On the Compressibility of Quantized Large Language Models
2403.01384
0
0
💬
Abstract
Deploying Large Language Models (LLMs) on edge or mobile devices offers significant benefits, such as enhanced data privacy and real-time processing capabilities. However, it also faces critical challenges due to the substantial memory requirement of LLMs. Quantization is an effective way of reducing the model size while maintaining good performance. However, even after quantization, LLMs may still be too big to fit entirely into the limited memory of edge or mobile devices and have to be partially loaded from the storage to complete the inference. In this case, the I/O latency of model loading becomes the bottleneck of the LLM inference latency. In this work, we take a preliminary step of studying applying data compression techniques to reduce data movement and thus speed up the inference of quantized LLM on memory-constrained devices. In particular, we discussed the compressibility of quantized LLMs, the trade-off between the compressibility and performance of quantized LLMs, and opportunities to optimize both of them jointly.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Deploying large language models (LLMs) on edge or mobile devices offers benefits like enhanced data privacy and real-time processing, but faces challenges due to the substantial memory requirements of LLMs.
- Quantization can reduce model size while maintaining performance, but even quantized LLMs may still be too large to fit entirely into the limited memory of edge/mobile devices.
- In this work, the researchers explore applying data compression techniques to reduce data movement and speed up inference of quantized LLMs on memory-constrained devices.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. Deploying these models on edge or mobile devices can provide benefits like better privacy and faster response times. However, LLMs require a lot of memory, which can be a challenge for devices with limited storage.
One way to reduce the model size is through a process called quantization, which compresses the model without significantly impacting its performance. But even after quantization, the model may still be too large to fit entirely in the device's memory. In this case, parts of the model have to be loaded from storage during use, which can slow down the process.
The researchers in this paper looked at using data compression techniques to further reduce the size of the quantized LLM, with the goal of speeding up the inference process on memory-constrained devices. They explored the tradeoffs between how much the model can be compressed and the impact on its performance.
Technical Explanation
The key elements of the paper include:
- Studying the compressibility of quantized LLMs: The researchers investigated how much data compression can be applied to quantized LLMs without significantly impacting their performance.
- Analyzing the tradeoff between compressibility and performance: They examined the balance between achieving high compression rates and maintaining the accuracy of the quantized LLMs.
- Exploring opportunities for joint optimization: The paper discusses ways to optimize both the compressibility and the performance of quantized LLMs together.
The researchers conducted experiments to understand these aspects and provide insights that can inform the deployment of LLMs on memory-constrained edge and mobile devices.
Critical Analysis
The paper provides a valuable initial exploration of using data compression to enable the efficient deployment of large language models on resource-limited hardware. However, it acknowledges that further research is needed to fully address the challenges:
- The experiments were limited in scope and scale, and more comprehensive evaluations would be helpful to validate the findings.
- The paper does not delve into potential issues around the practical implementation of the compression techniques, such as the computational overhead or integration with existing LLM inference pipelines.
- While the researchers discuss the tradeoffs between compression and performance, there may be additional factors to consider, such as the impact on model interpretability or robustness.
Nonetheless, this work opens up an important research direction and highlights the need for innovative solutions to bridge the gap between the impressive capabilities of LLMs and the constraints of edge and mobile computing.
