The Common Intuition to Transfer Learning Can Win or Lose: Case Studies for Linear Regression

0
🔄
Sign in to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
The Common Intuition to Transfer Learning Can Win or Lose: Case Studies for Linear Regression
Yehuda Dar, Daniel LeJeune, Richard G. Baraniuk
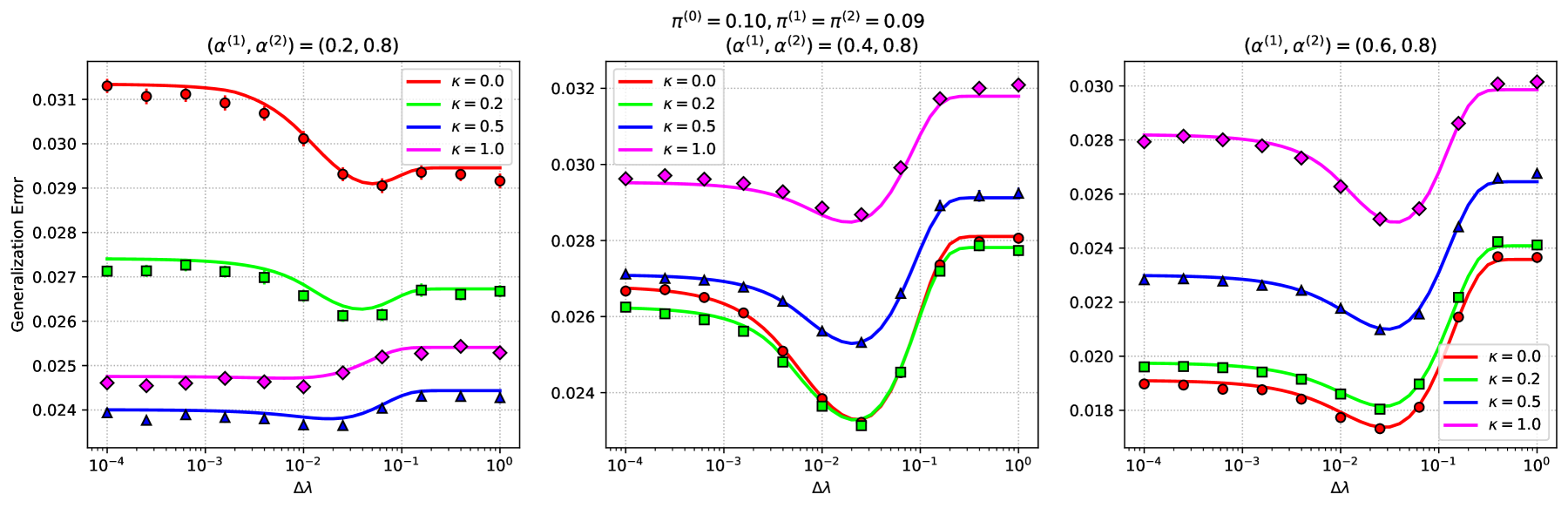
We study a fundamental transfer learning process from source to target linear regression tasks, including overparameterized settings where there are more learned parameters than data samples. The target task learning is addressed by using its training data together with the parameters previously computed for the source task. We define a transfer learning approach to the target task as a linear regression optimization with a regularization on the distance between the to-be-learned target parameters and the already-learned source parameters. We analytically characterize the generalization performance of our transfer learning approach and demonstrate its ability to resolve the peak in generalization errors in double descent phenomena of the minimum L2-norm solution to linear regression. Moreover, we show that for sufficiently related tasks, the optimally tuned transfer learning approach can outperform the optimally tuned ridge regression method, even when the true parameter vector conforms to an isotropic Gaussian prior distribution. Namely, we demonstrate that transfer learning can beat the minimum mean square error (MMSE) solution of the independent target task. Our results emphasize the ability of transfer learning to extend the solution space to the target task and, by that, to have an improved MMSE solution. We formulate the linear MMSE solution to our transfer learning setting and point out its key differences from the common design philosophy to transfer learning.
Read more6/3/2024
0
Minimum-Norm Interpolation Under Covariate Shift
Neil Mallinar, Austin Zane, Spencer Frei, Bin Yu
Transfer learning is a critical part of real-world machine learning deployments and has been extensively studied in experimental works with overparameterized neural networks. However, even in the simplest setting of linear regression a notable gap still exists in the theoretical understanding of transfer learning. In-distribution research on high-dimensional linear regression has led to the identification of a phenomenon known as textit{benign overfitting}, in which linear interpolators overfit to noisy training labels and yet still generalize well. This behavior occurs under specific conditions on the source covariance matrix and input data dimension. Therefore, it is natural to wonder how such high-dimensional linear models behave under transfer learning. We prove the first non-asymptotic excess risk bounds for benignly-overfit linear interpolators in the transfer learning setting. From our analysis, we propose a taxonomy of textit{beneficial} and textit{malignant} covariate shifts based on the degree of overparameterization. We follow our analysis with empirical studies that show these beneficial and malignant covariate shifts for linear interpolators on real image data, and for fully-connected neural networks in settings where the input data dimension is larger than the training sample size.
