Decentralized Transformers with Centralized Aggregation are Sample-Efficient Multi-Agent World Models
2406.15836
0
0

Abstract
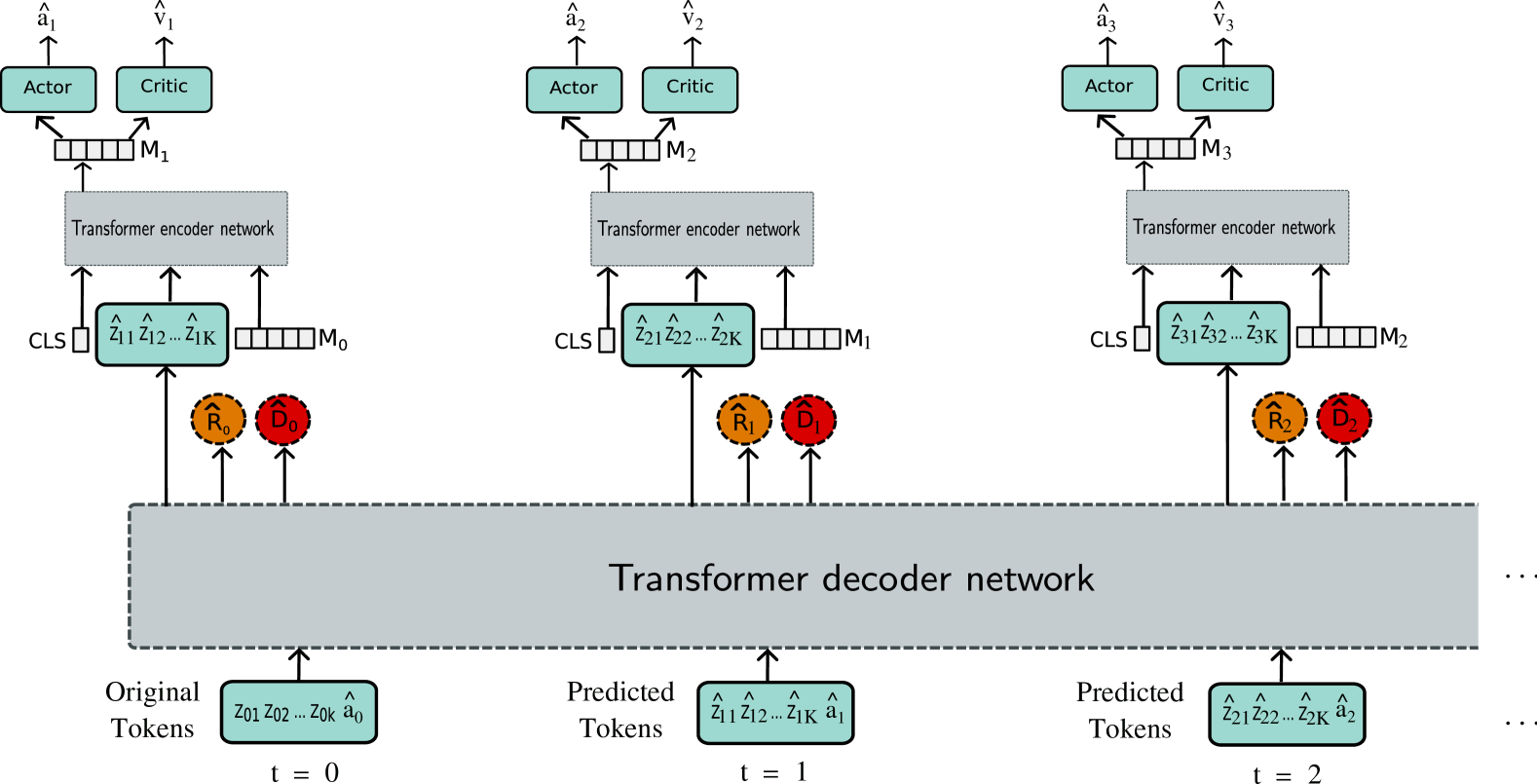
Learning a world model for model-free Reinforcement Learning (RL) agents can significantly improve the sample efficiency by learning policies in imagination. However, building a world model for Multi-Agent RL (MARL) can be particularly challenging due to the scalability issue in a centralized architecture arising from a large number of agents, and also the non-stationarity issue in a decentralized architecture stemming from the inter-dependency among agents. To address both challenges, we propose a novel world model for MARL that learns decentralized local dynamics for scalability, combined with a centralized representation aggregation from all agents. We cast the dynamics learning as an auto-regressive sequence modeling problem over discrete tokens by leveraging the expressive Transformer architecture, in order to model complex local dynamics across different agents and provide accurate and consistent long-term imaginations. As the first pioneering Transformer-based world model for multi-agent systems, we introduce a Perceiver Transformer as an effective solution to enable centralized representation aggregation within this context. Results on Starcraft Multi-Agent Challenge (SMAC) show that it outperforms strong model-free approaches and existing model-based methods in both sample efficiency and overall performance.
