Communication-Efficient Soft Actor-Critic Policy Collaboration via Regulated Segment Mixture in Internet of Vehicles

0
Sign in to get full access
Overview
- Proposes a communication-efficient soft actor-critic policy collaboration approach for the Internet of Vehicles (IoV) domain
- Introduces a regulated segment mixture technique to address challenges in multi-agent reinforcement learning
- Demonstrates improved performance in terms of reduced communication overhead and enhanced learning stability
Plain English Explanation
The paper presents a new approach to enable efficient collaboration between autonomous vehicles in the Internet of Vehicles (IoV) system. The key idea is to use a technique called "regulated segment mixture" to improve the way these vehicles, or agents, learn and share information with each other.
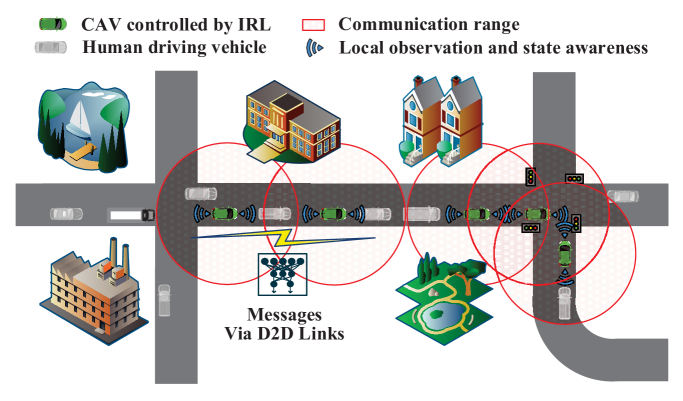
In the IoV setting, autonomous vehicles need to constantly communicate and coordinate their actions to navigate roads safely and efficiently. However, excessive communication can lead to high overhead and reduced learning performance. The proposed method addresses this by allowing the vehicles to selectively share only the most relevant information, reducing the overall communication required.
The regulated segment mixture technique works by dividing the policy (the decision-making process) of each vehicle into smaller "segments." These segments are then mixed and shared with other vehicles, but in a controlled manner to ensure the most important information is prioritized. This helps the vehicles learn from each other's experiences more effectively, while minimizing the communication burden.
By adopting this approach, the authors demonstrate that the autonomous vehicles can achieve better overall performance, with improved learning stability and reduced communication requirements, compared to traditional methods. This could have significant implications for the development of more efficient and safer self-driving car systems in the future.
Technical Explanation
The paper proposes a Communication-Efficient Soft Actor-Critic Policy Collaboration approach for the Internet of Vehicles (IoV) domain, which leverages a regulated segment mixture technique to address the challenges of multi-agent reinforcement learning.
The key components of the proposed method are:
-
Soft Actor-Critic (SAC) Framework: The authors build upon the Soft Actor-Critic algorithm, which is a state-of-the-art reinforcement learning technique that balances exploration and exploitation.
-
Regulated Segment Mixture: To enable efficient communication and collaboration between agents (autonomous vehicles), the authors introduce a "regulated segment mixture" approach. This involves dividing the policy of each agent into smaller "segments" and selectively sharing these segments with other agents, based on a regulated mixing strategy.
-
Communication-Efficient Policy Collaboration: By leveraging the regulated segment mixture technique, the proposed method reduces the communication overhead required for policy collaboration, while maintaining the benefits of multi-agent learning. This is particularly important in the IoV domain, where excessive communication can be detrimental to system performance.
The authors evaluate the proposed approach on a simulated IoV environment and demonstrate its advantages over existing methods in terms of reduced communication overhead and enhanced learning stability. The Distributed Approach to Autonomous Intersection Management and Decentralized Transformers with Centralized Aggregation are among the related works that the authors compare their method against.
Critical Analysis
The paper presents a well-designed solution to address the communication challenges in multi-agent reinforcement learning for the IoV domain. The regulated segment mixture technique is a novel and promising approach that could have broader applications beyond the specific IoV use case.
However, the paper does not discuss potential limitations or edge cases of the proposed method. For instance, it would be valuable to understand how the approach might perform in more complex or dynamic IoV scenarios, such as when the number of vehicles or the road network topology changes significantly.
Additionally, the paper could have provided more insights into the MRIC: Model-based Reinforcement Imitation Learning Mixture approach and how it relates to the proposed technique, as both aim to address communication challenges in multi-agent systems.
Overall, the research presents a promising direction for enabling efficient collaboration in the Fully Distributed Fog Load Balancing domain, and the authors have succeeded in demonstrating the advantages of their approach. Further exploration of the method's limitations and potential extensions could strengthen the contribution of this work.
Conclusion
The paper introduces a communication-efficient soft actor-critic policy collaboration approach for the Internet of Vehicles (IoV) domain. By leveraging a regulated segment mixture technique, the proposed method enables efficient information sharing between autonomous vehicles, reducing the overall communication overhead while maintaining the benefits of multi-agent learning.
The authors demonstrate the effectiveness of their approach through simulation experiments, showcasing improved performance in terms of reduced communication requirements and enhanced learning stability. This work has the potential to contribute to the development of more efficient and coordinated self-driving car systems, which could lead to safer and more sustainable transportation solutions in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Communication-Efficient Soft Actor-Critic Policy Collaboration via Regulated Segment Mixture in Internet of Vehicles
Xiaoxue Yu, Rongpeng Li, Chengchao Liang, Zhifeng Zhao
Multi-Agent Reinforcement Learning (MARL) has emerged as a foundational approach for addressing diverse, intelligent control tasks, notably in autonomous driving within the Internet of Vehicles (IoV) domain. However, the widely assumed existence of a central node for centralized, federated learning-assisted MARL might be impractical in highly dynamic environments. This can lead to excessive communication overhead, potentially overwhelming the IoV system. To address these challenges, we design a novel communication-efficient and policy collaboration algorithm for MARL under the frameworks of Soft Actor-Critic (SAC) and Decentralized Federated Learning (DFL), named RSM-MASAC, within a fully distributed architecture. In particular, RSM-MASAC enhances multi-agent collaboration and prioritizes higher communication efficiency in dynamic IoV system by incorporating the concept of segmented aggregation in DFL and augmenting multiple model replicas from received neighboring policy segments, which are subsequently employed as reconstructed referential policies for mixing. Distinctively diverging from traditional RL approaches, with derived new bounds under Maximum Entropy Reinforcement Learning (MERL), RSM-MASAC adopts a theory-guided mixture metric to regulate the selection of contributive referential policies to guarantee the soft policy improvement during communication phase. Finally, the extensive simulations in mixed-autonomy traffic control scenarios verify the effectiveness and superiority of our algorithm.
Read more7/11/2024