Conclusion
This paper takes a crucial first step in exploring the use of data compression techniques to enable the deployment of large language models on memory-constrained edge and mobile devices. By addressing the substantial memory requirements of LLMs, this research paves the way for bringing the benefits of these powerful AI systems, such as enhanced privacy and real-time processing, to a wider range of applications and user devices. The insights gained from this work can inform future advancements in LLM compression and optimization, ultimately expanding the reach and impact of large language models in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
CompactifAI: Extreme Compression of Large Language Models using Quantum-Inspired Tensor Networks
Andrei Tomut, Saeed S. Jahromi, Abhijoy Sarkar, Uygar Kurt, Sukhbinder Singh, Faysal Ishtiaq, Cesar Mu~noz, Prabdeep Singh Bajaj, Ali Elborady, Gianni del Bimbo, Mehrazin Alizadeh, David Montero, Pablo Martin-Ramiro, Muhammad Ibrahim, Oussama Tahiri Alaoui, John Malcolm, Samuel Mugel, Roman Orus
0
0
Large Language Models (LLMs) such as ChatGPT and LlaMA are advancing rapidly in generative Artificial Intelligence (AI), but their immense size poses significant challenges, such as huge training and inference costs, substantial energy demands, and limitations for on-site deployment. Traditional compression methods such as pruning, distillation, and low-rank approximation focus on reducing the effective number of neurons in the network, while quantization focuses on reducing the numerical precision of individual weights to reduce the model size while keeping the number of neurons fixed. While these compression methods have been relatively successful in practice, there is no compelling reason to believe that truncating the number of neurons is an optimal strategy. In this context, this paper introduces CompactifAI, an innovative LLM compression approach using quantum-inspired Tensor Networks that focuses on the model's correlation space instead, allowing for a more controlled, refined and interpretable model compression. Our method is versatile and can be implemented with - or on top of - other compression techniques. As a benchmark, we demonstrate that a combination of CompactifAI with quantization allows to reduce a 93% the memory size of LlaMA 7B, reducing also 70% the number of parameters, accelerating 50% the training and 25% the inference times of the model, and just with a small accuracy drop of 2% - 3%, going much beyond of what is achievable today by other compression techniques. Our methods also allow to perform a refined layer sensitivity profiling, showing that deeper layers tend to be more suitable for tensor network compression, which is compatible with recent observations on the ineffectiveness of those layers for LLM performance. Our results imply that standard LLMs are, in fact, heavily overparametrized, and do not need to be large at all.
5/14/2024
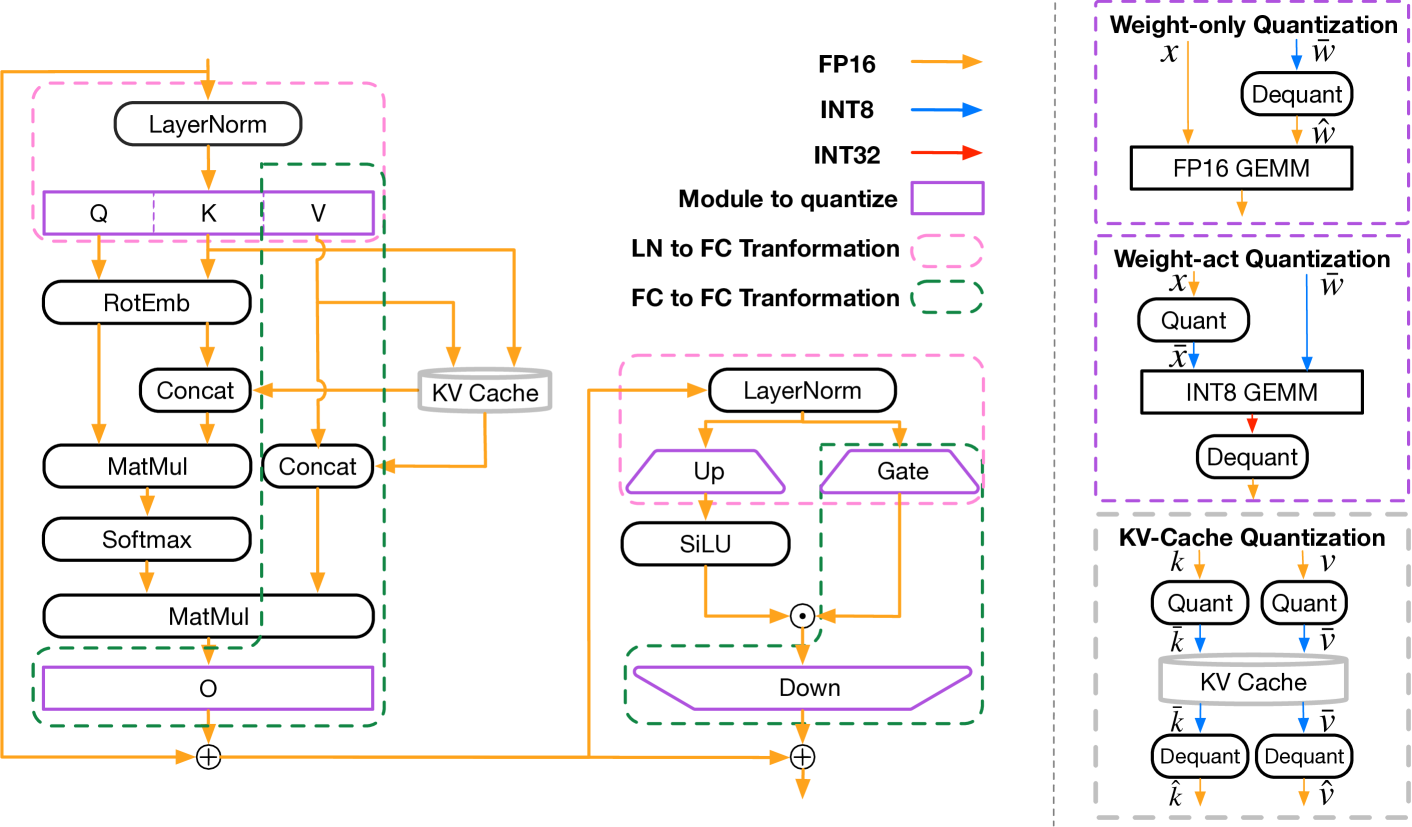
LLM-QBench: A Benchmark Towards the Best Practice for Post-training Quantization of Large Language Models
