SNR-Progressive Model with Harmonic Compensation for Low-SNR Speech Enhancement

0
📈
Sign in to get full access
Overview
- This paper proposes a new deep neural network (DNN) model for speech enhancement (SE) that performs better in low signal-to-noise ratio (SNR) conditions.
- The key innovations are:
- Reliable pitch estimation from intermediate outputs to retain more speech components.
- Effective harmonic compensation mechanism for better harmonic recovery.
Plain English Explanation
The paper tackles the challenge of deep neural network (DNN)-based speech enhancement performing poorly in noisy environments with low signal-to-noise ratios (SNRs). To address this, the researchers developed a new DNN model that uses a couple of clever techniques:
-
Pitch Estimation: The model estimates the pitch (fundamental frequency) of the speech more accurately by using intermediate outputs, which capture more of the speech details than just the final output. This helps retain important speech components that would otherwise be lost.
-
Harmonic Compensation: The model also includes a mechanism to better recover the harmonic structure of the speech, which is crucial for maintaining speech quality. Harmonics are the frequencies that are multiples of the pitch, and restoring them helps the speech sound more natural.
These innovations allow the model to perform speech enhancement much better than previous approaches, especially in challenging low-SNR conditions. The researchers demonstrate the effectiveness of their model through extensive experiments and show that it ranked first in a recent speech extraction challenge.
Technical Explanation
The key technical components of the proposed speech enhancement model are:
-
SNR-Progressive Architecture: The model is designed to progressively improve speech quality by conditioning the enhancement on the input SNR. This allows the model to focus its capacity on the most challenging low-SNR cases.
-
Reliable Pitch Estimation: The model estimates the pitch (fundamental frequency) of the speech using the intermediate output of the network, which retains more speech details than just the final output. This provides a higher-quality pitch estimate than using the noisy input directly.
-
Harmonic Compensation: Building on the reliable pitch estimation, the model introduces an effective harmonic compensation mechanism to better recover the harmonic structure of the speech. This is crucial for maintaining high-quality, natural-sounding speech.
The researchers extensively evaluated the model on a variety of speech enhancement benchmarks and found that it outperformed state-of-the-art approaches, especially in low-SNR conditions. Additionally, a multi-modal speech extraction system based on the proposed model ranked first in the recent ICASSP 2024 MISP Challenge.
Critical Analysis
The paper makes a strong technical contribution by addressing a key limitation of existing DNN-based speech enhancement models - their degraded performance in low-SNR environments. The proposed techniques of reliable pitch estimation and harmonic compensation are well-designed and effectively improve speech quality in challenging noisy conditions.
However, the paper does not discuss the potential computational cost or real-time processing requirements of the model, which could be important considerations for practical speech enhancement applications, especially on resource-constrained edge devices.
Additionally, while the model demonstrates impressive performance on standard benchmarks, it would be valuable to see how it compares to other recent advances in noise-aware speech enhancement and domain adaptation-based speech enhancement techniques.
Conclusion
This paper presents a novel DNN-based speech enhancement model that significantly improves speech quality in low-SNR conditions. The key innovations of reliable pitch estimation and effective harmonic compensation allow the model to better preserve the important details of the speech signal, even when it is heavily corrupted by noise.
The strong performance of the proposed model, including its first-place finish in a recent speech extraction challenge, demonstrates its potential to advance the state-of-the-art in real-world speech enhancement applications. Further research into the model's computational efficiency and comparison to other recent techniques could help solidify its position as a leading solution for robust speech enhancement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
SNR-Progressive Model with Harmonic Compensation for Low-SNR Speech Enhancement
Zhongshu Hou, Tong Lei, Qinwen Hu, Zhanzhong Cao, Ming Tang, Jing Lu
Despite significant progress made in the last decade, deep neural network (DNN) based speech enhancement (SE) still faces the challenge of notable degradation in the quality of recovered speech under low signal-to-noise ratio (SNR) conditions. In this letter, we propose an SNR-progressive speech enhancement model with harmonic compensation for low-SNR SE. Reliable pitch estimation is obtained from the intermediate output, which has the benefit of retaining more speech components than the coarse estimate while possessing a significant higher SNR than the input noisy speech. An effective harmonic compensation mechanism is introduced for better harmonic recovery. Extensive ex-periments demonstrate the advantage of our proposed model. A multi-modal speech extraction system based on the proposed backbone model ranks first in the ICASSP 2024 MISP Challenge: https://mispchallenge.github.io/mispchallenge2023/index.html.
Read more8/20/2024

0
Diffusion-based Speech Enhancement with Schrodinger Bridge and Symmetric Noise Schedule
Siyi Wang, Siyi Liu, Andrew Harper, Paul Kendrick, Mathieu Salzmann, Milos Cernak
Recently, diffusion-based generative models have demonstrated remarkable performance in speech enhancement tasks. However, these methods still encounter challenges, including the lack of structural information and poor performance in low Signal-to-Noise Ratio (SNR) scenarios. To overcome these challenges, we propose the Schroodinger Bridge-based Speech Enhancement (SBSE) method, which learns the diffusion processes directly between the noisy input and the clean distribution, unlike conventional diffusion-based speech enhancement systems that learn data to Gaussian distributions. To enhance performance in extremely noisy conditions, we introduce a two-stage system incorporating ratio mask information into the diffusion-based generative model. Our experimental results show that our proposed SBSE method outperforms all the baseline models and achieves state-of-the-art performance, especially in low SNR conditions. Importantly, only a few inference steps are required to achieve the best result.
