CompanyKG: A Large-Scale Heterogeneous Graph for Company Similarity Quantification

0

Sign in to get full access
Overview
- This research paper introduces CompanyKG, a large-scale heterogeneous graph that can be used to quantify the similarity between companies.
- The graph contains a wealth of information about companies, including their products, services, leadership, and financial performance.
- The authors demonstrate how this graph can be used to identify similar companies and make informed business decisions.
Plain English Explanation
The researchers have created a comprehensive database, or "knowledge graph," that contains a vast amount of information about companies. This graph includes details about a company's products, services, leadership team, financial performance, and much more. By analyzing the connections and relationships within this graph, the researchers can determine how similar different companies are to one another.
This type of analysis could be useful for a variety of business applications, such as identifying potential partners or competitors, answering questions about a company's market position, or even predicting a company's future performance. The knowledge graph approach can provide a more holistic and data-driven understanding of the business landscape compared to traditional methods.
Technical Explanation
The key innovation of this research is the creation of CompanyKG, a large-scale heterogeneous graph that integrates a variety of data sources related to companies. This graph contains information about a company's products, services, leadership, financial performance, and more. By representing this data in a graph structure, the researchers can leverage powerful graph analysis techniques to identify similarities between companies.
The authors demonstrate how CompanyKG can be used to quantify company similarity through a series of experiments. They show that their approach outperforms traditional methods, such as those based on industry classifications or financial ratios. The graph-based approach is able to capture more nuanced and multifaceted relationships between companies.
Critical Analysis
The paper provides a comprehensive and well-designed study, demonstrating the potential value of knowledge graphs for business applications. However, the authors acknowledge several limitations and areas for further research. For example, the graph is currently limited to a specific geographic region and industry sector, and the data sources used may not be fully comprehensive or up-to-date.
Additionally, while the graph-based approach shows promising results, there may be concerns around the uncertainty and reliability of the inferences drawn from the graph. The authors do not delve deeply into these potential issues, which would be an important area for future work.
Conclusion
Overall, this research presents a novel and compelling application of knowledge graph technology in the business domain. The CompanyKG resource provides a rich and multi-faceted representation of companies that can enable more informed decision-making. While there are some limitations to the current implementation, the authors have demonstrated the potential for knowledge graphs to transform how we understand and analyze the business landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CompanyKG: A Large-Scale Heterogeneous Graph for Company Similarity Quantification
Lele Cao, Vilhelm von Ehrenheim, Mark Granroth-Wilding, Richard Anselmo Stahl, Andrew McCornack, Armin Catovic, Dhiana Deva Cavacanti Rocha
In the investment industry, it is often essential to carry out fine-grained company similarity quantification for a range of purposes, including market mapping, competitor analysis, and mergers and acquisitions. We propose and publish a knowledge graph, named CompanyKG, to represent and learn diverse company features and relations. Specifically, 1.17 million companies are represented as nodes enriched with company description embeddings; and 15 different inter-company relations result in 51.06 million weighted edges. To enable a comprehensive assessment of methods for company similarity quantification, we have devised and compiled three evaluation tasks with annotated test sets: similarity prediction, competitor retrieval and similarity ranking. We present extensive benchmarking results for 11 reproducible predictive methods categorized into three groups: node-only, edge-only, and node+edge. To the best of our knowledge, CompanyKG is the first large-scale heterogeneous graph dataset originating from a real-world investment platform, tailored for quantifying inter-company similarity.
Read more6/11/2024