Read more7/18/2024
0
New!Transfer Learning in $ell_1$ Regularized Regression: Hyperparameter Selection Strategy based on Sharp Asymptotic Analysis
Koki Okajima, Tomoyuki Obuchi
Transfer learning techniques aim to leverage information from multiple related datasets to enhance prediction quality against a target dataset. Such methods have been adopted in the context of high-dimensional sparse regression, and some Lasso-based algorithms have been invented: Trans-Lasso and Pretraining Lasso are such examples. These algorithms require the statistician to select hyperparameters that control the extent and type of information transfer from related datasets. However, selection strategies for these hyperparameters, as well as the impact of these choices on the algorithm's performance, have been largely unexplored. To address this, we conduct a thorough, precise study of the algorithm in a high-dimensional setting via an asymptotic analysis using the replica method. Our approach reveals a surprisingly simple behavior of the algorithm: Ignoring one of the two types of information transferred to the fine-tuning stage has little effect on generalization performance, implying that efforts for hyperparameter selection can be significantly reduced. Our theoretical findings are also empirically supported by real-world applications on the IMDb dataset.
Read more9/27/2024
0
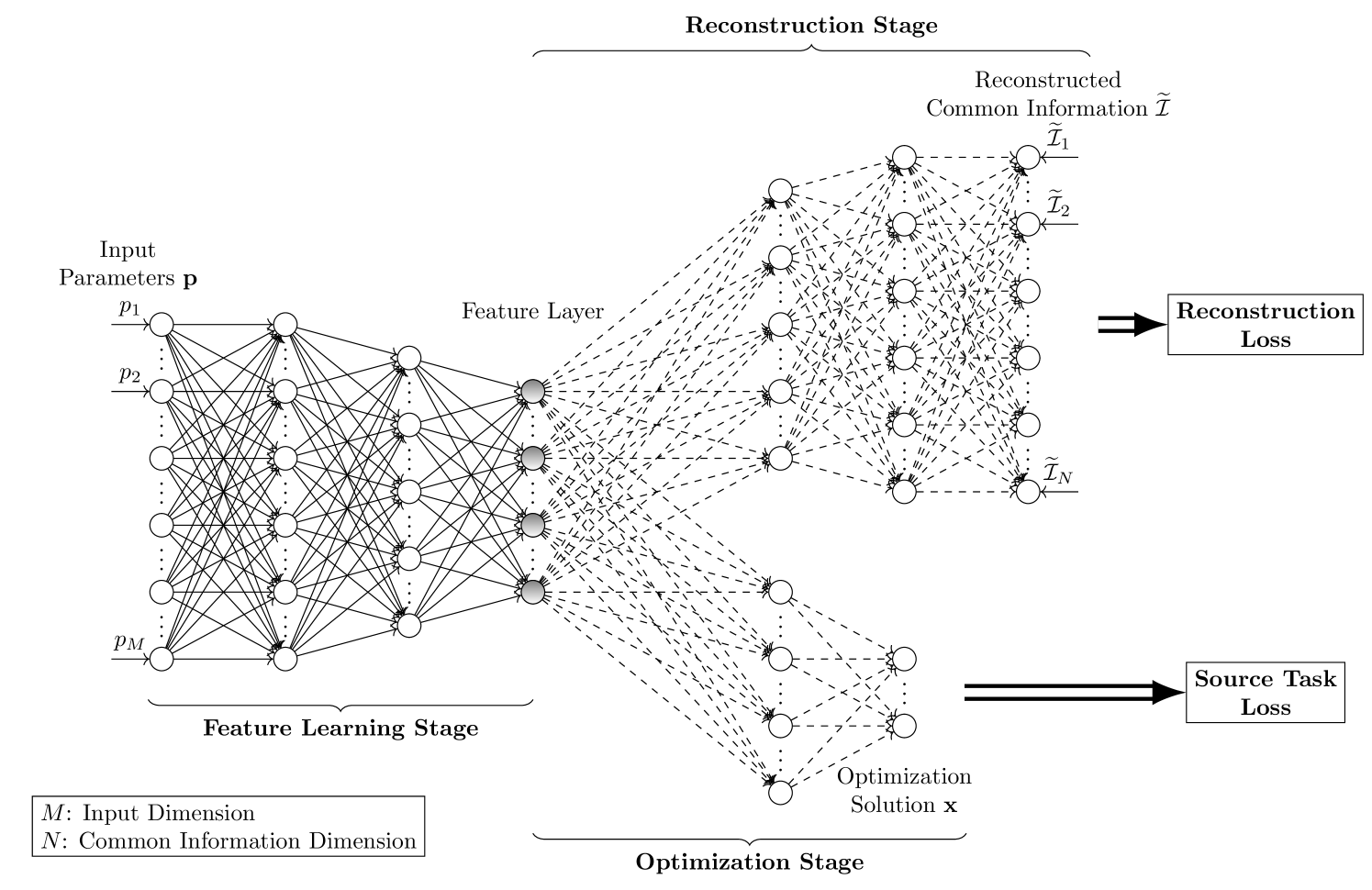
Transfer Learning with Reconstruction Loss
Wei Cui, Wei Yu
In most applications of utilizing neural networks for mathematical optimization, a dedicated model is trained for each specific optimization objective. However, in many scenarios, several distinct yet correlated objectives or tasks often need to be optimized on the same set of problem inputs. Instead of independently training a different neural network for each problem separately, it would be more efficient to exploit the correlations between these objectives and to train multiple neural network models with shared model parameters and feature representations. To achieve this, this paper first establishes the concept of common information: the shared knowledge required for solving the correlated tasks, then proposes a novel approach for model training by adding into the model an additional reconstruction stage associated with a new reconstruction loss. This loss is for reconstructing the common information starting from a selected hidden layer in the model. The proposed approach encourages the learned features to be general and transferable, and therefore can be readily used for efficient transfer learning. For numerical simulations, three applications are studied: transfer learning on classifying MNIST handwritten digits, the device-to-device wireless network power allocation, and the multiple-input-single-output network downlink beamforming and localization. Simulation results suggest that the proposed approach is highly efficient in data and model complexity, is resilient to over-fitting, and has competitive performances.
Read more4/15/2024