Using Speech Foundational Models in Loss Functions for Hearing Aid Speech Enhancement

0
Sign in to get full access
Overview
- This paper explores the use of speech foundational models in loss functions for hearing aid speech enhancement.
- The research was supported by the Centre for Doctoral Training in Speech and Language Technologies (SLT) and their Applications, the EPSRC Clarity Project, and WS Audiology and Toshiba.
Plain English Explanation
The paper investigates using advanced AI models trained on a large amount of speech data (called "speech foundational models") to help improve the quality of speech enhancement for hearing aids. Speech enhancement is the process of taking a recording of speech and removing background noise or other distortions to make the speech clearer and easier to understand.
The researchers wanted to see if they could use the knowledge and capabilities of these powerful speech models to design better loss functions - the mathematical formulas that guide the training process of the speech enhancement algorithms. The goal was to create speech enhancement systems that could better preserve the natural qualities of the original speech signal, leading to improved intelligibility and listening experience for hearing aid users.
By leveraging the sophisticated speech understanding capabilities of these foundational models, the researchers hoped to develop more effective speech enhancement techniques that could ultimately benefit people with hearing impairments.
Technical Explanation
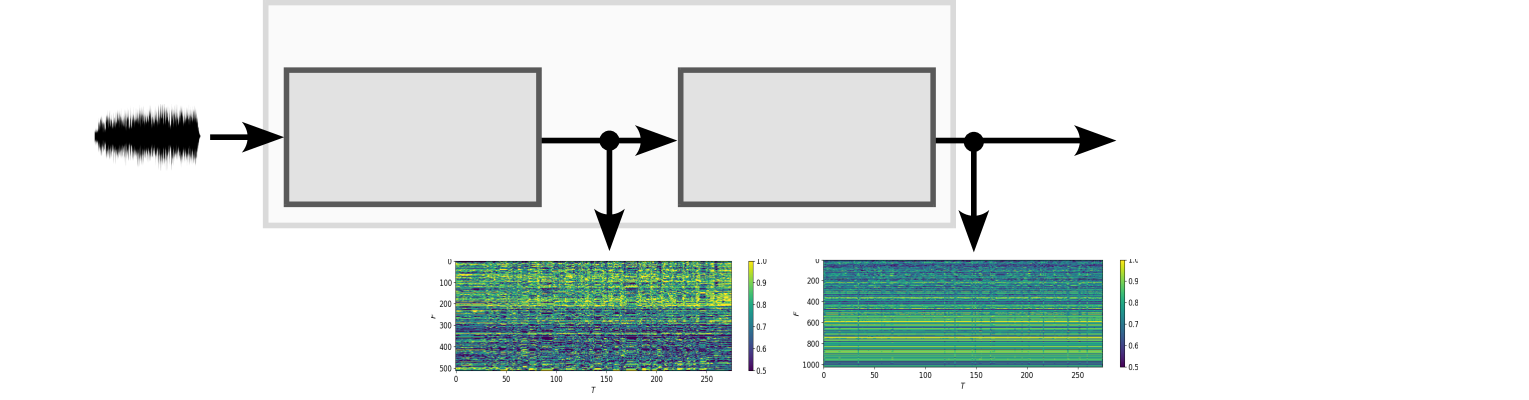
The paper examines incorporating speech foundational models, such as Personalized Speech Enhancement without Separate Speaker Embedding and Pre-training Feature-Guided Diffusion Model for Speech, into the loss functions used to train speech enhancement models for hearing aids.
The researchers hypothesized that aligning the speech enhancement model's output to the representations learned by these powerful speech foundational models would encourage the enhancement system to preserve more of the original speech characteristics, leading to better intelligibility and perceptual quality.
Various experiment designs were explored, including using the foundational models to provide perceptual guidance via loss terms that minimize the distance between the enhanced speech and the foundational model's internal representations. The paper also discusses insights gained from these approaches, such as the importance of choosing appropriate foundational models and loss function formulations to achieve the desired speech enhancement performance.
Critical Analysis
The paper provides a thoughtful exploration of leveraging advanced speech models to improve hearing aid speech enhancement. However, the authors acknowledge several caveats and limitations to their work. For example, they note that the effectiveness of the proposed approaches may depend on the specific choice of foundational model and how the loss functions are designed and implemented.
Additionally, the paper does not extensively evaluate the real-world performance and user experience of the enhanced speech, which would be an important next step to truly assess the practical benefits of this approach. Further research is needed to understand how these techniques compare to other state-of-the-art speech enhancement methods and their suitability for deployment in actual hearing aid devices.