Create account to get full access
Overview
- This paper presents a novel decentralized transformer-based model for efficient multi-agent reinforcement learning (MARL).
- The model combines decentralized learning with centralized aggregation, allowing for sample-efficient world modeling in multi-agent environments.
- The authors demonstrate the effectiveness of their approach on a range of challenging MARL benchmarks, outperforming existing methods.
Plain English Explanation
In this paper, the researchers have developed a new type of machine learning model that is well-suited for training multiple autonomous agents to work together efficiently in complex environments. The key innovation is that the model uses a decentralized approach, where each agent has its own set of transformer-based neural networks to learn its own internal "world model" of the environment. However, these individual models are then combined and aggregated at a central point, allowing the agents to benefit from a more comprehensive understanding of the overall situation.
This decentralized-yet-centralized design helps the agents learn more quickly and with fewer training samples, which is an important consideration for real-world applications where data and computational resources may be limited. The authors show that their model outperforms other state-of-the-art approaches on a variety of challenging multi-agent benchmarks, demonstrating its effectiveness and potential for applications like robotics, autonomous vehicles, and multi-player games.
The use of transformer-based architectures is also notable, as transformers have become increasingly popular in recent years for their ability to capture complex patterns and relationships in data, including in the context of learning world models and multi-agent systems. By applying transformers in a decentralized setting, the researchers have found a way to leverage their strengths while also addressing some of the challenges of multi-agent learning, such as sample efficiency and scalability.
Technical Explanation
The core of the researchers' approach is a decentralized transformer-based model, where each agent in the multi-agent environment has its own set of transformer encoder and decoder modules to learn an internal "world model" of the environment. These individual models are then aggregated at a central point using a novel attention-based pooling mechanism, allowing the agents to benefit from a more comprehensive understanding of the overall situation.
This decentralized-yet-centralized design helps address some of the key challenges in multi-agent reinforcement learning, such as sample efficiency and scalability. By having each agent learn its own local world model, the overall training process becomes more sample-efficient, as the agents can leverage their individual experiences to update their own models. The central aggregation step then allows the agents to share and integrate their knowledge, leading to more effective joint decision-making.
The authors evaluate their approach on a range of challenging MARL benchmarks, including complex multi-agent environments and physically-simulated tasks. Their results demonstrate that the decentralized transformer model outperforms other state-of-the-art MARL methods in terms of sample efficiency and task performance, highlighting the potential of this approach for real-world applications.
Critical Analysis
The researchers have presented a compelling and well-designed approach to multi-agent reinforcement learning, leveraging the strengths of decentralized learning and centralized aggregation. The use of transformer-based architectures is a particularly interesting choice, as it allows the agents to capture complex patterns and relationships in the environment, which is crucial for effective multi-agent coordination and decision-making.
However, the paper does not fully address some of the potential limitations and challenges of this approach. For example, the centralized aggregation step may introduce additional computational overhead and complexity, especially as the number of agents scales up. The researchers could have discussed strategies for mitigating these issues, such as hierarchical or distributed aggregation schemes.
Additionally, the evaluation is primarily focused on simulated environments, and it would be valuable to see how the decentralized transformer model performs in more complex, real-world scenarios with partial observability, dynamic agent populations, and other practical challenges. Exploring these areas could help further validate the approach and identify potential areas for improvement.
