Docs2KG: Unified Knowledge Graph Construction from Heterogeneous Documents Assisted by Large Language Models

0

Sign in to get full access
Overview
- This paper presents Docs2KG, a framework for constructing a unified knowledge graph from heterogeneous documents using large language models.
- Docs2KG aims to extract structured knowledge from unstructured and diverse data sources, such as scientific papers, websites, and databases.
- The framework leverages the capabilities of large language models to perform various tasks, including entity recognition, relation extraction, and knowledge graph generation.
Plain English Explanation
Docs2KG is a system that helps create a comprehensive knowledge graph from a wide range of document sources. A knowledge graph is a way of organizing information into a structured format, like a web of connected data points. This is useful for tasks like answering questions, making recommendations, or understanding complex topics.
Traditional methods of building knowledge graphs can be time-consuming and require a lot of manual effort. Docs2KG uses powerful language models, which are AI systems trained on massive amounts of text data, to automate many of the steps involved. These models can identify important entities (like people, places, or concepts) and the relationships between them within the documents.
By combining the insights from multiple, diverse sources like academic papers, websites, and databases, Docs2KG can construct a more complete and accurate knowledge graph. This could be beneficial for applications like leveraging large language models for semantic query processing, cross-data knowledge graph construction, or building theme-specific knowledge graphs.
Technical Explanation
The Docs2KG framework consists of several key components:
- Data Ingestion: Docs2KG can ingest a wide variety of document types, including scientific papers, web pages, and structured databases.
- Entity and Relation Extraction: Large language models are used to identify relevant entities (e.g., people, organizations, concepts) and the relationships between them within the input documents.
- Knowledge Graph Construction: The extracted entities and relations are then used to build a unified knowledge graph, which represents the structured information from the heterogeneous sources.
- Knowledge Graph Refinement: The initial knowledge graph is further refined and expanded using techniques like coreference resolution, entity linking, and relation normalization.
The authors evaluate Docs2KG on several benchmark datasets and demonstrate its ability to outperform traditional knowledge graph construction methods, especially when dealing with diverse, unstructured data sources. The framework's modular design also allows for easy integration with other knowledge management tools and uncertainty management techniques.
Critical Analysis
The Docs2KG paper presents a promising approach to automating knowledge graph construction from heterogeneous documents. The authors have acknowledged several limitations and areas for future work:
- The performance of the framework is dependent on the quality and capabilities of the underlying language models, which may not always be able to accurately extract all relevant entities and relations.
- The knowledge graph construction process can be further improved by incorporating more advanced techniques for resolving ambiguities, handling noisy data, and ensuring the consistency and completeness of the final knowledge graph.
- The evaluation of Docs2KG was conducted on a limited set of datasets, and its performance on real-world, large-scale document collections remains to be explored.
Additionally, while the paper demonstrates the potential of Docs2KG, there are some concerns that could be addressed in future research:
- The framework's ability to handle dynamic, evolving knowledge graphs and update the knowledge base over time is not discussed.
- The scalability and computational efficiency of the Docs2KG system when dealing with massive document repositories could be an area of further investigation.
- The ethical and privacy implications of constructing comprehensive knowledge graphs from diverse data sources should be carefully considered.
Conclusion
The Docs2KG framework presented in this paper represents a significant advancement in the field of knowledge graph construction. By leveraging the capabilities of large language models, Docs2KG can automate the process of extracting structured knowledge from heterogeneous, unstructured documents, enabling the creation of more comprehensive and accurate knowledge graphs.
