A Comparative Survey of Vision Transformers for Feature Extraction in Texture Analysis

0
Sign in to get full access
Overview
- This paper compares the performance of various Vision Transformer (ViT) models for feature extraction in texture analysis tasks.
- Vision Transformers are a type of deep learning model that uses self-attention mechanisms to learn visual representations, in contrast to traditional convolutional neural networks (CNNs).
- The authors evaluate the effectiveness of different ViT architectures, including ViTGAN, Exploring Self-Supervised ViTs for DeepFake Detection, and Which Transformer to Favor?, on texture classification and segmentation benchmarks.
Plain English Explanation
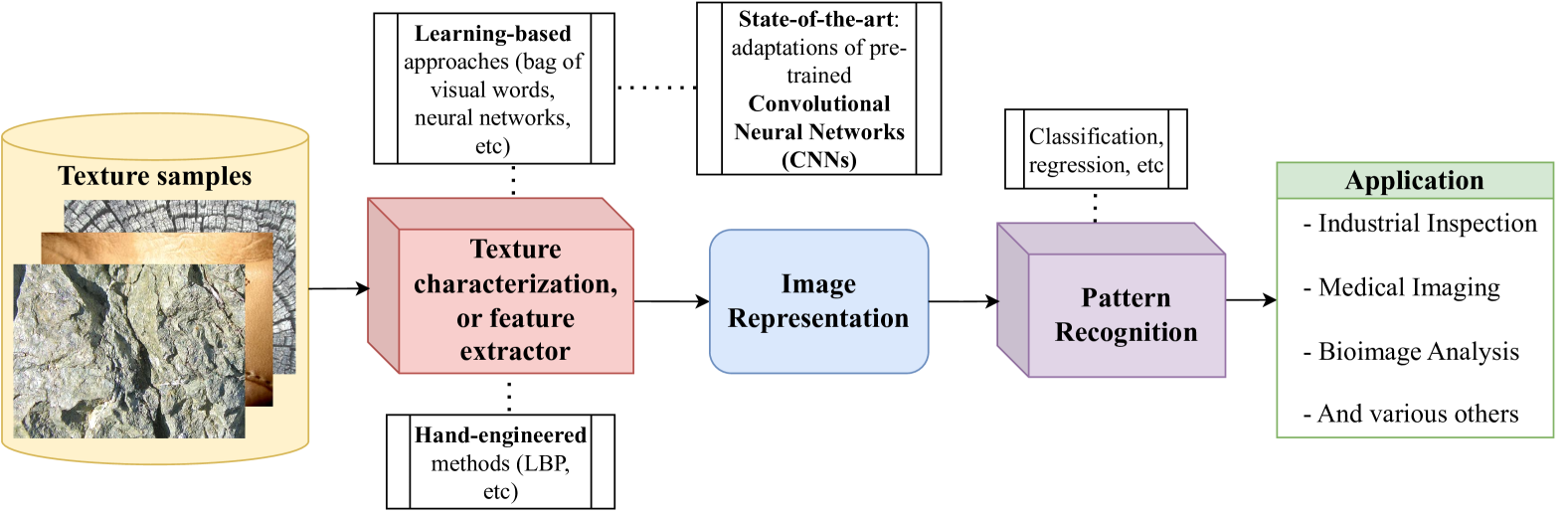
The paper explores the use of Vision Transformers (ViTs) for extracting visual features from texture data, which is important for applications like image recognition and scene understanding. ViTs are a newer type of deep learning model that works differently than the more common convolutional neural networks (CNNs).
Instead of using convolutional layers to extract local features, ViTs use self-attention mechanisms to learn global relationships in the image data. The authors compare the performance of different ViT architectures, including some specialized versions like ViTGAN and Exploring Self-Supervised ViTs for DeepFake Detection, on standard texture classification and segmentation benchmark tasks.
The goal is to understand which ViT models are most effective for extracting useful features from texture data, which could help improve computer vision systems in areas like image analysis and object recognition.
