Transfer Learning with Reconstruction Loss

0
Sign in to get full access
Overview
- This paper explores a transfer learning approach that uses reconstruction loss to improve model performance.
- The authors propose a method for transferring learned features from a pre-trained model to a new task, using the reconstruction loss as an auxiliary objective.
- Experiments are conducted on wireless communication and image classification tasks to demonstrate the effectiveness of the proposed approach.
Plain English Explanation
The paper is about a technique called transfer learning that allows machine learning models to reuse knowledge gained from one task and apply it to a different but related task. The key idea is to take a model that has been trained on a large dataset, like images, and then use that model as a starting point for training on a new, smaller dataset, like medical images. This can help the new model learn more efficiently and perform better than if it had been trained from scratch.
In this paper, the researchers propose a specific way to do transfer learning using something called "reconstruction loss." Reconstruction loss is a measure of how well the model can recreate the input data, like an image, from the features it has learned. By adding reconstruction loss as an additional objective during training, along with the main task the model is trying to learn, the researchers found that the transferred features were more useful for the new task.
They tested this approach on two different problems: wireless communication and image classification. In both cases, they showed that using reconstruction loss during transfer learning improved the model's performance compared to standard transfer learning techniques. This suggests that reconstruction loss can be a powerful tool for making the most of pre-trained models and accelerating the learning process for new tasks.
Technical Explanation
The authors propose a transfer learning approach that uses reconstruction loss as an auxiliary objective during fine-tuning. The key idea is to leverage the feature representations learned by a pre-trained model and further refine them using reconstruction loss, in addition to the main task loss.
Specifically, the method works as follows:
- Train a base model on a large dataset (e.g. ImageNet) to learn general feature representations.
- For a new target task, freeze the lower layers of the base model and add new task-specific layers on top.
- During fine-tuning, optimize the model not only for the target task loss, but also for the reconstruction loss between the input and the model's reconstruction of the input.
The authors hypothesize that incorporating reconstruction loss encourages the model to learn more versatile and transferable feature representations, as it has to capture the underlying structure of the input data in addition to performing well on the target task.
Experiments on wireless communication and image classification tasks demonstrate the effectiveness of the proposed approach. Compared to standard fine-tuning, the transfer learning method with reconstruction loss consistently achieves superior performance, indicating that the learned features are more generalizable and useful for the new tasks.
The authors also provide analysis and visualization to show how the reconstruction loss shapes the learned representations, leading to better transfer performance.
Critical Analysis
The paper presents a compelling approach for improving transfer learning using reconstruction loss as an auxiliary objective. The experimental results are convincing and suggest that this technique could be broadly applicable across different domains.
One potential limitation is that the method requires training the base model on a large dataset first, which may not always be feasible. An interesting avenue for future work could be to explore how this approach performs when the base model is trained on a smaller dataset or even generated synthetically.
Additionally, the paper does not deeply explore the trade-offs between the target task loss and the reconstruction loss during fine-tuning. It would be valuable to understand how to best balance these competing objectives, as well as the sensitivity of the results to hyperparameter choices.
Finally, while the authors provide some analysis of the learned representations, a more detailed investigation into what types of features the reconstruction loss encourages the model to learn could yield additional insights. Comparing these features to those learned by standard fine-tuning could further elucidate the advantages of the proposed method.
Overall, this work makes a strong contribution to the field of transfer learning and feature learning, and the ideas presented warrant further exploration and refinement.
Conclusion
This paper introduces a novel transfer learning approach that leverages reconstruction loss as an auxiliary objective during fine-tuning. The key insight is that encouraging the model to learn generalizable feature representations, not just optimize for the target task, can lead to improved transfer learning performance.
The experimental results on wireless communication and image classification tasks demonstrate the effectiveness of this approach, suggesting that it could be a valuable tool for accelerating learning on new problems by building upon pre-trained models. The work also contributes to the broader understanding of feature learning and how to shape the learned representations to be more transferable.
