Federated Distillation: A Survey
2404.08564
0
0

Abstract
Federated Learning (FL) seeks to train a model collaboratively without sharing private training data from individual clients. Despite its promise, FL encounters challenges such as high communication costs for large-scale models and the necessity for uniform model architectures across all clients and the server. These challenges severely restrict the practical applications of FL. To address these limitations, the integration of knowledge distillation (KD) into FL has been proposed, forming what is known as Federated Distillation (FD). FD enables more flexible knowledge transfer between clients and the server, surpassing the mere sharing of model parameters. By eliminating the need for identical model architectures across clients and the server, FD mitigates the communication costs associated with training large-scale models. This paper aims to offer a comprehensive overview of FD, highlighting its latest advancements. It delves into the fundamental principles underlying the design of FD frameworks, delineates FD approaches for tackling various challenges, and provides insights into the diverse applications of FD across different scenarios.
Create account to get full access
Overview
- Federated learning: A technique that allows multiple devices or organizations to collaboratively train a machine learning model without sharing their raw data.
- Knowledge distillation: A method that transfers knowledge from a complex "teacher" model to a simpler "student" model.
- Federated distillation: The combination of federated learning and knowledge distillation, which aims to improve the efficiency and performance of federated learning.
Plain English Explanation
Federated learning is a way for different devices or organizations to work together to train a machine learning model without having to share their private data. This is useful for situations where the data is sensitive or spread out across many locations. Enhancing Efficiency of Multi-device Federated Learning Through Data Compression and Conquering Communication Constraints to Enable Large Pre-trained Models in Federated Learning provide more details on the challenges and approaches in federated learning.
Knowledge distillation is a technique where a complex "teacher" model shares its knowledge with a simpler "student" model. This can make the student model more efficient and accurate, even though it is smaller and less complex than the teacher.
Federated distillation combines these two ideas. It uses federated learning to train a central model, and then uses knowledge distillation to transfer that knowledge to smaller models on individual devices. This can help make the federated learning process more efficient and effective.
Technical Explanation
Federated learning allows multiple devices or organizations to collaboratively train a machine learning model without sharing their raw data. Communication-Efficient Model Aggregation for Federated Learning with Layer Divergence and Federated Bayesian Deep Learning provide technical details on different approaches to federated learning.
Knowledge distillation is a technique where a complex "teacher" model shares its knowledge with a simpler "student" model, typically through the use of soft targets or other knowledge transfer mechanisms. This can make the student model more efficient and accurate.
Federated distillation combines these two ideas. It uses federated learning to train a central "teacher" model, and then applies knowledge distillation to transfer that knowledge to smaller "student" models on individual devices. This can help make the federated learning process more efficient and effective, as the smaller student models can be deployed on resource-constrained devices while still benefiting from the knowledge of the larger teacher model.
Critical Analysis
The paper provides a comprehensive survey of the current state of federated distillation research. It highlights the potential benefits of this approach, such as improved model performance and efficiency, as well as the challenges involved, such as the need for effective knowledge transfer techniques and the impact of heterogeneous data and device capabilities.
One potential limitation of the federated distillation approach is the reliance on a centralized "teacher" model, which may introduce additional communication and coordination overhead. Additionally, the performance of the student models may be sensitive to the quality and diversity of the data used to train the teacher model.
Further research is needed to address these challenges and explore alternative approaches to federated distillation, such as decentralized or peer-to-peer knowledge sharing. Federated Computing: A Survey on Building Blocks, Systems, and Extensions provides a broader overview of the field of federated computing and could inform future directions for federated distillation research.
Conclusion
The paper provides a comprehensive survey of the emerging field of federated distillation, which combines the principles of federated learning and knowledge distillation. By leveraging the benefits of both approaches, federated distillation has the potential to improve the efficiency and performance of machine learning models in distributed and privacy-sensitive settings.