Overall, the paper presents a promising direction for using powerful AI models to enhance speech quality for hearing aid users, but more work is required to fully validate the efficacy and generalizability of the proposed techniques.
Conclusion
This paper investigates the use of speech foundational models in the loss functions of hearing aid speech enhancement systems. By aligning the enhancement model's output to the representations learned by these sophisticated speech models, the researchers aimed to improve the preservation of natural speech characteristics, leading to better intelligibility and perceptual quality for hearing aid users.
The findings suggest that this approach holds promise, but further research is needed to fully understand its practical benefits and limitations. Incorporating user evaluations and comparisons to other state-of-the-art methods would be valuable next steps to assess the real-world impact of this technique. Overall, the work demonstrates the potential of leveraging advanced AI models to enhance speech quality for individuals with hearing impairments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Using Speech Foundational Models in Loss Functions for Hearing Aid Speech Enhancement
Robert Sutherland, George Close, Thomas Hain, Stefan Goetze, Jon Barker
Machine learning techniques are an active area of research for speech enhancement for hearing aids, with one particular focus on improving the intelligibility of a noisy speech signal. Recent work has shown that feature encodings from self-supervised speech representation models can effectively capture speech intelligibility. In this work, it is shown that the distance between self-supervised speech representations of clean and noisy speech correlates more strongly with human intelligibility ratings than other signal-based metrics. Experiments show that training a speech enhancement model using this distance as part of a loss function improves the performance over using an SNR-based loss function, demonstrated by an increase in HASPI, STOI, PESQ and SI-SNR scores. This method takes inference of a high parameter count model only at training time, meaning the speech enhancement model can remain smaller, as is required for hearing aids.
Read more7/19/2024
🗣️
0
Improving Speech Inversion Through Self-Supervised Embeddings and Enhanced Tract Variables
Ahmed Adel Attia, Yashish M. Siriwardena, Carol Espy-Wilson
The performance of deep learning models depends significantly on their capacity to encode input features efficiently and decode them into meaningful outputs. Better input and output representation has the potential to boost models' performance and generalization. In the context of acoustic-to-articulatory speech inversion (SI) systems, we study the impact of utilizing speech representations acquired via self-supervised learning (SSL) models, such as HuBERT compared to conventional acoustic features. Additionally, we investigate the incorporation of novel tract variables (TVs) through an improved geometric transformation model. By combining these two approaches, we improve the Pearson product-moment correlation (PPMC) scores which evaluate the accuracy of TV estimation of the SI system from 0.7452 to 0.8141, a 6.9% increase. Our findings underscore the profound influence of rich feature representations from SSL models and improved geometric transformations with target TVs on the enhanced functionality of SI systems.
Read more9/10/2024
0
Personalized Speech Enhancement Without a Separate Speaker Embedding Model
Tanel Parnamaa, Ando Saabas
Personalized speech enhancement (PSE) models can improve the audio quality of teleconferencing systems by adapting to the characteristics of a speaker's voice. However, most existing methods require a separate speaker embedding model to extract a vector representation of the speaker from enrollment audio, which adds complexity to the training and deployment process. We propose to use the internal representation of the PSE model itself as the speaker embedding, thereby avoiding the need for a separate model. We show that our approach performs equally well or better than the standard method of using a pre-trained speaker embedding model on noise suppression and echo cancellation tasks. Moreover, our approach surpasses the ICASSP 2023 Deep Noise Suppression Challenge winner by 0.15 in Mean Opinion Score.
Read more6/17/2024

0
Pre-training Feature Guided Diffusion Model for Speech Enhancement
Yiyuan Yang, Niki Trigoni, Andrew Markham
Speech enhancement significantly improves the clarity and intelligibility of speech in noisy environments, improving communication and listening experiences. In this paper, we introduce a novel pretraining feature-guided diffusion model tailored for efficient speech enhancement, addressing the limitations of existing discriminative and generative models. By integrating spectral features into a variational autoencoder (VAE) and leveraging pre-trained features for guidance during the reverse process, coupled with the utilization of the deterministic discrete integration method (DDIM) to streamline sampling steps, our model improves efficiency and speech enhancement quality. Demonstrating state-of-the-art results on two public datasets with different SNRs, our model outshines other baselines in efficiency and robustness. The proposed method not only optimizes performance but also enhances practical deployment capabilities, without increasing computational demands.
Read more6/13/2024