Efficient Model Compression for Hierarchical Federated Learning

0
Sign in to get full access
Overview
- Hierarchical federated learning is a machine learning approach that trains models across multiple decentralized devices while preserving data privacy.
- This paper proposes an efficient model compression technique for hierarchical federated learning to reduce communication costs and computation latency.
- The method uses an adaptive clustering algorithm to group similar model parameters, allowing for selective compression and transmission of only the most important updates.
Plain English Explanation
In hierarchical federated learning, machine learning models are trained across many different devices, like smartphones or computers, without the data from those devices ever leaving the device. This helps protect people's privacy. However, all that back-and-forth communication between the devices can take a lot of time and use a lot of network bandwidth.
This paper introduces a new technique to make hierarchical federated learning more efficient. It uses a smart algorithm to figure out which parts of the machine learning model are most important, and only sends those parts back and forth between the devices. This reduces the amount of communication needed, saving time and bandwidth.
The key idea is to group similar parts of the model together using an adaptive clustering technique. That way, the system can focus on transmitting the most critical updates, while leaving out the less important parts. This makes the whole process faster and more efficient, without sacrificing the model's accuracy.
Technical Explanation
The paper proposes an efficient model compression technique for hierarchical federated learning. The method uses an adaptive clustering algorithm to group similar model parameters, allowing for selective compression and transmission of only the most important updates.
This reduces the communication costs and computation latency associated with the typical federated learning approach, where all model updates are sent back to the central server.
The authors first divide the neural network model into multiple layers. They then apply the adaptive clustering algorithm to group similar parameters within each layer. This allows them to identify the most important parameters that need to be transmitted, while compressing the less critical ones.
The selective transmission of model updates is achieved through a two-stage process:
- Intra-layer compression: Similar parameters within each layer are grouped and compressed using a lightweight coding scheme.
- Inter-layer compression: The compressed parameter updates from each layer are further compressed based on their relative importance, determined by the adaptive clustering.
The authors evaluate their approach on various datasets and model architectures, demonstrating significant reductions in communication cost and computation time compared to baseline federated learning methods, with minimal impact on model accuracy.
Critical Analysis
The paper presents a novel and effective solution to the communication and latency challenges in hierarchical federated learning. The adaptive clustering approach is a clever way to identify the most important model updates to transmit, without sacrificing the model's performance.
However, the paper does not address potential membership inference attacks that can occur in federated learning settings. Additionally, the distribution of data across devices is not considered, which can also impact the effectiveness of the compression technique.
Further research could explore ways to combine this model compression approach with other techniques to enhance the overall security and efficiency of hierarchical federated learning systems.
Conclusion
This paper presents an efficient model compression technique for hierarchical federated learning that uses adaptive clustering to identify and transmit only the most important model updates. This approach significantly reduces the communication costs and computation latency associated with traditional federated learning, while maintaining model accuracy.
The key innovation is the ability to selectively compress and transmit model updates based on their relative importance, without compromising the overall model performance. This makes hierarchical federated learning more practical and scalable for real-world applications that require low latency and efficient use of network resources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient Model Compression for Hierarchical Federated Learning
Xi Zhu, Songcan Yu, Junbo Wang, Qinglin Yang
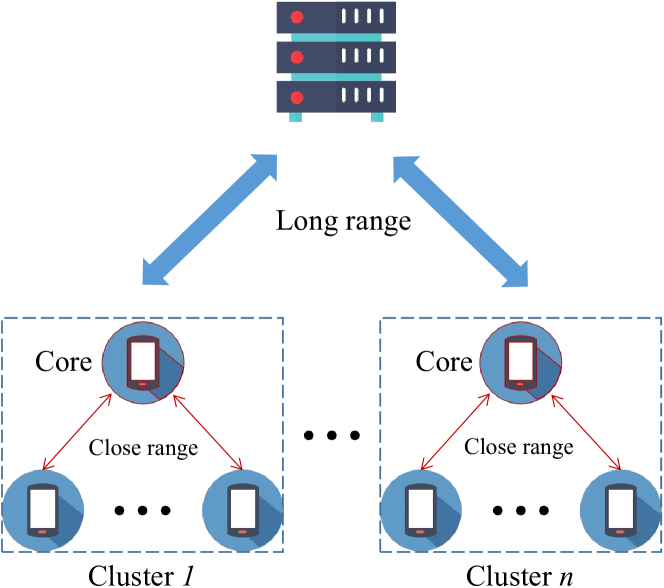
Federated learning (FL), as an emerging collaborative learning paradigm, has garnered significant attention due to its capacity to preserve privacy within distributed learning systems. In these systems, clients collaboratively train a unified neural network model using their local datasets and share model parameters rather than raw data, enhancing privacy. Predominantly, FL systems are designed for mobile and edge computing environments where training typically occurs over wireless networks. Consequently, as model sizes increase, the conventional FL frameworks increasingly consume substantial communication resources. To address this challenge and improve communication efficiency, this paper introduces a novel hierarchical FL framework that integrates the benefits of clustered FL and model compression. We present an adaptive clustering algorithm that identifies a core client and dynamically organizes clients into clusters. Furthermore, to enhance transmission efficiency, each core client implements a local aggregation with compression (LC aggregation) algorithm after collecting compressed models from other clients within the same cluster. Simulation results affirm that our proposed algorithms not only maintain comparable predictive accuracy but also significantly reduce energy consumption relative to existing FL mechanisms.