The paper highlights the key technical challenges and open research questions in this area, and encourages further exploration of novel techniques and architectures to address these challenges. As the field of federated learning continues to evolve, the insights and perspectives presented in this survey can help guide future research and development efforts in this important and rapidly-advancing domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
Knowledge Distillation in Federated Learning: a Survey on Long Lasting Challenges and New Solutions
Laiqiao Qin, Tianqing Zhu, Wanlei Zhou, Philip S. Yu
0
0
Federated Learning (FL) is a distributed and privacy-preserving machine learning paradigm that coordinates multiple clients to train a model while keeping the raw data localized. However, this traditional FL poses some challenges, including privacy risks, data heterogeneity, communication bottlenecks, and system heterogeneity issues. To tackle these challenges, knowledge distillation (KD) has been widely applied in FL since 2020. KD is a validated and efficacious model compression and enhancement algorithm. The core concept of KD involves facilitating knowledge transfer between models by exchanging logits at intermediate or output layers. These properties make KD an excellent solution for the long-lasting challenges in FL. Up to now, there have been few reviews that summarize and analyze the current trend and methods for how KD can be applied in FL efficiently. This article aims to provide a comprehensive survey of KD-based FL, focusing on addressing the above challenges. First, we provide an overview of KD-based FL, including its motivation, basics, taxonomy, and a comparison with traditional FL and where KD should execute. We also analyze the critical factors in KD-based FL in the appendix, including teachers, knowledge, data, and methods. We discuss how KD can address the challenges in FL, including privacy protection, data heterogeneity, communication efficiency, and personalization. Finally, we discuss the challenges facing KD-based FL algorithms and future research directions. We hope this survey can provide insights and guidance for researchers and practitioners in the FL area.
6/18/2024

Federated Learning with a Single Shared Image
Sunny Soni, Aaqib Saeed, Yuki M. Asano
0
0
Federated Learning (FL) enables multiple machines to collaboratively train a machine learning model without sharing of private training data. Yet, especially for heterogeneous models, a key bottleneck remains the transfer of knowledge gained from each client model with the server. One popular method, FedDF, uses distillation to tackle this task with the use of a common, shared dataset on which predictions are exchanged. However, in many contexts such a dataset might be difficult to acquire due to privacy and the clients might not allow for storage of a large shared dataset. To this end, in this paper, we introduce a new method that improves this knowledge distillation method to only rely on a single shared image between clients and server. In particular, we propose a novel adaptive dataset pruning algorithm that selects the most informative crops generated from only a single image. With this, we show that federated learning with distillation under a limited shared dataset budget works better by using a single image compared to multiple individual ones. Finally, we extend our approach to allow for training heterogeneous client architectures by incorporating a non-uniform distillation schedule and client-model mirroring on the server side.
6/19/2024
📈
MH-pFLID: Model Heterogeneous personalized Federated Learning via Injection and Distillation for Medical Data Analysis
Luyuan Xie, Manqing Lin, Tianyu Luan, Cong Li, Yuejian Fang, Qingni Shen, Zhonghai Wu
0
0
Federated learning is widely used in medical applications for training global models without needing local data access. However, varying computational capabilities and network architectures (system heterogeneity), across clients pose significant challenges in effectively aggregating information from non-independently and identically distributed (non-IID) data. Current federated learning methods using knowledge distillation require public datasets, raising privacy and data collection issues. Additionally, these datasets require additional local computing and storage resources, which is a burden for medical institutions with limited hardware conditions. In this paper, we introduce a novel federated learning paradigm, named Model Heterogeneous personalized Federated Learning via Injection and Distillation (MH-pFLID). Our framework leverages a lightweight messenger model that carries concentrated information to collect the information from each client. We also develop a set of receiver and transmitter modules to receive and send information from the messenger model, so that the information could be injected and distilled with efficiency.