0
Docs2KG: Unified Knowledge Graph Construction from Heterogeneous Documents Assisted by Large Language Models
Qiang Sun, Yuanyi Luo, Wenxiao Zhang, Sirui Li, Jichunyang Li, Kai Niu, Xiangrui Kong, Wei Liu
Even for a conservative estimate, 80% of enterprise data reside in unstructured files, stored in data lakes that accommodate heterogeneous formats. Classical search engines can no longer meet information seeking needs, especially when the task is to browse and explore for insight formulation. In other words, there are no obvious search keywords to use. Knowledge graphs, due to their natural visual appeals that reduce the human cognitive load, become the winning candidate for heterogeneous data integration and knowledge representation. In this paper, we introduce Docs2KG, a novel framework designed to extract multimodal information from diverse and heterogeneous unstructured documents, including emails, web pages, PDF files, and Excel files. Dynamically generates a unified knowledge graph that represents the extracted key information, Docs2KG enables efficient querying and exploration of document data lakes. Unlike existing approaches that focus on domain-specific data sources or pre-designed schemas, Docs2KG offers a flexible and extensible solution that can adapt to various document structures and content types. The proposed framework unifies data processing supporting a multitude of downstream tasks with improved domain interpretability. Docs2KG is publicly accessible at https://docs2kg.ai4wa.com, and a demonstration video is available at https://docs2kg.ai4wa.com/Video.
Read more6/6/2024
0
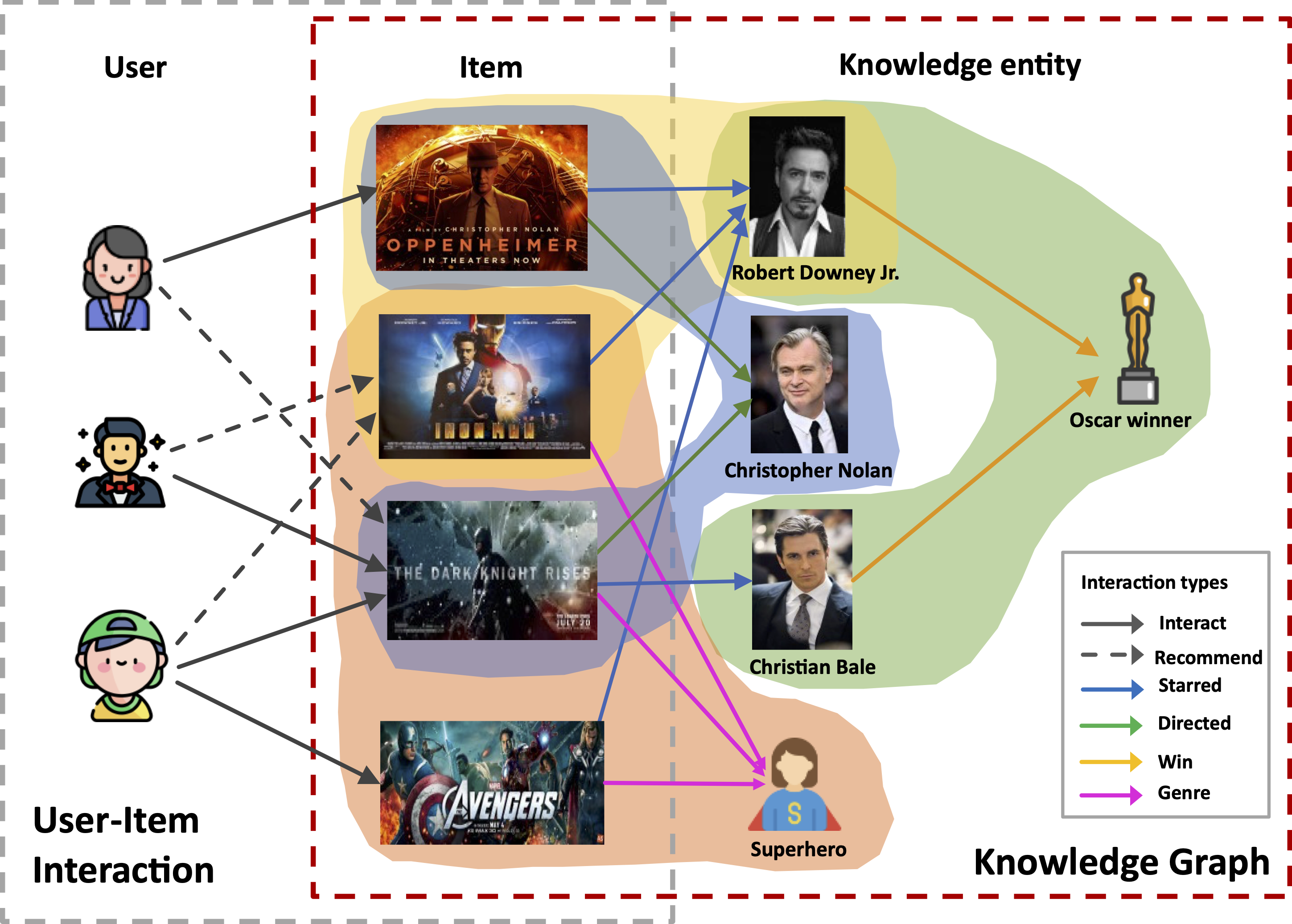
Heterogeneous Hypergraph Embedding for Recommendation Systems
Darnbi Sakong, Viet Hung Vu, Thanh Trung Huynh, Phi Le Nguyen, Hongzhi Yin, Quoc Viet Hung Nguyen, Thanh Tam Nguyen
Recent advancements in recommender systems have focused on integrating knowledge graphs (KGs) to leverage their auxiliary information. The core idea of KG-enhanced recommenders is to incorporate rich semantic information for more accurate recommendations. However, two main challenges persist: i) Neglecting complex higher-order interactions in the KG-based user-item network, potentially leading to sub-optimal recommendations, and ii) Dealing with the heterogeneous modalities of input sources, such as user-item bipartite graphs and KGs, which may introduce noise and inaccuracies. To address these issues, we present a novel Knowledge-enhanced Heterogeneous Hypergraph Recommender System (KHGRec). KHGRec captures group-wise characteristics of both the interaction network and the KG, modeling complex connections in the KG. Using a collaborative knowledge heterogeneous hypergraph (CKHG), it employs two hypergraph encoders to model group-wise interdependencies and ensure explainability. Additionally, it fuses signals from the input graphs with cross-view self-supervised learning and attention mechanisms. Extensive experiments on four real-world datasets show our model's superiority over various state-of-the-art baselines, with an average 5.18% relative improvement. Additional tests on noise resilience, missing data, and cold-start problems demonstrate the robustness of our KHGRec framework. Our model and evaluation datasets are publicly available at url{https://github.com/viethungvu1998/KHGRec}.
Read more7/8/2024
0
Survey on Embedding Models for Knowledge Graph and its Applications
Manita Pote
Knowledge Graph (KG) is a graph based data structure to represent facts of the world where nodes represent real world entities or abstract concept and edges represent relation between the entities. Graph as representation for knowledge has several drawbacks like data sparsity, computational complexity and manual feature engineering. Knowledge Graph embedding tackles the drawback by representing entities and relation in low dimensional vector space by capturing the semantic relation between them. There are different KG embedding models. Here, we discuss translation based and neural network based embedding models which differ based on semantic property, scoring function and architecture they use. Further, we discuss application of KG in some domains that use deep learning models and leverage social media data.
Read more4/16/2024