Read more9/16/2024
0
Using Speech Foundational Models in Loss Functions for Hearing Aid Speech Enhancement
Robert Sutherland, George Close, Thomas Hain, Stefan Goetze, Jon Barker
Machine learning techniques are an active area of research for speech enhancement for hearing aids, with one particular focus on improving the intelligibility of a noisy speech signal. Recent work has shown that feature encodings from self-supervised speech representation models can effectively capture speech intelligibility. In this work, it is shown that the distance between self-supervised speech representations of clean and noisy speech correlates more strongly with human intelligibility ratings than other signal-based metrics. Experiments show that training a speech enhancement model using this distance as part of a loss function improves the performance over using an SNR-based loss function, demonstrated by an increase in HASPI, STOI, PESQ and SI-SNR scores. This method takes inference of a high parameter count model only at training time, meaning the speech enhancement model can remain smaller, as is required for hearing aids.
Read more7/19/2024
0
Bridging the Gap: Integrating Pre-trained Speech Enhancement and Recognition Models for Robust Speech Recognition
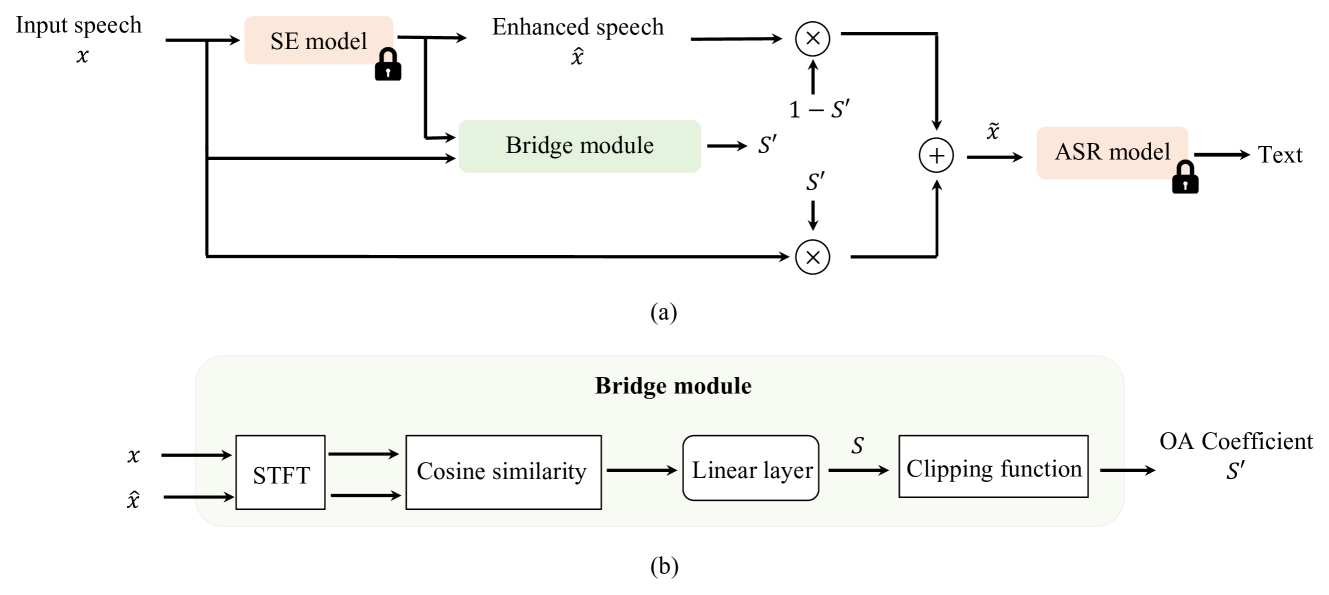
Kuan-Chen Wang, You-Jin Li, Wei-Lun Chen, Yu-Wen Chen, Yi-Ching Wang, Ping-Cheng Yeh, Chao Zhang, Yu Tsao
Noise robustness is critical when applying automatic speech recognition (ASR) in real-world scenarios. One solution involves the used of speech enhancement (SE) models as the front end of ASR. However, neural network-based (NN-based) SE often introduces artifacts into the enhanced signals and harms ASR performance, particularly when SE and ASR are independently trained. Therefore, this study introduces a simple yet effective SE post-processing technique to address the gap between various pre-trained SE and ASR models. A bridge module, which is a lightweight NN, is proposed to evaluate the signal-level information of the speech signal. Subsequently, using the signal-level information, the observation addition technique is applied to effectively reduce the shortcomings of SE. The experimental results demonstrate the success of our method in integrating diverse pre-trained SE and ASR models, considerably boosting the ASR robustness. Crucially, no prior knowledge of the ASR or speech contents is required during the training or inference stages. Moreover, the effectiveness of this approach extends to different datasets without necessitating the fine-tuning of the bridge module, ensuring efficiency and improved generalization.
Read more6/19/2024