Conclusion
Overall, this paper presents a novel and promising approach to multi-agent reinforcement learning, combining decentralized learning with centralized aggregation to achieve sample-efficient world modeling. The use of transformer-based architectures is a notable contribution, as it allows the agents to capture complex patterns and relationships in the environment. While the paper demonstrates the effectiveness of this approach on a range of challenging benchmarks, further research is needed to fully understand its capabilities and limitations, particularly in more complex, real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Efficient Multi-agent Reinforcement Learning by Planning
Qihan Liu, Jianing Ye, Xiaoteng Ma, Jun Yang, Bin Liang, Chongjie Zhang
0
0
Multi-agent reinforcement learning (MARL) algorithms have accomplished remarkable breakthroughs in solving large-scale decision-making tasks. Nonetheless, most existing MARL algorithms are model-free, limiting sample efficiency and hindering their applicability in more challenging scenarios. In contrast, model-based reinforcement learning (MBRL), particularly algorithms integrating planning, such as MuZero, has demonstrated superhuman performance with limited data in many tasks. Hence, we aim to boost the sample efficiency of MARL by adopting model-based approaches. However, incorporating planning and search methods into multi-agent systems poses significant challenges. The expansive action space of multi-agent systems often necessitates leveraging the nearly-independent property of agents to accelerate learning. To tackle this issue, we propose the MAZero algorithm, which combines a centralized model with Monte Carlo Tree Search (MCTS) for policy search. We design a novel network structure to facilitate distributed execution and parameter sharing. To enhance search efficiency in deterministic environments with sizable action spaces, we introduce two novel techniques: Optimistic Search Lambda (OS($lambda$)) and Advantage-Weighted Policy Optimization (AWPO). Extensive experiments on the SMAC benchmark demonstrate that MAZero outperforms model-free approaches in terms of sample efficiency and provides comparable or better performance than existing model-based methods in terms of both sample and computational efficiency. Our code is available at https://github.com/liuqh16/MAZero.
5/21/2024
Learning to Play Atari in a World of Tokens
Pranav Agarwal, Sheldon Andrews, Samira Ebrahimi Kahou
0
0
Model-based reinforcement learning agents utilizing transformers have shown improved sample efficiency due to their ability to model extended context, resulting in more accurate world models. However, for complex reasoning and planning tasks, these methods primarily rely on continuous representations. This complicates modeling of discrete properties of the real world such as disjoint object classes between which interpolation is not plausible. In this work, we introduce discrete abstract representations for transformer-based learning (DART), a sample-efficient method utilizing discrete representations for modeling both the world and learning behavior. We incorporate a transformer-decoder for auto-regressive world modeling and a transformer-encoder for learning behavior by attending to task-relevant cues in the discrete representation of the world model. For handling partial observability, we aggregate information from past time steps as memory tokens. DART outperforms previous state-of-the-art methods that do not use look-ahead search on the Atari 100k sample efficiency benchmark with a median human-normalized score of 0.790 and beats humans in 9 out of 26 games. We release our code at https://pranaval.github.io/DART/.
6/4/2024

Efficient World Models with Context-Aware Tokenization
Vincent Micheli, Eloi Alonso, Franc{c}ois Fleuret
0
0
Scaling up deep Reinforcement Learning (RL) methods presents a significant challenge. Following developments in generative modelling, model-based RL positions itself as a strong contender. Recent advances in sequence modelling have led to effective transformer-based world models, albeit at the price of heavy computations due to the long sequences of tokens required to accurately simulate environments. In this work, we propose $Delta$-IRIS, a new agent with a world model architecture composed of a discrete autoencoder that encodes stochastic deltas between time steps and an autoregressive transformer that predicts future deltas by summarizing the current state of the world with continuous tokens. In the Crafter benchmark, $Delta$-IRIS sets a new state of the art at multiple frame budgets, while being an order of magnitude faster to train than previous attention-based approaches. We release our code and models at https://github.com/vmicheli/delta-iris.
6/28/2024

Locality Sensitive Sparse Encoding for Learning World Models Online
Zichen Liu, Chao Du, Wee Sun Lee, Min Lin
0
0
Acquiring an accurate world model online for model-based reinforcement learning (MBRL) is challenging due to data nonstationarity, which typically causes catastrophic forgetting for neural networks (NNs). From the online learning perspective, a Follow-The-Leader (FTL) world model is desirable, which optimally fits all previous experiences at each round. Unfortunately, NN-based models need re-training on all accumulated data at every interaction step to achieve FTL, which is computationally expensive for lifelong agents. In this paper, we revisit models that can achieve FTL with incremental updates. Specifically, our world model is a linear regression model supported by nonlinear random features. The linear part ensures efficient FTL update while the nonlinear random feature empowers the fitting of complex environments. To best trade off model capacity and computation efficiency, we introduce a locality sensitive sparse encoding, which allows us to conduct efficient sparse updates even with very high dimensional nonlinear features. We validate the representation power of our encoding and verify that it allows efficient online learning under data covariate shift. We also show, in the Dyna MBRL setting, that our world models learned online using a single pass of trajectory data either surpass or match the performance of deep world models trained with replay and other continual learning methods.
4/9/2024