The ability to integrate diverse data sources and the modular design of Docs2KG make it a promising tool for a wide range of applications, from semantic query processing to cross-data knowledge graph construction and theme-specific knowledge graph generation. As the authors continue to refine and expand the framework, it could become an invaluable resource for researchers, businesses, and organizations seeking to harness the power of structured knowledge in a rapidly evolving digital landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Docs2KG: Unified Knowledge Graph Construction from Heterogeneous Documents Assisted by Large Language Models
Qiang Sun, Yuanyi Luo, Wenxiao Zhang, Sirui Li, Jichunyang Li, Kai Niu, Xiangrui Kong, Wei Liu
Even for a conservative estimate, 80% of enterprise data reside in unstructured files, stored in data lakes that accommodate heterogeneous formats. Classical search engines can no longer meet information seeking needs, especially when the task is to browse and explore for insight formulation. In other words, there are no obvious search keywords to use. Knowledge graphs, due to their natural visual appeals that reduce the human cognitive load, become the winning candidate for heterogeneous data integration and knowledge representation. In this paper, we introduce Docs2KG, a novel framework designed to extract multimodal information from diverse and heterogeneous unstructured documents, including emails, web pages, PDF files, and Excel files. Dynamically generates a unified knowledge graph that represents the extracted key information, Docs2KG enables efficient querying and exploration of document data lakes. Unlike existing approaches that focus on domain-specific data sources or pre-designed schemas, Docs2KG offers a flexible and extensible solution that can adapt to various document structures and content types. The proposed framework unifies data processing supporting a multitude of downstream tasks with improved domain interpretability. Docs2KG is publicly accessible at https://docs2kg.ai4wa.com, and a demonstration video is available at https://docs2kg.ai4wa.com/Video.
Read more6/6/2024

0
iText2KG: Incremental Knowledge Graphs Construction Using Large Language Models
Yassir Lairgi, Ludovic Moncla, R'emy Cazabet, Khalid Benabdeslem, Pierre Cl'eau
Most available data is unstructured, making it challenging to access valuable information. Automatically building Knowledge Graphs (KGs) is crucial for structuring data and making it accessible, allowing users to search for information effectively. KGs also facilitate insights, inference, and reasoning. Traditional NLP methods, such as named entity recognition and relation extraction, are key in information retrieval but face limitations, including the use of predefined entity types and the need for supervised learning. Current research leverages large language models' capabilities, such as zero- or few-shot learning. However, unresolved and semantically duplicated entities and relations still pose challenges, leading to inconsistent graphs and requiring extensive post-processing. Additionally, most approaches are topic-dependent. In this paper, we propose iText2KG, a method for incremental, topic-independent KG construction without post-processing. This plug-and-play, zero-shot method is applicable across a wide range of KG construction scenarios and comprises four modules: Document Distiller, Incremental Entity Extractor, Incremental Relation Extractor, and Graph Integrator and Visualization. Our method demonstrates superior performance compared to baseline methods across three scenarios: converting scientific papers to graphs, websites to graphs, and CVs to graphs.