While the paper leaves room for further exploration of the method's limitations and fine-tuning dynamics, it represents an important step forward in the field of transfer learning and has the potential to impact a wide range of applications that can benefit from effectively reusing and adapting pre-existing knowledge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Transfer Learning with Reconstruction Loss
Wei Cui, Wei Yu
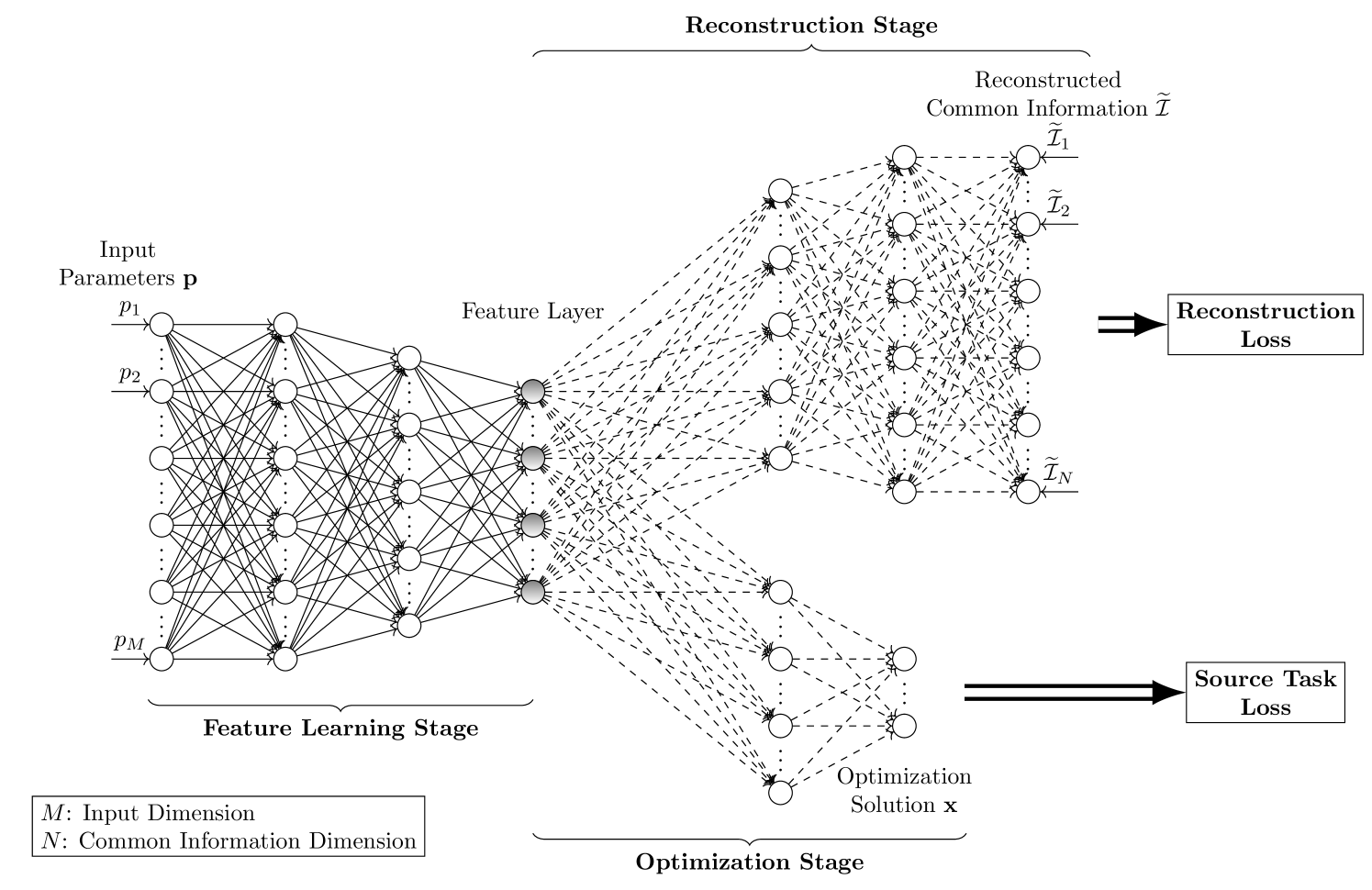
In most applications of utilizing neural networks for mathematical optimization, a dedicated model is trained for each specific optimization objective. However, in many scenarios, several distinct yet correlated objectives or tasks often need to be optimized on the same set of problem inputs. Instead of independently training a different neural network for each problem separately, it would be more efficient to exploit the correlations between these objectives and to train multiple neural network models with shared model parameters and feature representations. To achieve this, this paper first establishes the concept of common information: the shared knowledge required for solving the correlated tasks, then proposes a novel approach for model training by adding into the model an additional reconstruction stage associated with a new reconstruction loss. This loss is for reconstructing the common information starting from a selected hidden layer in the model. The proposed approach encourages the learned features to be general and transferable, and therefore can be readily used for efficient transfer learning. For numerical simulations, three applications are studied: transfer learning on classifying MNIST handwritten digits, the device-to-device wireless network power allocation, and the multiple-input-single-output network downlink beamforming and localization. Simulation results suggest that the proposed approach is highly efficient in data and model complexity, is resilient to over-fitting, and has competitive performances.