Technical Explanation
The paper evaluates the performance of several Vision Transformer (ViT) architectures for feature extraction in texture analysis tasks. ViTs are a class of deep learning models that use self-attention mechanisms to learn visual representations, in contrast to the convolutional layers used in traditional convolutional neural networks (CNNs).
The authors compare the effectiveness of different ViT models, including ViTGAN, Exploring Self-Supervised ViTs for DeepFake Detection, and Which Transformer to Favor?, on texture classification and segmentation benchmarks. They evaluate the models' ability to extract discriminative features from the texture data that can be used for downstream tasks.
The experiments demonstrate the strengths and weaknesses of the various ViT architectures compared to CNNs for texture analysis. The results provide insights into which ViT models are most effective for learning useful visual representations from texture data.
Critical Analysis
The paper provides a comprehensive evaluation of ViT models for texture analysis, but there are a few potential limitations and areas for further research:
- The experiments are limited to a relatively small set of texture datasets, so the results may not generalize to all types of texture data.
- The authors do not explore the impact of different pretraining strategies or fine-tuning approaches, which could further improve the ViT models' performance.
- There is no discussion of the computational efficiency or inference speed of the ViT models, which are important practical considerations for many real-world applications.
Overall, the paper makes a valuable contribution by systematically comparing the feature extraction capabilities of ViT architectures for texture analysis tasks. However, further research is needed to fully understand the strengths and weaknesses of ViTs compared to CNNs and to optimize their performance for a wider range of texture-based applications.
Conclusion
This paper presents a comparative study of Vision Transformer (ViT) models for feature extraction in texture analysis. The authors evaluate the performance of various ViT architectures, including specialized versions like ViTGAN and Exploring Self-Supervised ViTs for DeepFake Detection, on texture classification and segmentation benchmarks.
The results provide insights into the strengths and limitations of ViTs for learning useful visual representations from texture data, which is an important capability for a range of computer vision applications. While the paper offers a comprehensive evaluation, further research is needed to fully understand the practical tradeoffs of ViTs compared to convolutional neural networks and to explore ways to optimize their performance for texture-based tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Comparative Survey of Vision Transformers for Feature Extraction in Texture Analysis
Leonardo Scabini, Andre Sacilotti, Kallil M. Zielinski, Lucas C. Ribas, Bernard De Baets, Odemir M. Bruno
Texture, a significant visual attribute in images, has been extensively investigated across various image recognition applications. Convolutional Neural Networks (CNNs), which have been successful in many computer vision tasks, are currently among the best texture analysis approaches. On the other hand, Vision Transformers (ViTs) have been surpassing the performance of CNNs on tasks such as object recognition, causing a paradigm shift in the field. However, ViTs have so far not been scrutinized for texture recognition, hindering a proper appreciation of their potential in this specific setting. For this reason, this work explores various pre-trained ViT architectures when transferred to tasks that rely on textures. We review 21 different ViT variants and perform an extensive evaluation and comparison with CNNs and hand-engineered models on several tasks, such as assessing robustness to changes in texture rotation, scale, and illumination, and distinguishing color textures, material textures, and texture attributes. The goal is to understand the potential and differences among these models when directly applied to texture recognition, using pre-trained ViTs primarily for feature extraction and employing linear classifiers for evaluation. We also evaluate their efficiency, which is one of the main drawbacks in contrast to other methods. Our results show that ViTs generally outperform both CNNs and hand-engineered models, especially when using stronger pre-training and tasks involving in-the-wild textures (images from the internet). We highlight the following promising models: ViT-B with DINO pre-training, BeiTv2, and the Swin architecture, as well as the EfficientFormer as a low-cost alternative. In terms of efficiency, although having a higher number of GFLOPs and parameters, ViT-B and BeiT(v2) can achieve a lower feature extraction time on GPUs compared to ResNet50.
