CompactifAI: Extreme Compression of Large Language Models using Quantum-Inspired Tensor Networks
2401.14109
0
0
💬
Abstract
Large Language Models (LLMs) such as ChatGPT and LlaMA are advancing rapidly in generative Artificial Intelligence (AI), but their immense size poses significant challenges, such as huge training and inference costs, substantial energy demands, and limitations for on-site deployment. Traditional compression methods such as pruning, distillation, and low-rank approximation focus on reducing the effective number of neurons in the network, while quantization focuses on reducing the numerical precision of individual weights to reduce the model size while keeping the number of neurons fixed. While these compression methods have been relatively successful in practice, there is no compelling reason to believe that truncating the number of neurons is an optimal strategy. In this context, this paper introduces CompactifAI, an innovative LLM compression approach using quantum-inspired Tensor Networks that focuses on the model's correlation space instead, allowing for a more controlled, refined and interpretable model compression. Our method is versatile and can be implemented with - or on top of - other compression techniques. As a benchmark, we demonstrate that a combination of CompactifAI with quantization allows to reduce a 93% the memory size of LlaMA 7B, reducing also 70% the number of parameters, accelerating 50% the training and 25% the inference times of the model, and just with a small accuracy drop of 2% - 3%, going much beyond of what is achievable today by other compression techniques. Our methods also allow to perform a refined layer sensitivity profiling, showing that deeper layers tend to be more suitable for tensor network compression, which is compatible with recent observations on the ineffectiveness of those layers for LLM performance. Our results imply that standard LLMs are, in fact, heavily overparametrized, and do not need to be large at all.
Create account to get full access
Overview
- Large Language Models (LLMs) like ChatGPT and LlaMA are advancing rapidly in generative AI, but their large size poses challenges.
- Traditional compression methods focus on reducing the number of neurons, while quantization reduces numerical precision.
- This paper introduces CompactifAI, a new compression approach using quantum-inspired Tensor Networks that focuses on the model's correlation space.
Plain English Explanation
CompactifAI is a new way to make large language models like ChatGPT and LlaMA smaller and more efficient. These models are incredibly powerful, but they're also massive in size, which makes them expensive to train and run.
Typically, researchers have tried to compress these models by either removing neurons (neurons are the basic units that make up the model) or reducing the precision of the numbers used to represent the model's parameters. While these methods have had some success, the researchers behind CompactifAI argue that there's a better way.
Instead of focusing on the number of neurons or the precision of the numbers, CompactifAI looks at the relationships between different parts of the model. By using a technique inspired by quantum physics, called Tensor Networks, the researchers were able to find a more efficient way to represent these relationships, allowing them to dramatically reduce the size of the model without losing too much performance.
One key advantage of this approach is that it allows for a more "interpretable" compression - meaning that the researchers can better understand why certain parts of the model are more important than others. This could lead to insights about how these large language models work, and potentially help improve them even further.
Technical Explanation
The researchers behind CompactifAI argue that traditional compression methods, like pruning, distillation, and low-rank approximation, focus on reducing the number of neurons in the network, while quantization reduces the numerical precision of individual weights. However, they believe there is no compelling reason to think that truncating the number of neurons is an optimal strategy.
To address this, the researchers introduce CompactifAI, an innovative compression approach that uses quantum-inspired Tensor Networks to focus on the model's correlation space, rather than the number of neurons. This allows for a more controlled, refined, and interpretable model compression.
As a benchmark, the researchers demonstrate that combining CompactifAI with quantization can reduce the memory size of the LlaMA 7B model by 93%, reduce the number of parameters by 70%, and accelerate training by 50% and inference by 25%, all while only experiencing a small accuracy drop of 2-3%. This goes beyond what is achievable with other compression techniques, as shown in related research.
The researchers also show that deeper layers of the model are more suitable for tensor network compression, which is compatible with recent observations on the ineffectiveness of those layers for LLM performance. This suggests that standard LLMs are heavily overparameterized and do not need to be as large as they are.
Critical Analysis
The paper presents a compelling approach to compressing large language models, but it's important to consider some potential caveats and areas for further research.
One key limitation is that the experiments were conducted on a relatively small model (LlaMA 7B) compared to the largest LLMs like GPT-3 and PaLM. It's unclear if the same level of compression and performance improvements would be achievable on these larger models.
Additionally, the researchers note that their method can be implemented alongside other compression techniques, such as quantization. This suggests that the true potential of CompactifAI may only be realized when combined with other approaches, which could add complexity to the overall compression pipeline.
Further research is also needed to fully understand the interpretability and layer-specific insights that the tensor network compression provides. While the researchers suggest this is a key advantage, more analysis is required to demonstrate the practical implications of these insights.
Conclusion
The CompactifAI approach presented in this paper offers a promising new direction for compressing large language models. By focusing on the model's correlation space rather than simply reducing the number of neurons, the researchers have developed a more nuanced and interpretable compression technique.