5/14/2024
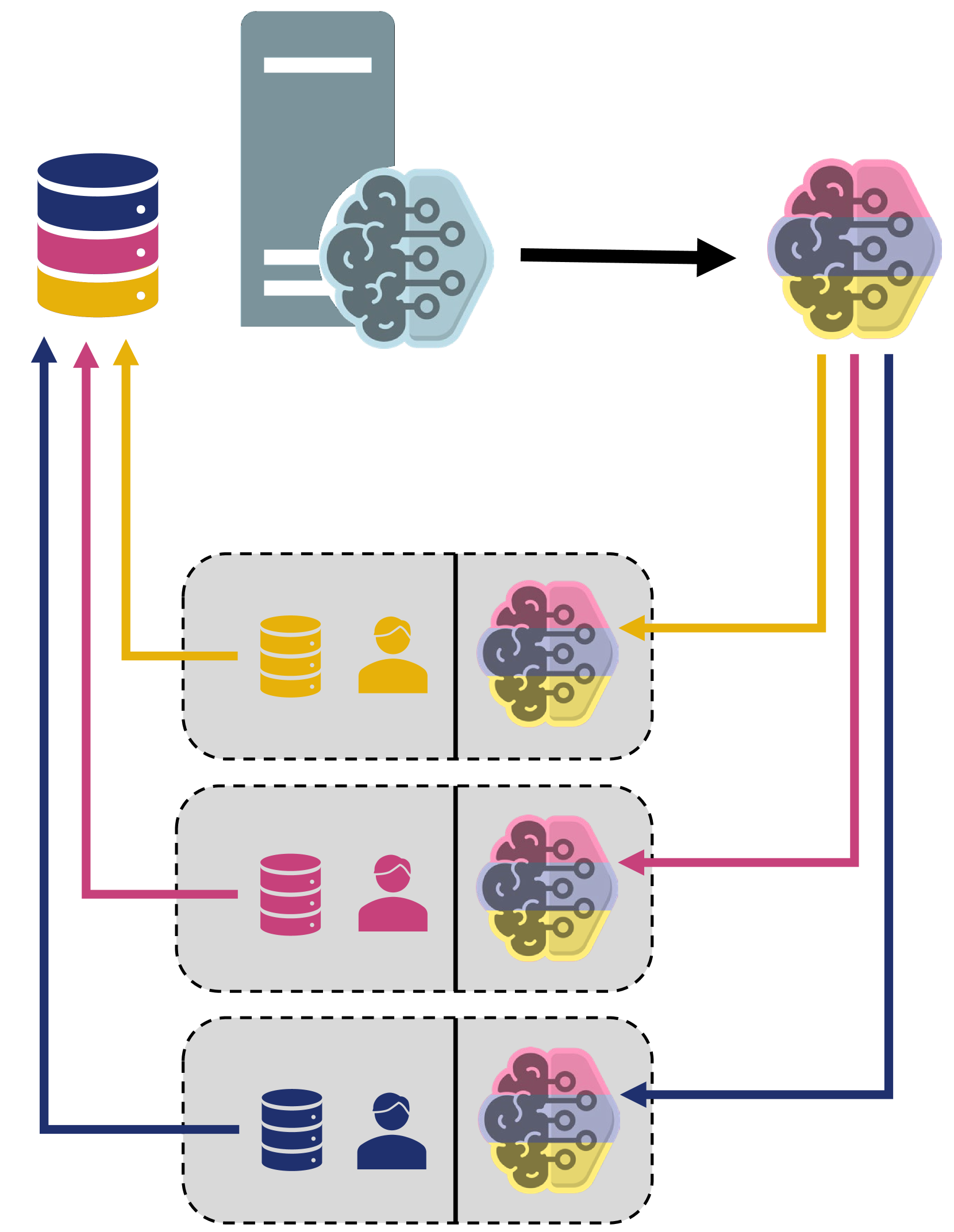
Federated Learning: A Cutting-Edge Survey of the Latest Advancements and Applications
Azim Akhtarshenas, Mohammad Ali Vahedifar, Navid Ayoobi, Behrouz Maham, Tohid Alizadeh, Sina Ebrahimi, David L'opez-P'erez
0
0
Robust machine learning (ML) models can be developed by leveraging large volumes of data and distributing the computational tasks across numerous devices or servers. Federated learning (FL) is a technique in the realm of ML that facilitates this goal by utilizing cloud infrastructure to enable collaborative model training among a network of decentralized devices. Beyond distributing the computational load, FL targets the resolution of privacy issues and the reduction of communication costs simultaneously. To protect user privacy, FL requires users to send model updates rather than transmitting large quantities of raw and potentially confidential data. Specifically, individuals train ML models locally using their own data and then upload the results in the form of weights and gradients to the cloud for aggregation into the global model. This strategy is also advantageous in environments with limited bandwidth or high communication costs, as it prevents the transmission of large data volumes. With the increasing volume of data and rising privacy concerns, alongside the emergence of large-scale ML models like Large Language Models (LLMs), FL presents itself as a timely and relevant solution. It is therefore essential to review current FL algorithms to guide future research that meets the rapidly evolving ML demands. This survey provides a comprehensive analysis and comparison of the most recent FL algorithms, evaluating them on various fronts including mathematical frameworks, privacy protection, resource allocation, and applications. Beyond summarizing existing FL methods, this survey identifies potential gaps, open areas, and future challenges based on the performance reports and algorithms used in recent studies. This survey enables researchers to readily identify existing limitations in the FL field for further exploration.
5/28/2024