Read more9/6/2024
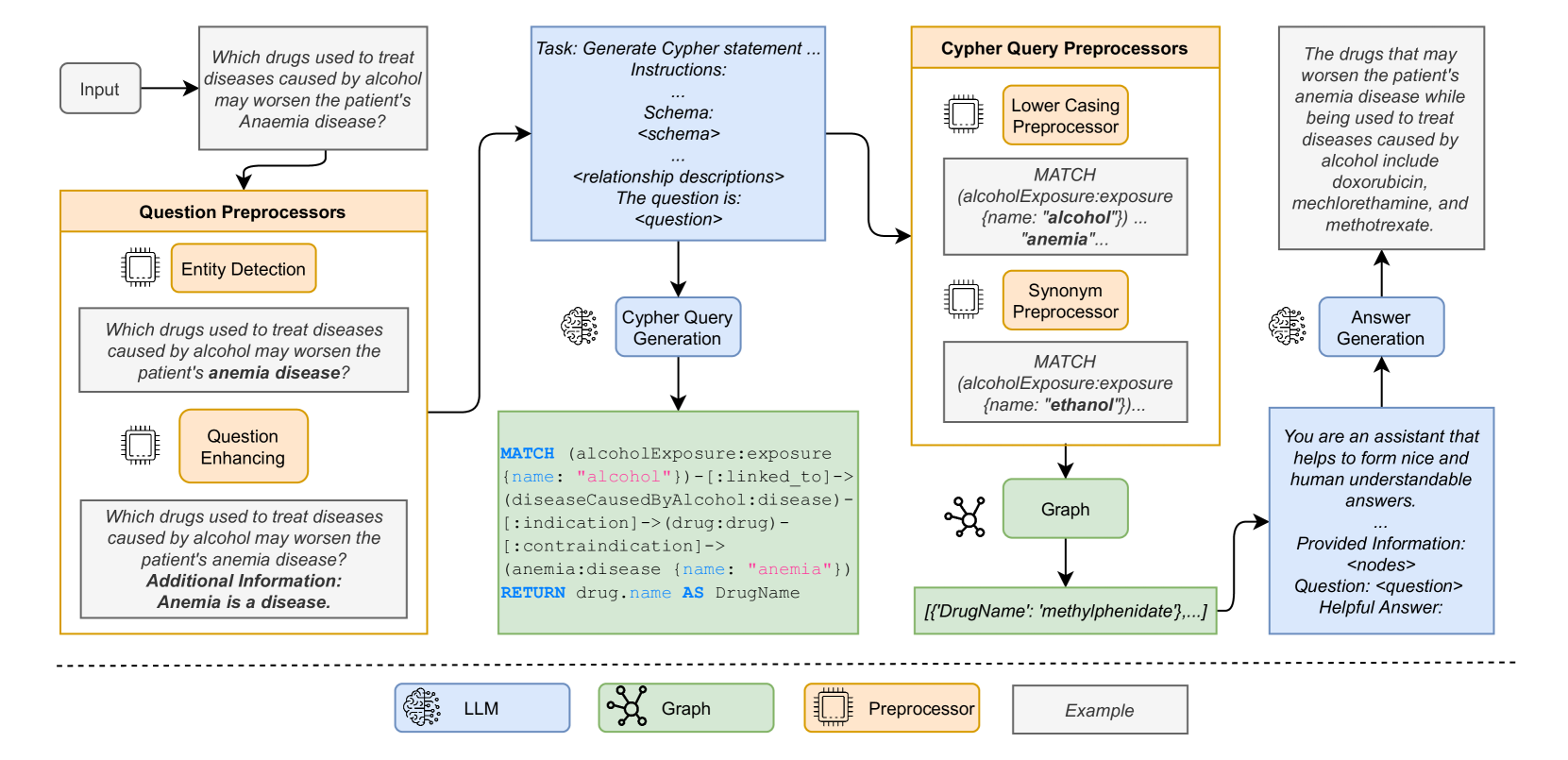
0
Fact Finder -- Enhancing Domain Expertise of Large Language Models by Incorporating Knowledge Graphs
Daniel Steinigen, Roman Teucher, Timm Heine Ruland, Max Rudat, Nicolas Flores-Herr, Peter Fischer, Nikola Milosevic, Christopher Schymura, Angelo Ziletti
Recent advancements in Large Language Models (LLMs) have showcased their proficiency in answering natural language queries. However, their effectiveness is hindered by limited domain-specific knowledge, raising concerns about the reliability of their responses. We introduce a hybrid system that augments LLMs with domain-specific knowledge graphs (KGs), thereby aiming to enhance factual correctness using a KG-based retrieval approach. We focus on a medical KG to demonstrate our methodology, which includes (1) pre-processing, (2) Cypher query generation, (3) Cypher query processing, (4) KG retrieval, and (5) LLM-enhanced response generation. We evaluate our system on a curated dataset of 69 samples, achieving a precision of 78% in retrieving correct KG nodes. Our findings indicate that the hybrid system surpasses a standalone LLM in accuracy and completeness, as verified by an LLM-as-a-Judge evaluation method. This positions the system as a promising tool for applications that demand factual correctness and completeness, such as target identification -- a critical process in pinpointing biological entities for disease treatment or crop enhancement. Moreover, its intuitive search interface and ability to provide accurate responses within seconds make it well-suited for time-sensitive, precision-focused research contexts. We publish the source code together with the dataset and the prompt templates used.
Read more8/7/2024
💬
0
Synergizing Knowledge Graphs with Large Language Models: A Comprehensive Review and Future Prospects
DaiFeng Li, Fan Xu
Recent advancements have witnessed the ascension of Large Language Models (LLMs), endowed with prodigious linguistic capabilities, albeit marred by shortcomings including factual inconsistencies and opacity. Conversely, Knowledge Graphs (KGs) harbor verifiable knowledge and symbolic reasoning prowess, thereby complementing LLMs' deficiencies. Against this backdrop, the synergy between KGs and LLMs emerges as a pivotal research direction. Our contribution in this paper is a comprehensive dissection of the latest developments in integrating KGs with LLMs. Through meticulous analysis of their confluence points and methodologies, we introduce a unifying framework designed to elucidate and stimulate further exploration among scholars engaged in cognate disciplines. This framework serves a dual purpose: it consolidates extant knowledge while simultaneously delineating novel avenues for real-world deployment, thereby amplifying the translational impact of academic research.
Read more7/29/2024