The results showing dramatic reductions in model size, training, and inference time, with only a small drop in accuracy, are impressive and suggest that current LLMs may be significantly over-parameterized. As the field of generative AI continues to advance, techniques like CompactifAI will be crucial for making these powerful models more accessible and practical for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
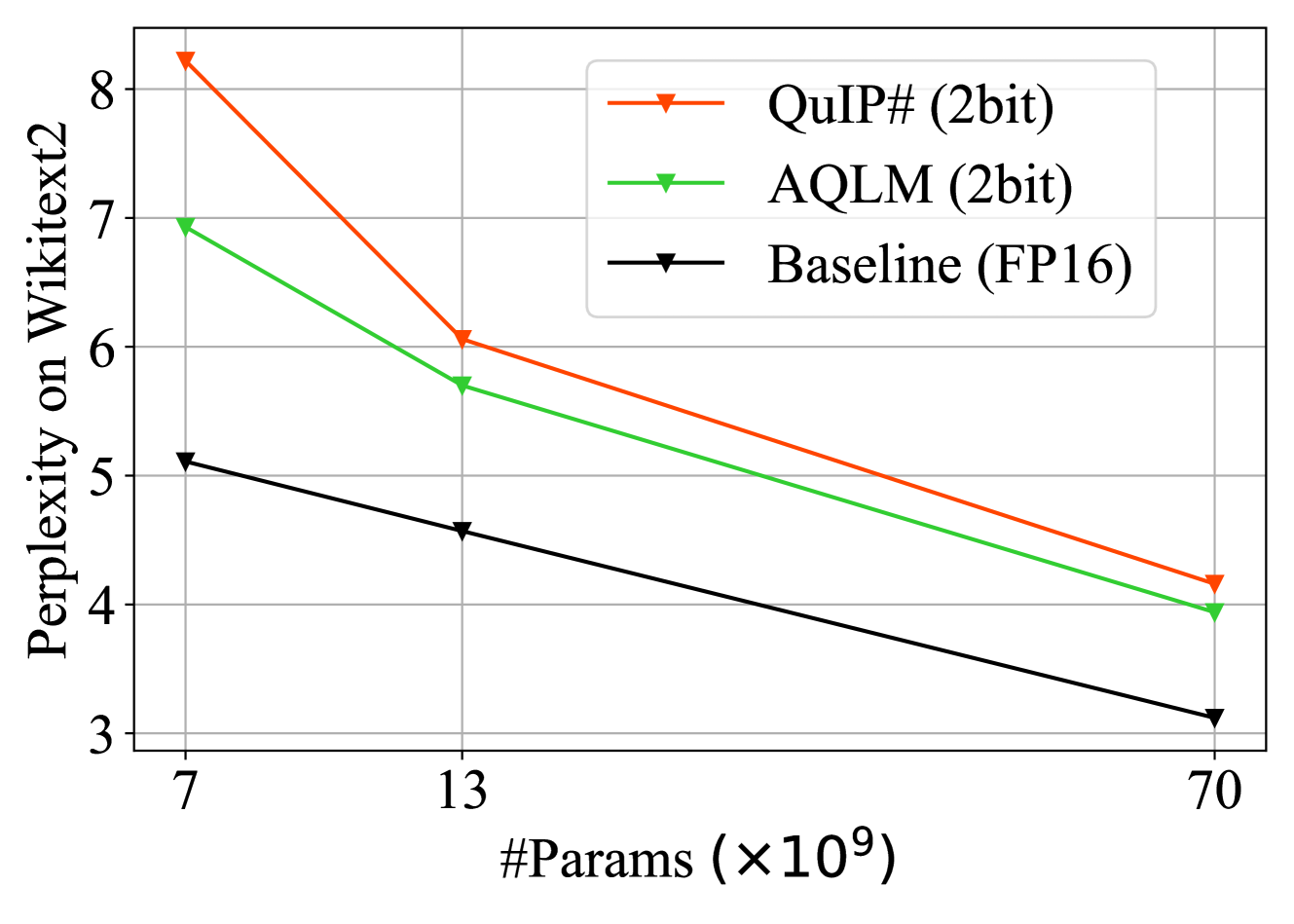
Extreme Compression of Large Language Models via Additive Quantization
Vage Egiazarian, Andrei Panferov, Denis Kuznedelev, Elias Frantar, Artem Babenko, Dan Alistarh
0
0
The emergence of accurate open large language models (LLMs) has led to a race towards performant quantization techniques which can enable their execution on end-user devices. In this paper, we revisit the problem of ``extreme'' LLM compression -- defined as targeting extremely low bit counts, such as 2 to 3 bits per parameter -- from the point of view of classic methods in Multi-Codebook Quantization (MCQ). Our algorithm, called AQLM, generalizes the classic Additive Quantization (AQ) approach for information retrieval to advance the state-of-the-art in LLM compression, via two innovations: 1) learned additive quantization of weight matrices in input-adaptive fashion, and 2) joint optimization of codebook parameters across each transformer blocks. Broadly, AQLM is the first scheme that is Pareto optimal in terms of accuracy-vs-model-size when compressing to less than 3 bits per parameter, and significantly improves upon all known schemes in the extreme compression (2bit) regime. In addition, AQLM is practical: we provide fast GPU and CPU implementations of AQLM for token generation, which enable us to match or outperform optimized FP16 implementations for speed, while executing in a much smaller memory footprint.