Ruihao Gong, Yang Yong, Shiqiao Gu, Yushi Huang, Yunchen Zhang, Xianglong Liu, Dacheng Tao
0
0
Recent advancements in large language models (LLMs) are propelling us toward artificial general intelligence, thanks to their remarkable emergent abilities and reasoning capabilities. However, the substantial computational and memory requirements of LLMs limit their widespread adoption. Quan- tization, a key compression technique, offers a viable solution to mitigate these demands by compressing and accelerating LLMs, albeit with poten- tial risks to model accuracy. Numerous studies have aimed to minimize the accuracy loss associated with quantization. However, the quantization configurations in these studies vary and may not be optimized for hard- ware compatibility. In this paper, we focus on identifying the most effective practices for quantizing LLMs, with the goal of balancing performance with computational efficiency. For a fair analysis, we develop a quantization toolkit LLMC, and design four crucial principles considering the inference efficiency, quantized accuracy, calibration cost, and modularization. By benchmarking on various models and datasets with over 500 experiments, three takeaways corresponding to calibration data, quantization algorithm, and quantization schemes are derived. Finally, a best practice of LLM PTQ pipeline is constructed. All the benchmark results and the toolkit can be found at https://github.com/ModelTC/llmc.
5/13/2024
🤔
Quantifying the Capabilities of LLMs across Scale and Precision
Sher Badshah, Hassan Sajjad
0
0
Scale is often attributed as one of the factors that cause an increase in the performance of LLMs, resulting in models with billion and trillion parameters. One of the limitations of such large models is the high computational requirements that limit their usage, deployment, and debugging in resource-constrained scenarios. Two commonly used alternatives to bypass these limitations are to use the smaller versions of LLMs (e.g. Llama 7B instead of Llama 70B) and lower the memory requirements by using quantization. While these approaches effectively address the limitation of resources, their impact on model performance needs thorough examination. In this study, we perform a comprehensive evaluation to investigate the effect of model scale and quantization on the performance. We experiment with two major families of open-source instruct models ranging from 7 billion to 70 billion parameters. Our extensive zero-shot experiments across various tasks including natural language understanding, reasoning, misinformation detection, and hallucination reveal that larger models generally outperform their smaller counterparts, suggesting that scale remains an important factor in enhancing performance. We found that larger models show exceptional resilience to precision reduction and can maintain high accuracy even at 4-bit quantization for numerous tasks and they serve as a better solution than using smaller models at high precision under similar memory requirements.