Read more6/11/2024

0
Convolutional Neural Networks and Vision Transformers for Fashion MNIST Classification: A Literature Review
Sonia Bbouzidi, Ghazala Hcini, Imen Jdey, Fadoua Drira
Our review explores the comparative analysis between Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) in the domain of image classification, with a particular focus on clothing classification within the e-commerce sector. Utilizing the Fashion MNIST dataset, we delve into the unique attributes of CNNs and ViTs. While CNNs have long been the cornerstone of image classification, ViTs introduce an innovative self-attention mechanism enabling nuanced weighting of different input data components. Historically, transformers have primarily been associated with Natural Language Processing (NLP) tasks. Through a comprehensive examination of existing literature, our aim is to unveil the distinctions between ViTs and CNNs in the context of image classification. Our analysis meticulously scrutinizes state-of-the-art methodologies employing both architectures, striving to identify the factors influencing their performance. These factors encompass dataset characteristics, image dimensions, the number of target classes, hardware infrastructure, and the specific architectures along with their respective top results. Our key goal is to determine the most appropriate architecture between ViT and CNN for classifying images in the Fashion MNIST dataset within the e-commerce industry, while taking into account specific conditions and needs. We highlight the importance of combining these two architectures with different forms to enhance overall performance. By uniting these architectures, we can take advantage of their unique strengths, which may lead to more precise and reliable models for e-commerce applications. CNNs are skilled at recognizing local patterns, while ViTs are effective at grasping overall context, making their combination a promising strategy for boosting image classification performance.
Read more6/6/2024
🔮
0
Tex-ViT: A Generalizable, Robust, Texture-based dual-branch cross-attention deepfake detector
Deepak Dagar, Dinesh Kumar Vishwakarma
Deepfakes, which employ GAN to produce highly realistic facial modification, are widely regarded as the prevailing method. Traditional CNN have been able to identify bogus media, but they struggle to perform well on different datasets and are vulnerable to adversarial attacks due to their lack of robustness. Vision transformers have demonstrated potential in the realm of image classification problems, but they require enough training data. Motivated by these limitations, this publication introduces Tex-ViT (Texture-Vision Transformer), which enhances CNN features by combining ResNet with a vision transformer. The model combines traditional ResNet features with a texture module that operates in parallel on sections of ResNet before each down-sampling operation. The texture module then serves as an input to the dual branch of the cross-attention vision transformer. It specifically focuses on improving the global texture module, which extracts feature map correlation. Empirical analysis reveals that fake images exhibit smooth textures that do not remain consistent over long distances in manipulations. Experiments were performed on different categories of FF++, such as DF, f2f, FS, and NT, together with other types of GAN datasets in cross-domain scenarios. Furthermore, experiments also conducted on FF++, DFDCPreview, and Celeb-DF dataset underwent several post-processing situations, such as blurring, compression, and noise. The model surpassed the most advanced models in terms of generalization, achieving a 98% accuracy in cross-domain scenarios. This demonstrates its ability to learn the shared distinguishing textural characteristics in the manipulated samples. These experiments provide evidence that the proposed model is capable of being applied to various situations and is resistant to many post-processing procedures.
Read more9/2/2024

0
Combined CNN and ViT features off-the-shelf: Another astounding baseline for recognition
Fernando Alonso-Fernandez, Kevin Hernandez-Diaz, Prayag Tiwari, Josef Bigun
We apply pre-trained architectures, originally developed for the ImageNet Large Scale Visual Recognition Challenge, for periocular recognition. These architectures have demonstrated significant success in various computer vision tasks beyond the ones for which they were designed. This work builds on our previous study using off-the-shelf Convolutional Neural Network (CNN) and extends it to include the more recently proposed Vision Transformers (ViT). Despite being trained for generic object classification, middle-layer features from CNNs and ViTs are a suitable way to recognize individuals based on periocular images. We also demonstrate that CNNs and ViTs are highly complementary since their combination results in boosted accuracy. In addition, we show that a small portion of these pre-trained models can achieve good accuracy, resulting in thinner models with fewer parameters, suitable for resource-limited environments such as mobiles. This efficiency improves if traditional handcrafted features are added as well.
Read more7/30/2024