Comparative Analysis of Generative Models: Enhancing Image Synthesis with VAEs, GANs, and Stable Diffusion

0
Sign in to get full access
Overview
- Comparative analysis of generative models like Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), and Stable Diffusion
- Focuses on enhancing image synthesis capabilities across these models
- Examines the strengths, weaknesses, and tradeoffs of each approach
Plain English Explanation
This research paper provides a comparative analysis of different generative models used for image synthesis. The three main models examined are:
-
Variational Autoencoders (VAEs): These models learn to encode images into a compact latent representation and then decode that representation back into an image. They aim to capture the underlying structure and patterns in the data.
-
Generative Adversarial Networks (GANs): These models pit a generator network, which tries to produce realistic-looking images, against a discriminator network, which tries to distinguish real from fake images. The competition between the two drives the generator to produce increasingly convincing images.
-
Stable Diffusion: This is a recent text-to-image diffusion model that can generate images from textual descriptions. Diffusion models work by gradually adding noise to an image until it becomes completely random, then learning to reverse that process to generate new images.
The paper explores the strengths, weaknesses, and tradeoffs of each approach, aiming to enhance the image synthesis capabilities across these models. For example, VAEs may struggle to generate high-quality, diverse images, while GANs can be unstable and difficult to train. Stable Diffusion, on the other hand, has shown impressive results but requires significant computational resources.
By understanding the nuances of these different generative models, researchers and developers can make more informed choices about which approach to use for their specific applications and requirements.
Technical Explanation
The paper begins with an introduction to generative models and their importance in image synthesis. It then delves into a detailed technical examination of the three models:
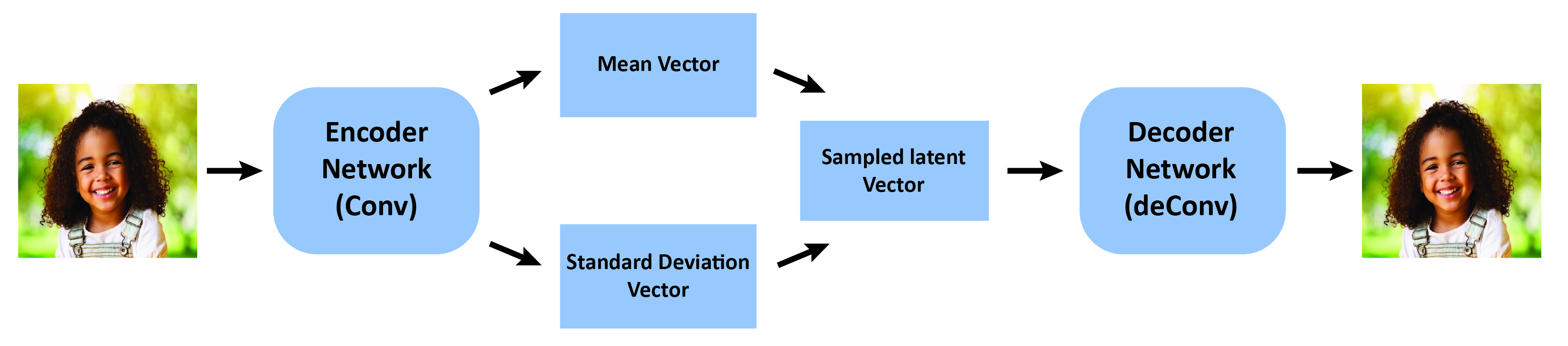
Variational Autoencoders (VAEs)
VAEs learn a probabilistic encoding of the data, capturing the underlying structure and patterns. The encoder network maps the input image to a compact latent representation, while the decoder network attempts to reconstruct the original image from this latent code. The model is trained to minimize the reconstruction error and the Kullback-Leibler divergence between the latent distribution and a prior distribution, encouraging the latent space to be well-structured.
Generative Adversarial Networks (GANs)
GANs consist of a generator network that tries to produce realistic-looking images and a discriminator network that attempts to distinguish real from fake images. The two networks are trained in a competitive manner, with the generator trying to fool the discriminator and the discriminator trying to accurately classify the generator's outputs. This adversarial training process can lead to the generation of highly realistic images, but can also be notoriously difficult to stabilize.
Stable Diffusion
Stable Diffusion is a text-to-image diffusion model that has gained significant attention for its impressive image generation capabilities. Diffusion models work by gradually adding noise to an image until it becomes completely random, then learning to reverse this process to generate new images. Stable Diffusion is built upon the Latent Diffusion architecture and is trained on a large dataset of text-image pairs, allowing it to generate images from textual descriptions.
The paper compares the performance and characteristics of these three generative models, discussing their relative strengths, weaknesses, and tradeoffs in terms of factors like image quality, diversity, training stability, and computational requirements.
Critical Analysis
The paper acknowledges several limitations and areas for further research:
-
VAE Limitations: VAEs may struggle to generate high-quality, diverse images, as their latent space can become overly constrained and the model may not be able to capture the full complexity of the data distribution.
-
GAN Challenges: GANs are notoriously difficult to train and can be unstable, with the training process often requiring careful hyperparameter tuning and the use of advanced techniques like gradient penalty and spectral normalization.
-
Computational Costs of Stable Diffusion: While Stable Diffusion has shown impressive results, it requires significant computational resources for both training and inference, which may limit its practical deployment in certain applications.
The paper also notes that further research is needed to explore hybrid or combined approaches that can leverage the strengths of multiple generative models to achieve even more powerful and versatile image synthesis capabilities.
Conclusion
This research paper provides a comprehensive comparative analysis of Variational Autoencoders, Generative Adversarial Networks, and Stable Diffusion, three prominent generative models used for image synthesis. By understanding the unique characteristics and tradeoffs of these approaches, researchers and developers can make more informed decisions about which model to use for their specific applications and requirements. The paper also highlights areas for further research to enhance the image synthesis capabilities of these models and develop even more powerful and versatile tools for generating high-quality, diverse images.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Comparative Analysis of Generative Models: Enhancing Image Synthesis with VAEs, GANs, and Stable Diffusion
Sanchayan Vivekananthan
This paper examines three major generative modelling frameworks: Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), and Stable Diffusion models. VAEs are effective at learning latent representations but frequently yield blurry results. GANs can generate realistic images but face issues such as mode collapse. Stable Diffusion models, while producing high-quality images with strong semantic coherence, are demanding in terms of computational resources. Additionally, the paper explores how incorporating Grounding DINO and Grounded SAM with Stable Diffusion improves image accuracy by utilising sophisticated segmentation and inpainting techniques. The analysis guides on selecting suitable models for various applications and highlights areas for further research.
Read more8/19/2024
0
Stable Diffusion Dataset Generation for Downstream Classification Tasks
Eugenio Lomurno, Matteo D'Oria, Matteo Matteucci
Recent advances in generative artificial intelligence have enabled the creation of high-quality synthetic data that closely mimics real-world data. This paper explores the adaptation of the Stable Diffusion 2.0 model for generating synthetic datasets, using Transfer Learning, Fine-Tuning and generation parameter optimisation techniques to improve the utility of the dataset for downstream classification tasks. We present a class-conditional version of the model that exploits a Class-Encoder and optimisation of key generation parameters. Our methodology led to synthetic datasets that, in a third of cases, produced models that outperformed those trained on real datasets.
Read more5/7/2024

