj, Kaushik Murali, Isha Surani
0
0
Large language models, notably utilizing Transformer architectures, have emerged as powerful tools due to their scalability and ability to process large amounts of data. Dosovitskiy et al. expanded this architecture to introduce Vision Transformers (ViT), extending its applicability to image processing tasks. Motivated by this advancement, we fine-tuned two variants of ViT models, one pre-trained on ImageNet and another trained from scratch, using the NIH Chest X-ray dataset containing over 100,000 frontal-view X-ray images. Our study evaluates the performance of these models in the multi-label classification of 14 distinct diseases, while using Convolutional Neural Networks (CNNs) and ResNet architectures as baseline models for comparison. Through rigorous assessment based on accuracy metrics, we identify that the pre-trained ViT model surpasses CNNs and ResNet in this multilabel classification task, highlighting its potential for accurate diagnosis of various lung conditions from chest X-ray images.
6/4/2024
👀
A Timely Survey on Vision Transformer for Deepfake Detection
Zhikan Wang, Zhongyao Cheng, Jiajie Xiong, Xun Xu, Tianrui Li, Bharadwaj Veeravalli, Xulei Yang
0
0
In recent years, the rapid advancement of deepfake technology has revolutionized content creation, lowering forgery costs while elevating quality. However, this progress brings forth pressing concerns such as infringements on individual rights, national security threats, and risks to public safety. To counter these challenges, various detection methodologies have emerged, with Vision Transformer (ViT)-based approaches showcasing superior performance in generality and efficiency. This survey presents a timely overview of ViT-based deepfake detection models, categorized into standalone, sequential, and parallel architectures. Furthermore, it succinctly delineates the structure and characteristics of each model. By analyzing existing research and addressing future directions, this survey aims to equip researchers with a nuanced understanding of ViT's pivotal role in deepfake detection, serving as a valuable reference for both academic and practical pursuits in this domain.
5/15/2024