Comparative Analysis Of Discriminative Deep Learning-Based Noise Reduction Methods In Low SNR Scenarios

0

Sign in to get full access
Overview
- This paper provides a comparative analysis of different deep learning-based noise reduction methods in low signal-to-noise ratio (SNR) scenarios.
- The researchers evaluated the performance of various discriminative deep learning models for speech enhancement and noise reduction.
- The analysis focused on scenarios with low SNR, which are challenging for traditional noise reduction techniques.
Plain English Explanation
In this research, the authors examined different machine learning models that can be used to remove unwanted noise from audio signals. This is an important problem, as noisy audio can make it difficult to clearly hear what is being said, especially in low SNR conditions.
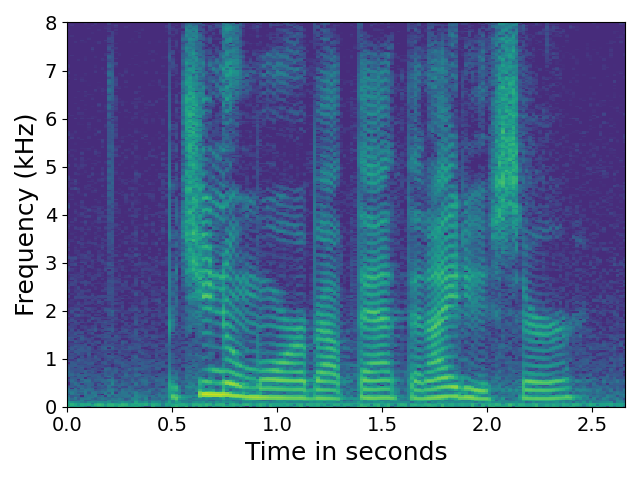
The researchers tested several deep learning models that are designed to reduce noise and enhance the desired speech signal. They compared the performance of these models in scenarios where the audio had a low SNR, meaning the noise was relatively loud compared to the speech.
Evaluating noise reduction techniques in low SNR conditions is important because this is a challenging scenario for many traditional noise reduction methods. The deep learning models tested in this paper were able to improve the quality of the audio even when the noise was quite loud compared to the speech signal.
Technical Explanation
The paper evaluated the performance of several discriminative deep learning models for speech enhancement and noise reduction in low SNR scenarios. The models included:
- Convolutional neural network (CNN) based models
- Recurrent neural network (RNN) based models
- Transformer-based models
The researchers used standard speech enhancement datasets to train and evaluate the models. They compared the models' performance on objective metrics like perceptual evaluation of speech quality (PESQ) and signal-to-distortion ratio (SDR) in low SNR conditions (0 dB, -5 dB, and -10 dB).
The results showed that the transformer-based models generally outperformed the CNN and RNN-based approaches in the low SNR scenarios. The authors hypothesize that the global receptive field and attention mechanisms of transformers allow them to better capture the complex relationships between speech and noise in challenging acoustic conditions.
Critical Analysis
The paper provides a thorough and well-designed comparison of several state-of-the-art deep learning models for speech enhancement. The evaluation in low SNR conditions is particularly valuable, as this is an area where traditional noise reduction methods often struggle.
One potential limitation is that the study only evaluated the models on simulated noisy speech data, rather than real-world recordings. While this allows for controlled experiments, the performance on actual noisy recordings may differ.
Additionally, the paper does not delve into the computational complexity and inference speed of the different models, which are important practical considerations for real-world deployments. Further research could explore these aspects and how they relate to the noise reduction performance.
Overall, this study offers valuable insights into the relative strengths of discriminative deep learning approaches for speech enhancement in challenging acoustic environments. The findings can help guide the development of more robust and effective noise reduction solutions.
Conclusion
This research paper presents a comparative analysis of various deep learning-based noise reduction methods in low SNR scenarios. The authors found that transformer-based models generally outperformed CNN and RNN-based approaches in these challenging conditions, highlighting the potential of attention mechanisms for complex speech enhancement tasks.
The findings of this study can inform the development of more effective noise reduction systems, which have important applications in areas like voice assistants, teleconferencing, and hearing aids. Further research is needed to evaluate the models on real-world data and explore practical considerations like computational cost and inference speed.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Comparative Analysis Of Discriminative Deep Learning-Based Noise Reduction Methods In Low SNR Scenarios
Shrishti Saha Shetu, Emanuel A. P. Habets, Andreas Brendel
In this study, we conduct a comparative analysis of deep learning-based noise reduction methods in low signal-to-noise ratio (SNR) scenarios. Our investigation primarily focuses on five key aspects: The impact of training data, the influence of various loss functions, the effectiveness of direct and indirect speech estimation techniques, the efficacy of masking, mapping, and deep filtering methodologies, and the exploration of different model capacities on noise reduction performance and speech quality. Through comprehensive experimentation, we provide insights into the strengths, weaknesses, and applicability of these methods in low SNR environments. The findings derived from our analysis are intended to assist both researchers and practitioners in selecting better techniques tailored to their specific applications within the domain of low SNR noise reduction.
Read more8/28/2024
0
Reassessing Noise Augmentation Methods in the Context of Adversarial Speech
Karla Pizzi, Mat'ias P. Pizarro B, Asja Fischer
In this study, we investigate if noise-augmented training can concurrently improve adversarial robustness in automatic speech recognition (ASR) systems. We conduct a comparative analysis of the adversarial robustness of four different state-of-the-art ASR architectures, where each of the ASR architectures is trained under three different augmentation conditions: one subject to background noise, speed variations, and reverberations, another subject to speed variations only, and a third without any form of data augmentation. The results demonstrate that noise augmentation not only improves model performance on noisy speech but also the model's robustness to adversarial attacks.
Read more9/4/2024

0
Improved Remixing Process for Domain Adaptation-Based Speech Enhancement by Mitigating Data Imbalance in Signal-to-Noise Ratio
Li Li, Shogo Seki
RemixIT and Remixed2Remixed are domain adaptation-based speech enhancement (DASE) methods that use a teacher model trained in full supervision to generate pseudo-paired data by remixing the outputs of the teacher model. The student model for enhancing real-world recorded signals is trained using the pseudo-paired data without ground truth. Since the noisy signals are recorded in natural environments, the dataset inevitably suffers data imbalance in some acoustic properties, leading to subpar performance for the underrepresented data. The signal-to-noise ratio (SNR), inherently balanced in supervised learning, is a prime example. In this paper, we provide empirical evidence that the SNR of pseudo data has a significant impact on model performance using the dataset of the CHiME-7 UDASE task, highlighting the importance of balanced SNR in DASE. Furthermore, we propose adopting curriculum learning to encompass a broad range of SNRs to boost performance for underrepresented data.
Read more6/21/2024
0
Using Speech Foundational Models in Loss Functions for Hearing Aid Speech Enhancement
Robert Sutherland, George Close, Thomas Hain, Stefan Goetze, Jon Barker
Machine learning techniques are an active area of research for speech enhancement for hearing aids, with one particular focus on improving the intelligibility of a noisy speech signal. Recent work has shown that feature encodings from self-supervised speech representation models can effectively capture speech intelligibility. In this work, it is shown that the distance between self-supervised speech representations of clean and noisy speech correlates more strongly with human intelligibility ratings than other signal-based metrics. Experiments show that training a speech enhancement model using this distance as part of a loss function improves the performance over using an SNR-based loss function, demonstrated by an increase in HASPI, STOI, PESQ and SI-SNR scores. This method takes inference of a high parameter count model only at training time, meaning the speech enhancement model can remain smaller, as is required for hearing aids.
Read more7/19/2024