0
Diffusion-Driven Semantic Communication for Generative Models with Bandwidth Constraints
Lei Guo, Wei Chen, Yuxuan Sun, Bo Ai, Nikolaos Pappas, Tony Quek
Diffusion models have been extensively utilized in AI-generated content (AIGC) in recent years, thanks to the superior generation capabilities. Combining with semantic communications, diffusion models are used for tasks such as denoising, data reconstruction, and content generation. However, existing diffusion-based generative models do not consider the stringent bandwidth limitation, which limits its application in wireless communication. This paper introduces a diffusion-driven semantic communication framework with advanced VAE-based compression for bandwidth-constrained generative model. Our designed architecture utilizes the diffusion model, where the signal transmission process through the wireless channel acts as the forward process in diffusion. To reduce bandwidth requirements, we incorporate a downsampling module and a paired upsampling module based on a variational auto-encoder with reparameterization at the receiver to ensure that the recovered features conform to the Gaussian distribution. Furthermore, we derive the loss function for our proposed system and evaluate its performance through comprehensive experiments. Our experimental results demonstrate significant improvements in pixel-level metrics such as peak signal to noise ratio (PSNR) and semantic metrics like learned perceptual image patch similarity (LPIPS). These enhancements are more profound regarding the compression rates and SNR compared to deep joint source-channel coding (DJSCC).
Read more7/29/2024

0
Structured Generations: Using Hierarchical Clusters to guide Diffusion Models
Jorge da Silva Goncalves, Laura Manduchi, Moritz Vandenhirtz, Julia E. Vogt
This paper introduces Diffuse-TreeVAE, a deep generative model that integrates hierarchical clustering into the framework of Denoising Diffusion Probabilistic Models (DDPMs). The proposed approach generates new images by sampling from a root embedding of a learned latent tree VAE-based structure, it then propagates through hierarchical paths, and utilizes a second-stage DDPM to refine and generate distinct, high-quality images for each data cluster. The result is a model that not only improves image clarity but also ensures that the generated samples are representative of their respective clusters, addressing the limitations of previous VAE-based methods and advancing the state of clustering-based generative modeling.
Read more7/15/2024