Read more5/29/2024
🚀
0
Communication-Efficient Federated Learning with Adaptive Compression under Dynamic Bandwidth
Ying Zhuansun, Dandan Li, Xiaohong Huang, Caijun Sun
Federated learning can train models without directly providing local data to the server. However, the frequent updating of the local model brings the problem of large communication overhead. Recently, scholars have achieved the communication efficiency of federated learning mainly by model compression. But they ignore two problems: 1) network state of each client changes dynamically; 2) network state among clients is not the same. The clients with poor bandwidth update local model slowly, which leads to low efficiency. To address this challenge, we propose a communication-efficient federated learning algorithm with adaptive compression under dynamic bandwidth (called AdapComFL). Concretely, each client performs bandwidth awareness and bandwidth prediction. Then, each client adaptively compresses its local model via the improved sketch mechanism based on his predicted bandwidth. Further, the server aggregates sketched models with different sizes received. To verify the effectiveness of the proposed method, the experiments are based on real bandwidth data which are collected from the network topology we build, and benchmark datasets which are obtained from open repositories. We show the performance of AdapComFL algorithm, and compare it with existing algorithms. The experimental results show that our AdapComFL achieves more efficient communication as well as competitive accuracy compared to existing algorithms.
Read more5/7/2024
0
Communication-Efficient Model Aggregation with Layer Divergence Feedback in Federated Learning
Liwei Wang, Jun Li, Wen Chen, Qingqing Wu, Ming Ding
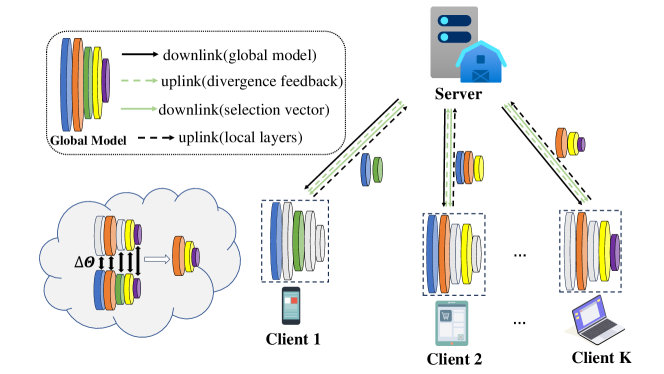
Federated Learning (FL) facilitates collaborative machine learning by training models on local datasets, and subsequently aggregating these local models at a central server. However, the frequent exchange of model parameters between clients and the central server can result in significant communication overhead during the FL training process. To solve this problem, this paper proposes a novel FL framework, the Model Aggregation with Layer Divergence Feedback mechanism (FedLDF). Specifically, we calculate model divergence between the local model and the global model from the previous round. Then through model layer divergence feedback, the distinct layers of each client are uploaded and the amount of data transferred is reduced effectively. Moreover, the convergence bound reveals that the access ratio of clients has a positive correlation with model performance. Simulation results show that our algorithm uploads local models with reduced communication overhead while upholding a superior global model performance.
Read more4/15/2024

0
Efficient Data Distribution Estimation for Accelerated Federated Learning
Yuanli Wang, Lei Huang
Federated Learning(FL) is a privacy-preserving machine learning paradigm where a global model is trained in-situ across a large number of distributed edge devices. These systems are often comprised of millions of user devices and only a subset of available devices can be used for training in each epoch. Designing a device selection strategy is challenging, given that devices are highly heterogeneous in both their system resources and training data. This heterogeneity makes device selection very crucial for timely model convergence and sufficient model accuracy. To tackle the FL client heterogeneity problem, various client selection algorithms have been developed, showing promising performance improvement in terms of model coverage and accuracy. In this work, we study the overhead of client selection algorithms in a large scale FL environment. Then we propose an efficient data distribution summary calculation algorithm to reduce the overhead in a real-world large scale FL environment. The evaluation shows that our proposed solution could achieve up to 30x reduction in data summary time, and up to 360x reduction in clustering time.
Read more6/5/2024