Read more4/15/2024
🔄
0
The Common Intuition to Transfer Learning Can Win or Lose: Case Studies for Linear Regression
Yehuda Dar, Daniel LeJeune, Richard G. Baraniuk
We study a fundamental transfer learning process from source to target linear regression tasks, including overparameterized settings where there are more learned parameters than data samples. The target task learning is addressed by using its training data together with the parameters previously computed for the source task. We define a transfer learning approach to the target task as a linear regression optimization with a regularization on the distance between the to-be-learned target parameters and the already-learned source parameters. We analytically characterize the generalization performance of our transfer learning approach and demonstrate its ability to resolve the peak in generalization errors in double descent phenomena of the minimum L2-norm solution to linear regression. Moreover, we show that for sufficiently related tasks, the optimally tuned transfer learning approach can outperform the optimally tuned ridge regression method, even when the true parameter vector conforms to an isotropic Gaussian prior distribution. Namely, we demonstrate that transfer learning can beat the minimum mean square error (MMSE) solution of the independent target task. Our results emphasize the ability of transfer learning to extend the solution space to the target task and, by that, to have an improved MMSE solution. We formulate the linear MMSE solution to our transfer learning setting and point out its key differences from the common design philosophy to transfer learning.
Read more6/3/2024

0
Reconstructing Training Data From Real World Models Trained with Transfer Learning
Yakir Oz, Gilad Yehudai, Gal Vardi, Itai Antebi, Michal Irani, Niv Haim
Current methods for reconstructing training data from trained classifiers are restricted to very small models, limited training set sizes, and low-resolution images. Such restrictions hinder their applicability to real-world scenarios. In this paper, we present a novel approach enabling data reconstruction in realistic settings for models trained on high-resolution images. Our method adapts the reconstruction scheme of arXiv:2206.07758 to real-world scenarios -- specifically, targeting models trained via transfer learning over image embeddings of large pre-trained models like DINO-ViT and CLIP. Our work employs data reconstruction in the embedding space rather than in the image space, showcasing its applicability beyond visual data. Moreover, we introduce a novel clustering-based method to identify good reconstructions from thousands of candidates. This significantly improves on previous works that relied on knowledge of the training set to identify good reconstructed images. Our findings shed light on a potential privacy risk for data leakage from models trained using transfer learning.