5/9/2024
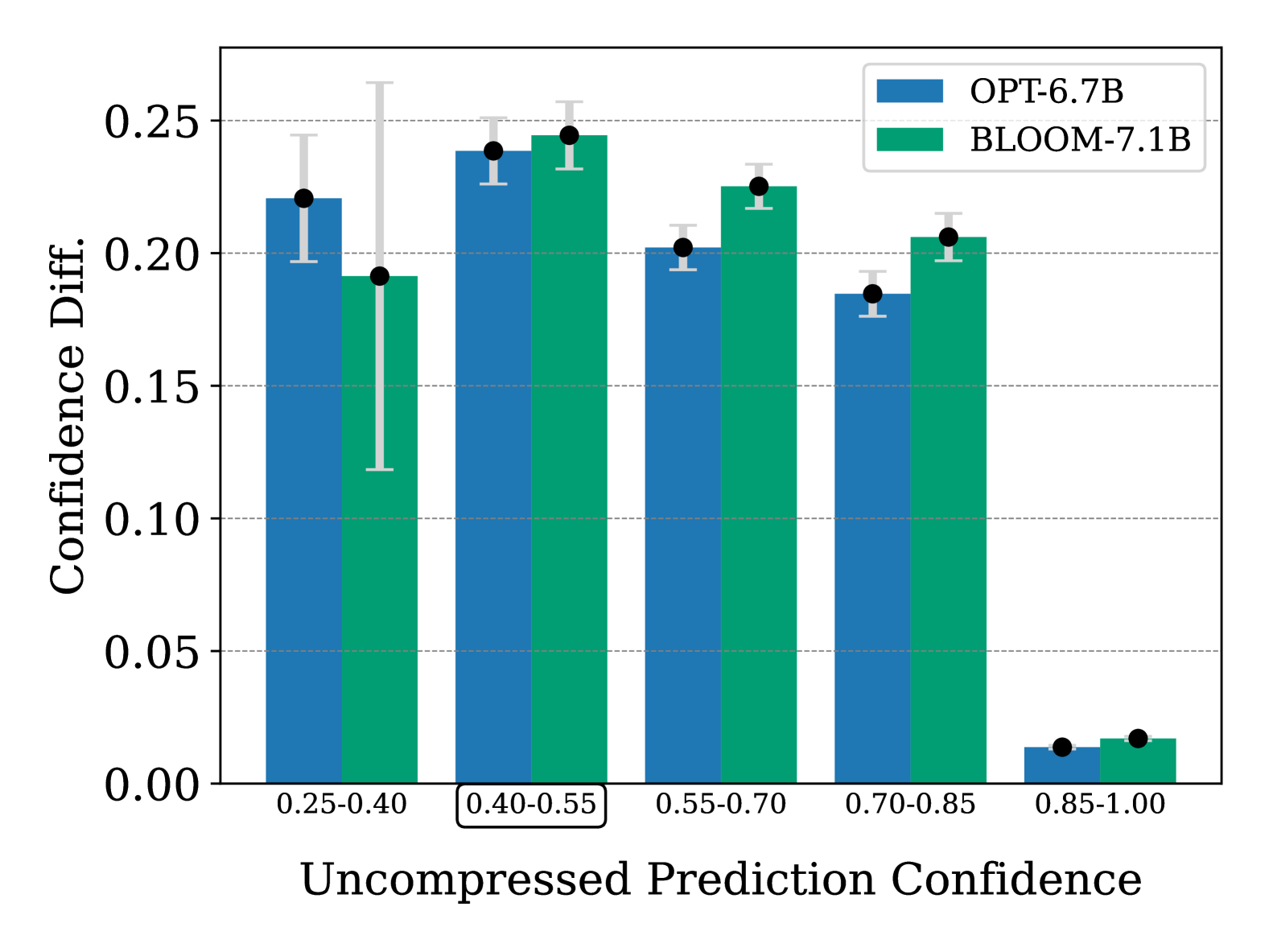
When Quantization Affects Confidence of Large Language Models?
Irina Proskurina, Luc Brun, Guillaume Metzler, Julien Velcin
0
0
Recent studies introduced effective compression techniques for Large Language Models (LLMs) via post-training quantization or low-bit weight representation. Although quantized weights offer storage efficiency and allow for faster inference, existing works have indicated that quantization might compromise performance and exacerbate biases in LLMs. This study investigates the confidence and calibration of quantized models, considering factors such as language model type and scale as contributors to quantization loss. Firstly, we reveal that quantization with GPTQ to 4-bit results in a decrease in confidence regarding true labels, with varying impacts observed among different language models. Secondly, we observe fluctuations in the impact on confidence across different scales. Finally, we propose an explanation for quantization loss based on confidence levels, indicating that quantization disproportionately affects samples where the full model exhibited low confidence levels in the first place.
5/2/2024