0
Communication-Aware Reinforcement Learning for Cooperative Adaptive Cruise Control
Sicong Jiang, Seongjin Choi, Lijun Sun
Cooperative Adaptive Cruise Control (CACC) plays a pivotal role in enhancing traffic efficiency and safety in Connected and Autonomous Vehicles (CAVs). Reinforcement Learning (RL) has proven effective in optimizing complex decision-making processes in CACC, leading to improved system performance and adaptability. Among RL approaches, Multi-Agent Reinforcement Learning (MARL) has shown remarkable potential by enabling coordinated actions among multiple CAVs through Centralized Training with Decentralized Execution (CTDE). However, MARL often faces scalability issues, particularly when CACC vehicles suddenly join or leave the platoon, resulting in performance degradation. To address these challenges, we propose Communication-Aware Reinforcement Learning (CA-RL). CA-RL includes a communication-aware module that extracts and compresses vehicle communication information through forward and backward information transmission modules. This enables efficient cyclic information propagation within the CACC traffic flow, ensuring policy consistency and mitigating the scalability problems of MARL in CACC. Experimental results demonstrate that CA-RL significantly outperforms baseline methods in various traffic scenarios, achieving superior scalability, robustness, and overall system performance while maintaining reliable performance despite changes in the number of participating vehicles.
Read more7/15/2024

0
Multi-Agent Reinforcement Learning for Autonomous Driving: A Survey
Ruiqi Zhang, Jing Hou, Florian Walter, Shangding Gu, Jiayi Guan, Florian Rohrbein, Yali Du, Panpan Cai, Guang Chen, Alois Knoll
Reinforcement Learning (RL) is a potent tool for sequential decision-making and has achieved performance surpassing human capabilities across many challenging real-world tasks. As the extension of RL in the multi-agent system domain, multi-agent RL (MARL) not only need to learn the control policy but also requires consideration regarding interactions with all other agents in the environment, mutual influences among different system components, and the distribution of computational resources. This augments the complexity of algorithmic design and poses higher requirements on computational resources. Simultaneously, simulators are crucial to obtain realistic data, which is the fundamentals of RL. In this paper, we first propose a series of metrics of simulators and summarize the features of existing benchmarks. Second, to ease comprehension, we recall the foundational knowledge and then synthesize the recently advanced studies of MARL-related autonomous driving and intelligent transportation systems. Specifically, we examine their environmental modeling, state representation, perception units, and algorithm design. Conclusively, we discuss open challenges as well as prospects and opportunities. We hope this paper can help the researchers integrate MARL technologies and trigger more insightful ideas toward the intelligent and autonomous driving.
Read more8/20/2024

0
A Distributed Approach to Autonomous Intersection Management via Multi-Agent Reinforcement Learning
Matteo Cederle, Marco Fabris, Gian Antonio Susto
Autonomous intersection management (AIM) poses significant challenges due to the intricate nature of real-world traffic scenarios and the need for a highly expensive centralised server in charge of simultaneously controlling all the vehicles. This study addresses such issues by proposing a novel distributed approach to AIM utilizing multi-agent reinforcement learning (MARL). We show that by leveraging the 3D surround view technology for advanced assistance systems, autonomous vehicles can accurately navigate intersection scenarios without needing any centralised controller. The contributions of this paper thus include a MARL-based algorithm for the autonomous management of a 4-way intersection and also the introduction of a new strategy called prioritised scenario replay for improved training efficacy. We validate our approach as an innovative alternative to conventional centralised AIM techniques, ensuring the full reproducibility of our results. Specifically, experiments conducted in virtual environments using the SMARTS platform highlight its superiority over benchmarks across various metrics.
Read more5/15/2024