Read more7/23/2024
0
Opening the Black Box: predicting the trainability of deep neural networks with reconstruction entropy
Yanick Thurn, Ro Jefferson, Johanna Erdmenger
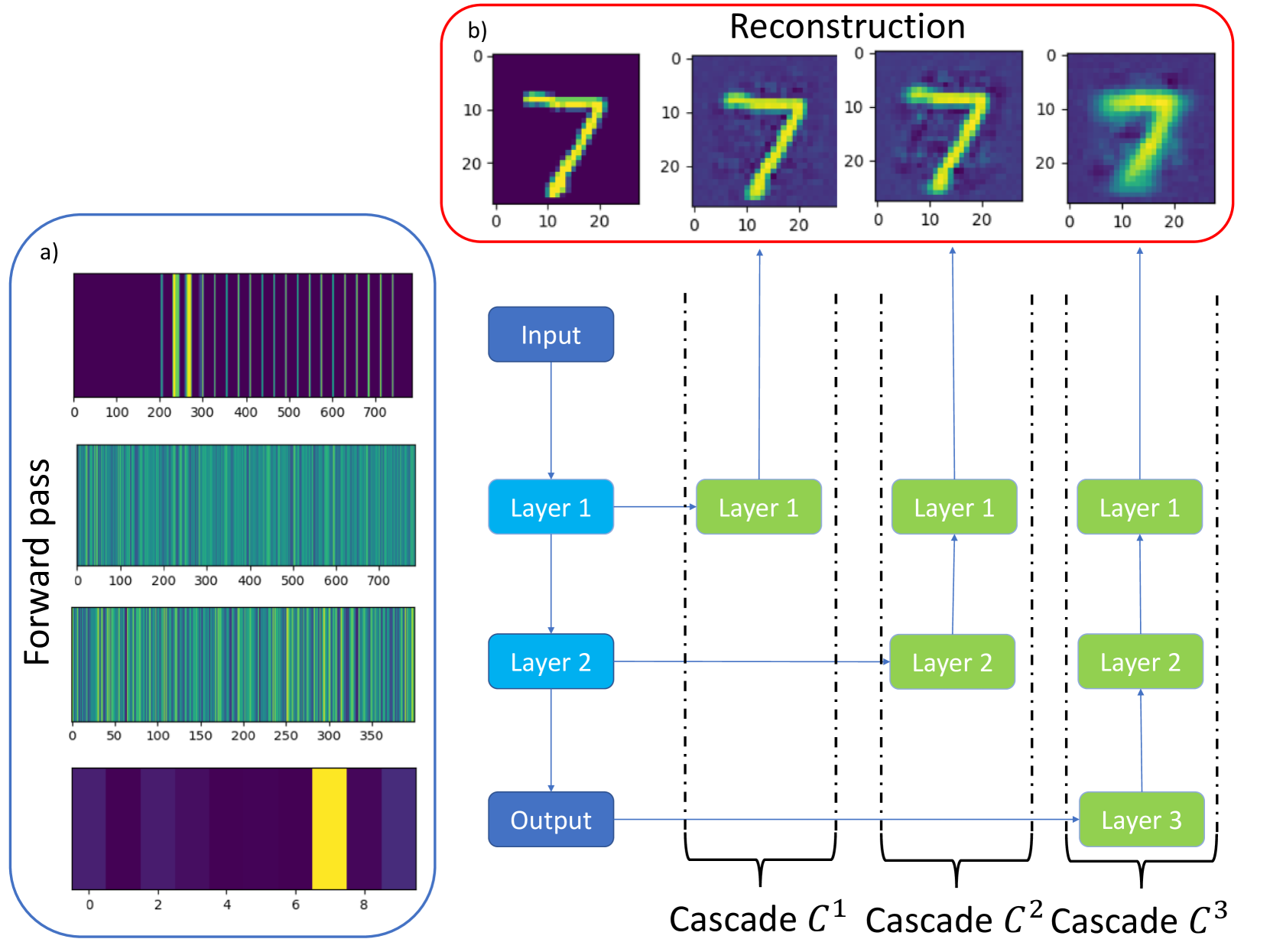
An important challenge in machine learning is to predict the initial conditions under which a given neural network will be trainable. We present a method for predicting the trainable regime in parameter space for deep feedforward neural networks, based on reconstructing the input from subsequent activation layers via a cascade of single-layer auxiliary networks. For both the MNIST and CIFAR10 datasets, we show that a single epoch of training of the shallow cascade networks is sufficient to predict the trainability of the deep feedforward network, thereby providing a significant reduction in overall training time. We achieve this by computing the relative entropy between reconstructed images and the original inputs, and show that this probe of information loss is sensitive to the phase behaviour of the network. Moreover, our approach illustrates the network's decision making process by displaying the changes performed on the input data at each layer. Our results provide a concrete link between the flow of information and the trainability of deep neural networks, further explaining the role of criticality in these systems.
Read more8/12/2024