6/11/2024
💬
On the Compressibility of Quantized Large Language Models
Yu Mao, Weilan Wang, Hongchao Du, Nan Guan, Chun Jason Xue
0
0
Deploying Large Language Models (LLMs) on edge or mobile devices offers significant benefits, such as enhanced data privacy and real-time processing capabilities. However, it also faces critical challenges due to the substantial memory requirement of LLMs. Quantization is an effective way of reducing the model size while maintaining good performance. However, even after quantization, LLMs may still be too big to fit entirely into the limited memory of edge or mobile devices and have to be partially loaded from the storage to complete the inference. In this case, the I/O latency of model loading becomes the bottleneck of the LLM inference latency. In this work, we take a preliminary step of studying applying data compression techniques to reduce data movement and thus speed up the inference of quantized LLM on memory-constrained devices. In particular, we discussed the compressibility of quantized LLMs, the trade-off between the compressibility and performance of quantized LLMs, and opportunities to optimize both of them jointly.
5/7/2024
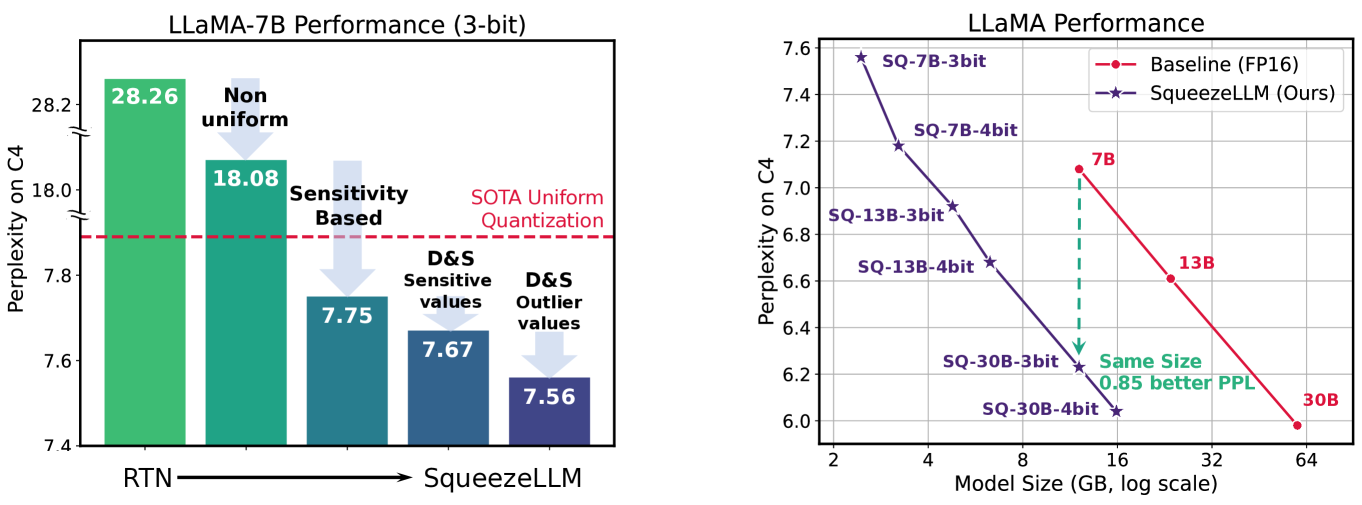
SqueezeLLM: Dense-and-Sparse Quantization
Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, Kurt Keutzer
0
0
Generative Large Language Models (LLMs) have demonstrated remarkable results for a wide range of tasks. However, deploying these models for inference has been a significant challenge due to their unprecedented resource requirements. This has forced existing deployment frameworks to use multi-GPU inference pipelines, which are often complex and costly, or to use smaller and less performant models. In this work, we demonstrate that the main bottleneck for generative inference with LLMs is memory bandwidth, rather than compute, specifically for single batch inference. While quantization has emerged as a promising solution by representing weights with reduced precision, previous efforts have often resulted in notable performance degradation. To address this, we introduce SqueezeLLM, a post-training quantization framework that not only enables lossless compression to ultra-low precisions of up to 3-bit, but also achieves higher quantization performance under the same memory constraint. Our framework incorporates two novel ideas: (i) sensitivity-based non-uniform quantization, which searches for the optimal bit precision assignment based on second-order information; and (ii) the Dense-and-Sparse decomposition that stores outliers and sensitive weight values in an efficient sparse format. When applied to the LLaMA models, our 3-bit quantization significantly reduces the perplexity gap from the FP16 baseline by up to 2.1x as compared to the state-of-the-art methods with the same memory requirement. Furthermore, when deployed on an A6000 GPU, our quantized models achieve up to 2.3x speedup compared to the baseline. Our code is available at https://github.com/SqueezeAILab/SqueezeLLM.
6/6/2024
🤯
Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
Georgy Tyukin
0
0
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
4/10/2024